
Checkout the code and super detailed video walkthrough!
Code: github.com/huggingface/...
Video: youtube.com/playlist?lis...
Work lead by Haojun Zhao and Ferdinand Mom!
Checkout the code and super detailed video walkthrough!
Code: github.com/huggingface/...
Video: youtube.com/playlist?lis...
Work lead by Haojun Zhao and Ferdinand Mom!
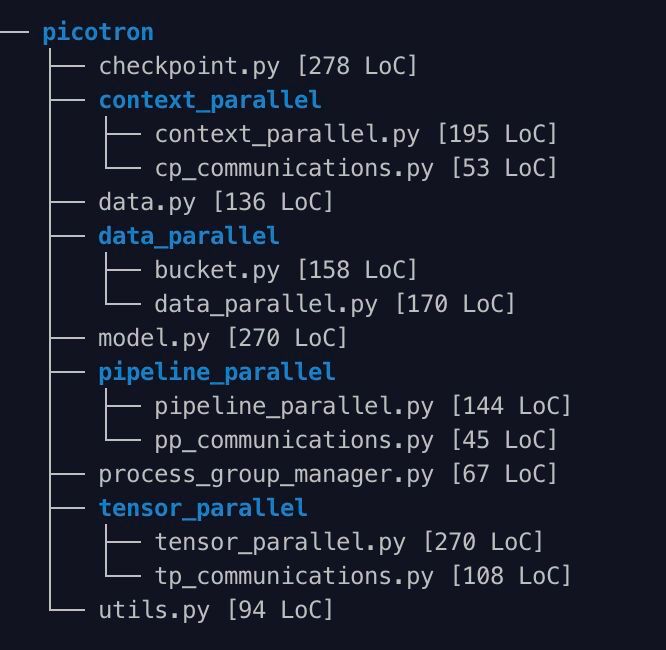
Distributed training is notoriously hard to learn - knowledge is scattered across papers and complex codebases.
Enter picotron: implementing all 4D parallelism concepts in separate, readable files totaling just 1988 LoC!

thumbnail that says introducing smolagents
supercharge your LLM apps with smolagents 🔥
however cool your LLM is, without being agentic it can only go so far
enter smolagents: a new agent library by @hf.co to make the LLM write code, do analysis and automate boring stuff! huggingface.co/blog/smolage...

A plot showing increased performance of Llama-3.2-3B when pretrained on FineMath
Introducing 📐FineMath: the best open math pre-training dataset with 50B+ tokens!
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
Or watch how the model solves the Lokta-Volterra equation and plots the results and refines them.
Try it out: huggingface.co/spaces/data-...
Releasing Jupyter Agents - LLMs running data analysis directly in a notebook!
The agent can load data, execute code, plot results and following your guidance and ideas!
A very natural way to collaborate with an LLM over data and it's just scratching the surface of what's possible soon!

We outperform Llama 70B with Llama 3B on hard math by scaling test-time compute 🔥
How? By combining step-wise reward models with tree search algorithms :)
We're open sourcing the full recipe and sharing a detailed blog post 👇
💔
14.12.2024 20:12 — 👍 0 🔁 0 💬 0 📌 0
Big News in AI4Science! ✨
We are thrilled to launch LeMaterial, an open-source project in collaboration with @hf.co to accelerate materials discovery ⚛️🤗
Discover LeMat-Bulk: a 6.7M-entry dataset standardizing and unifying Materials Project, Alexandria and OQMD

Announcing 🥂 FineWeb2: A sparkling update with 1000s of 🗣️languages.
We applied the same data-driven approach that led to SOTA English performance in🍷 FineWeb to thousands of languages.
🥂 FineWeb2 has 8TB of compressed text data and outperforms other datasets.

The FineWeb team is happy to finally release "FineWeb2" 🥂🥳
FineWeb 2 extends the data driven approach to pre-training dataset design that was introduced in FineWeb 1 to now covers 1893 languages/scripts
Details: huggingface.co/datasets/Hug...
A detailed open-science tech report is coming soon
There are not many opportunities out there to build open LLMs and make them state-of-the-art, too! This is one of them.
28.11.2024 09:42 — 👍 16 🔁 1 💬 0 📌 0
WOW! 🤯 Language models are becoming smaller and more capable than ever! Here's SmolLM2 running 100% locally in-browser w/ WebGPU on a 6-year-old GPU. Just look at that speed! ⚡️😍
Powered by 🤗 Transformers.js and ONNX Runtime Web!
How many tokens/second do you get? Let me know! 👇
Some people are pushing models to the top right of the plot following the scaling laws, others push them to the top left and make them faster and cheaper!
We need both!

A screenshot of LightEval benchmarking results in a terminal
Check out how easy it is to do LLM evals with LightEval!
* any dataset on the 🤗 Hub can become an eval task in a few lines of code: customize the prompt, metrics, parsing, few-shots, everything!
* model- and data-parallel inference
* auto batching with the new vLLM backend

It's Sunday morning so taking a minute for a nerdy thread (on math, tokenizers and LLMs) of the work of our intern Garreth
By adding a few lines of code to the base Llama 3 tokenizer, he got a free boost in arithmetic performance 😮
[thread]
Looks more like a rave!
22.11.2024 09:20 — 👍 1 🔁 0 💬 1 📌 0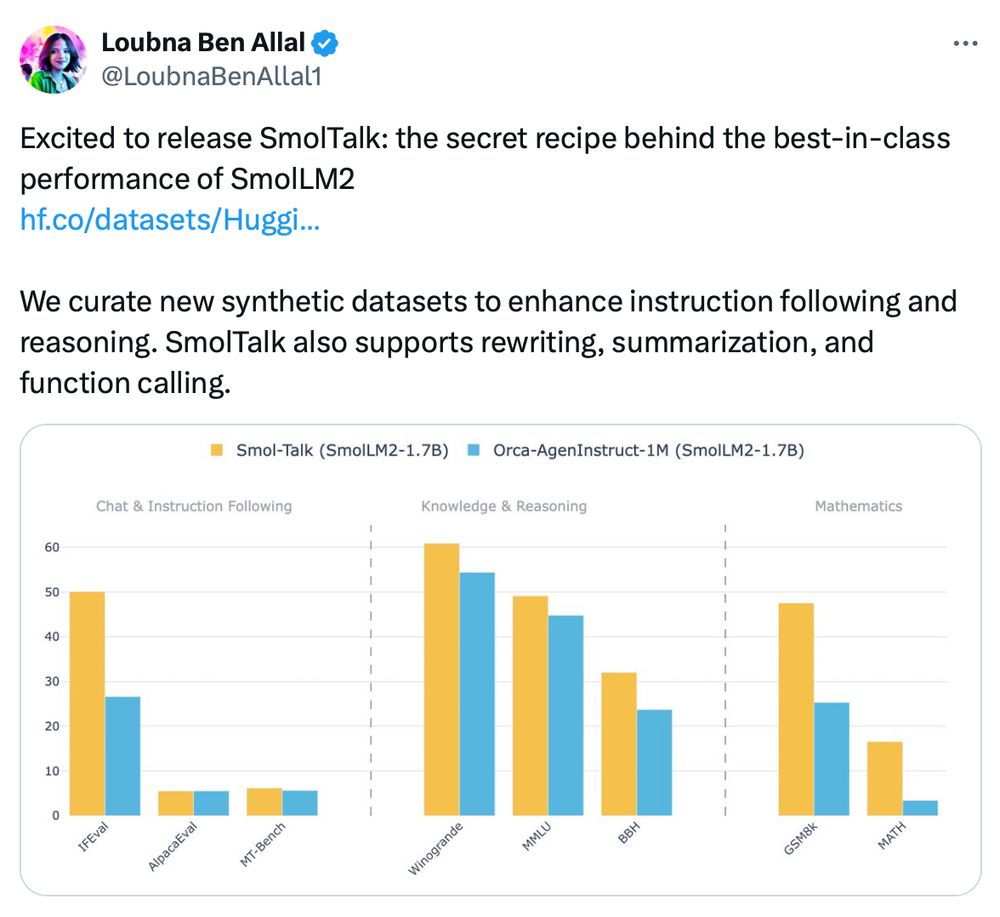
What's the secret sauce of SmolLM2 to beat LLM titans like Llama3.2 and Qwen2.5?
Unsurprisingly: data, data, data!
The SmolTalk is open and available here: huggingface.co/datasets/Hug...

Slides here: docs.google.com/presentation...
Inspired by the nice talk from @thomwolf.bsky.social earlier this year and updated with some material we are working on right now:
www.youtube.com/watch?v=2-SP...
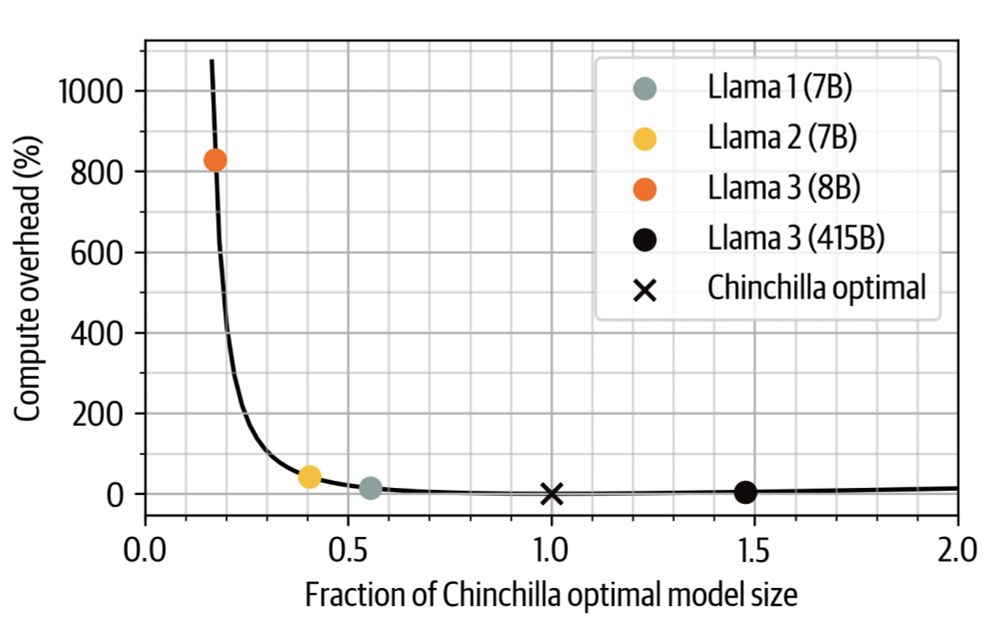
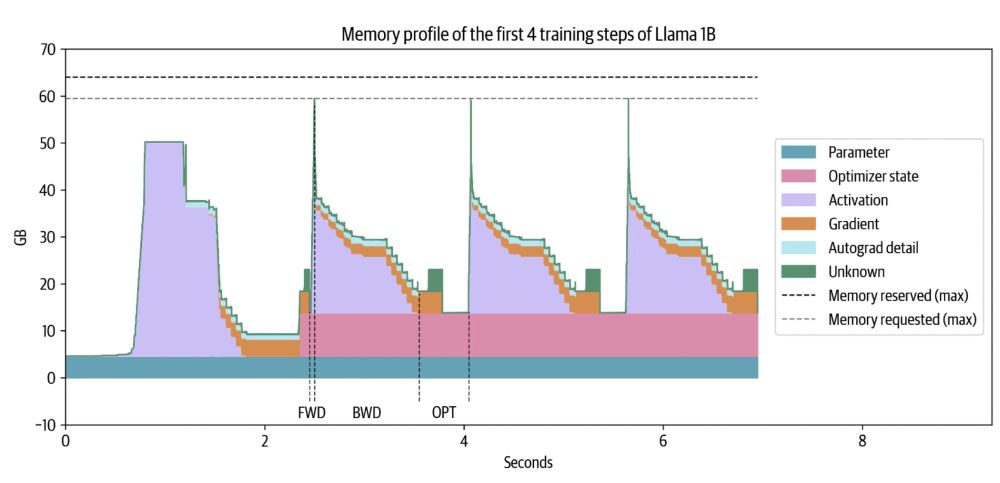
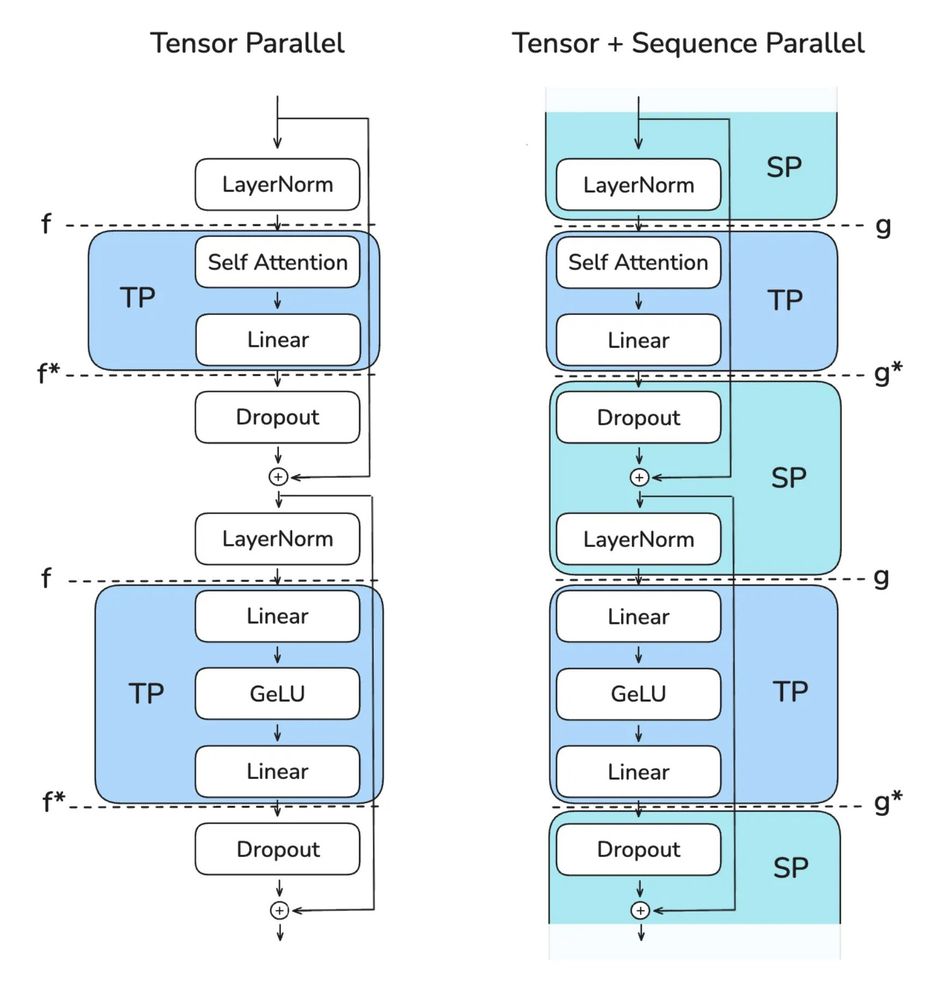
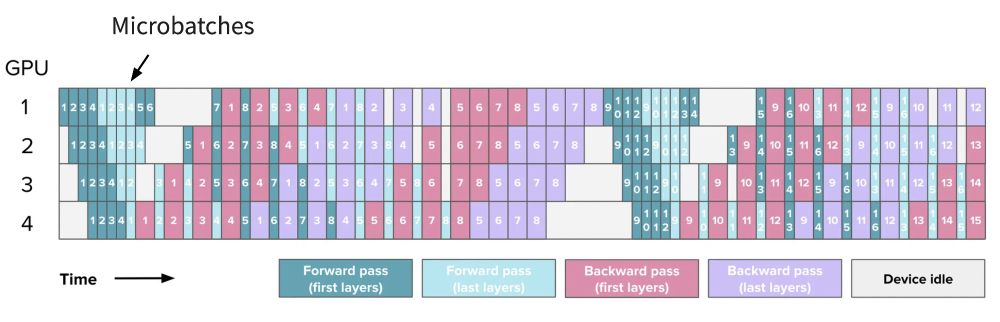
All the things you need to know to pretrain an LLM at home*!
Gave a workshop at Uni Bern: starts with scaling laws and goes to web scale data processing and finishes training with 4D parallelism and ZeRO.
*assuming your home includes an H100 cluster


