1/ NEW R PACKAGE! For estimating the impact of potential interventions on multiple mediators in countering exposure effects (led by @cttc101.bsky.social)
- Paper👉 tinyurl.com/ye26jsps
- Package👉 tinyurl.com/yuh4kens
Thread shows published examples of how the method can be used! #EpiSky #CausalSky
10.07.2025 01:30 — 👍 30 🔁 12 💬 1 📌 2
🚨 Funded PhD opportunity 🚨 Work with large-scale electronic health record data from #OpenSAFELY to optimise vaccine effectiveness estimation for respiratory viruses.
Apply here 👉 www.findaphd.com/phds/project...
04.07.2025 09:39 — 👍 2 🔁 3 💬 1 📌 0
Just adding "The meta-analyst decides that the accumulated evidence is in fact a pileup." as an additional favourite
14.05.2025 14:40 — 👍 2 🔁 0 💬 1 📌 0
Congratulations Viktor!!
27.03.2025 15:53 — 👍 1 🔁 0 💬 1 📌 0
It’s my understanding that with the parametric g-formula you use the outcome model to predict the outcome for each subject, independently of whether they are censored. And you take its mean considering ALL N subjects. If the pot. outcome has some NA, I’d still sum and divide by N.
Stupid question:
24.03.2025 18:26 — 👍 0 🔁 1 💬 1 📌 0
I'm even less convinced by these certificates now
bsky.app/profile/bkle...
19.03.2025 15:32 — 👍 2 🔁 0 💬 1 📌 0
New publication led by @proflouisemarston.bsky.social using multiple imputation to target a hypothetical estimand in a pandemic restriction-free world for a trial in
schizophrenia - demonstrating the potential impact of the pandemic on the trial results
18.03.2025 08:27 — 👍 8 🔁 6 💬 1 📌 0
OSF
There's already been a very interesting preprint commentary on our paper by Maya Mathur and Ilya Shpitser which I highly recommend people take a look at :
osf.io/preprints/os...
19.02.2025 10:32 — 👍 0 🔁 0 💬 0 📌 0
Conclusions:
- Use auxiliary variables that are completely observed, or have smaller amounts of missing data
- Explore the missing data mechanisms of incomplete auxiliary variables
- Aim to use auxiliary variables that are independent of their own missingness.
19.02.2025 10:25 — 👍 0 🔁 0 💬 1 📌 0
"Bias was larger when the auxiliary had a stronger correlation with the outcome...In terms of absolute bias in the MI estimate, this equates to around ... 17% of the true effect size." We would tend to treat such an auxiliary as preferable, but we need to show caution when it has missing data in it
19.02.2025 10:25 — 👍 0 🔁 0 💬 1 📌 0
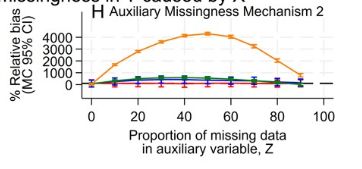
Subsection from Figure 2 of the paper. The image shows a plot with relative bias on the Y axis, and the proportion of missing data in the auxiliary variable on the Z axis. Four coloured lines are on the plot representing different correlations between the outcome and the auxiliary variable. This plot, plot H, displays results for an example where the missingness mechanism for the outcome leads to an unbiased estimate of an exposure outcome
The most striking finding to me was that when there was no bias in CRA (and we are using MI to reduce SEs only), including an auxiliary variable with an open path to its own missing data can introduce substantial quantities of bias.
19.02.2025 10:25 — 👍 0 🔁 0 💬 1 📌 0
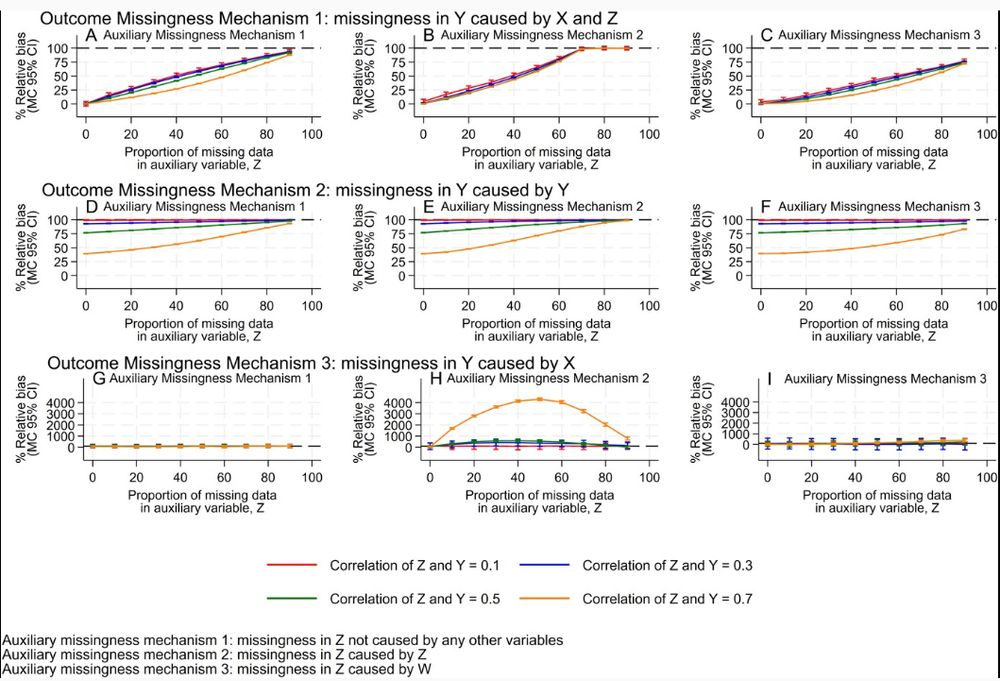
We looked at different missing data mechanisms for both an outcome and an auxiliary variable.
Where the outcome missingness mechanism led to a biased complete records analysis, increasing proportions of missing data reduced the ability of auxiliary variables to remove bias.
19.02.2025 10:25 — 👍 0 🔁 0 💬 1 📌 0
But what happens when those auxiliary variables have missing data in them?
We didn't know what consequence including incomplete auxiliary variables has on bias of exposure-outcome estimates made using regression models - so we did some simulating.
19.02.2025 10:25 — 👍 0 🔁 0 💬 1 📌 0
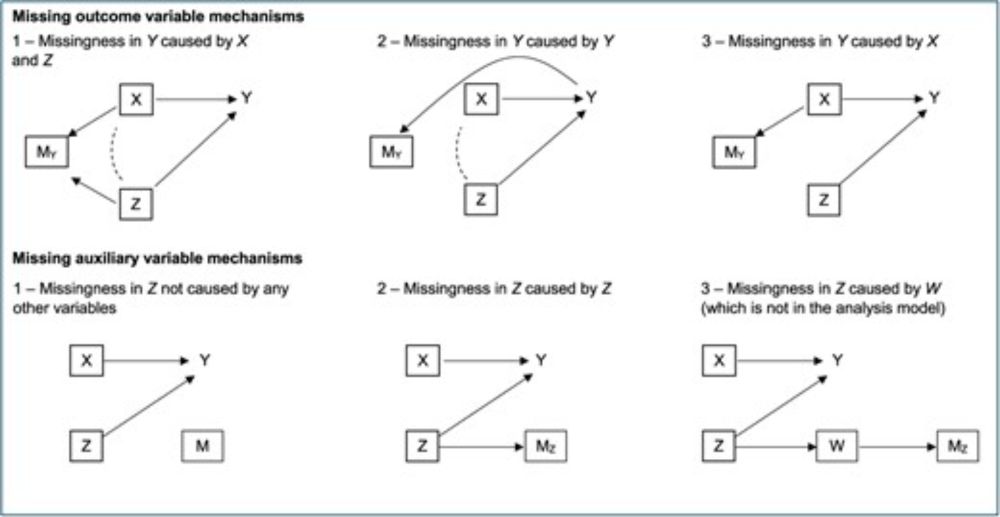
Analyses using multiple imputation need to consider missing data in auxiliary variables
Abstract. Auxiliary variables are used in multiple imputation (MI) to reduce bias and increase efficiency. These variables may often themselves be incomple
Final version published so time to talk about it: doi.org/10.1093/aje/...
When using multiple imputation to account for missing data we often use auxiliary variables (variables included in the imputation model but not the analysis model) to 1) reduce bias and 2) improve statistical efficiency.
19.02.2025 10:25 — 👍 5 🔁 1 💬 1 📌 1
Work by @ahlqvistviktor.bsky.social @draipsych.bsky.social @karolinskainst.bsky.social @aarhusuni.bsky.social
@neilmdavies.bsky.social @danielberglind.bsky.social ... and many more... @natureportfolio.bsky.social
21.11.2024 10:46 — 👍 1 🔁 0 💬 0 📌 0
The phrase 200% higher looks a lot more alarming than twice the risk of 0.9%.
This is nothing new in the area of risk communication - but today it has annoyed me
21.11.2024 10:43 — 👍 2 🔁 0 💬 1 📌 0
I think there is an issue with people communicating relative risk, they often use language relating to risk difference (i.e. X% higher risk). They’re not wrong but I feel that people should be using phrases like twice the risk instead of 200% higher risk.
21.11.2024 10:43 — 👍 0 🔁 0 💬 1 📌 0
- At 12 years of age, the children of unexposed mothers had a ... 0.9% risk of intellectual disability ...
- With intellectual disability ... polytherapy was associated with a risk of 1.8%.
- Taken together, the risk of intellectual disability was ... 200% higher with polytherapy
21.11.2024 10:42 — 👍 0 🔁 0 💬 1 📌 0
In our latest work we investigated the effect of antiseizure medication prescribing/dispensation in pregnancy on offspring neurodevelopmental outcomes using over 3 million pregnancies from the UK and Sweden. Article out now in Nature Comms: nature.com/articles/s41...
21.11.2024 10:37 — 👍 11 🔁 3 💬 1 📌 0
We will be covering multiple imputation methods to address
1) where data are missing not at random
2) imputation for multilevel models
3) imputation for survival models, and
4) imputation for propensity score analysis
07.10.2024 10:06 — 👍 1 🔁 0 💬 0 📌 0
Research Fellow at the University of Bristol. My research interests are in mental health, autism and health behaviours, primarily using epidemiological approaches.
#Researcher #PhD Candidate in Psycho Nuero Immunology #Nurse# Cadiology
Researcher @ SGDP Centre, KCL. Research interests in genomics, epidemiology, psychiatry, psychology, mental health
PhD student. Epidemiology, Causal Inference, Physical activity, and COPD
Professor of Epidemiology Harvard Chan SPH, Director, @ccdd-hsph.bsky.social. Views my own.
Psychologist at University of Oxford | Adolescence + mental health
Linktr.ee/lucyfoulkes
Associate Prof of Psychology. I study how you remember (episodic memory), but am also interested in other areas of science (astronomy, geology, astrophysics, paleobiology, ecology, meteorology, etc) and other things too (architecture, birds, transit, etc).
Cognitive neuroscientist with many interests, including why our stomachs churn when we feel disgust. I also write books on programming; teach Python, statistics, and machine learning; and develop open-source software.
https://www.dalmaijer.org
All about Statistical Methods in Clinical Trials and Good Statistical Practice in Healthcare Research at Imperial Clinical Trials Unit (ICTU), Imperial College London #StatsCI
www.statsci.co.uk
Statistical consultant and programmer at Harvard IQSS. Author/maintainer of the #Rstats packages 'MatchIt', 'WeightIt', and 'cobalt' for causal inference, among many others | He/him
ngreifer.github.io
Social epidemiologist researching inequalities in mental health, body weight, and the role of stigma at @uob-ieu.bsky.social. Lover of cinema and mountains. Views my own. https://research-information.bris.ac.uk/en/persons/amanda-m-m-hughes/
Professor of Genetic Epidemiology, University of Bristol at: uob-ieu@bsky.social
Epidemiologist, Bennett Institute, Oxford
biostatistics phd prev. @UCL @Penn @UNC @NCSSM
Professor of Biostatistics. University of Melbourne & Murdoch Children’s Research Institute. Research in causal inference and missing data methods + child, lifecourse and social epidemiology
Postdoc in psychiatric genetics and clinical psychologist at University Hospital Bonn | PhD @ucl.ac.uk | Within-family analyses, statistical genetics, polygenic scores, behaviour genetics, epigenetics | he/him
Psychiatric epidemiologist and public mental health researcher. Principle Research Fellow / Associate Professor @UCL Division of Psychiatry
www.mentalhealthepi.com
Dementia Community is a Charitable Community Benefit Society, a membership cooperative that provides learning and networking opportunities for the dementia care community. For more information please visit our website: journalofdementiacare.co.uk






















