
"Designed by Jr.Mars
Inspired by the sleek and elegant Light Mode of Apple's MacOS system, bring a touch of classic nostalgia to your keyboard."
keyreative.store/products/kap...

@ota.bsky.social
Interests: Reinforcement Learning, Natural Language Processing and Artificial General Intelligence. arXiv papers bot: @paper.bsky.social
"Designed by Jr.Mars
Inspired by the sleek and elegant Light Mode of Apple's MacOS system, bring a touch of classic nostalgia to your keyboard."
keyreative.store/products/kap...
How to burn firmware to the Swagkeys Eave65
1. Install dfu-util
2. Plug in the USB-C cable
3. Press the reset button on the back of the PCB
4. Run `dfu-util -l`. It should show 3 targets (alt=0, 1, 2)
5. Run `dfu-util -d 1eaf:0003 -a 2 -D eave65.bin` (alt=2)
6. Unplug and plug the USB-C cable

While the ``deep reasoning'' paradigm has spurred significant advances in verifiable domains like mathematics, its application to open-ended, creative generation remains a critical challenge. The two dominant methods for instilling reasoning -- reinforcement learning (RL) and instruction distillation -- falter in this area; RL struggles with the absence of clear reward signals and high-quality reward models, while distillation is prohibitively expensive and capped by the teacher model's capabilities. To overcome these limitations, we introduce REverse-Engineered Reasoning (REER), a new paradigm that fundamentally shifts the approach. Instead of building a reasoning process ``forwards'' through trial-and-error or imitation, REER works ``backwards'' from known-good solutions to computationally discover the latent, step-by-step deep reasoning process that could have produced them. Using this scalable, gradient-free approach, we curate and open-source DeepWriting-20K, a large-scale dataset of 20,000 deep reasoning trajectories for open-ended tasks. Our model, DeepWriter-8B, trained on this data, not only surpasses strong open-source baselines but also achieves performance competitive with, and at times superior to, leading proprietary models like GPT-4o and Claude 3.5.
[30/30] 198 Likes, 6 Comments, 3 Posts
2509.06160, cs․AI | cs․CL, 07 Sep 2025
🆕Reverse-Engineered Reasoning for Open-Ended Generation
Haozhe Wang, Haoran Que, Qixin Xu, Minghao Liu, Wangchunshu Zhou, Jiazhan Feng, Wanjun Zhong, Wei Ye, Tong Yang, Wenhao Huang, Ge Zhang, Fangzhen Lin

"chat.fontSize" and "chat.fontFamily" for GitHub Copilot Chat.
github.com/microsoft/vs...
GRPO for gpt-oss-20b with verl and sglang
github.com/volcengine/v...
A useful table to convert Slurm scripts to ABCI (PBS) and TSUBAME (SGE/AGE).
"This table lists the most common command, environment variables, and job specification options used by the major workload management systems: PBS/Torque, Slurm, LSF, SGE and LoadLeveler."
slurm.schedmd.com/rosetta.html

"Unsloth gpt-oss fine-tuning is 1.5x faster, uses 70% less VRAM, and supports 10x longer context lengths. gpt-oss-20b LoRA training fits on a 14GB VRAM, and gpt-oss-120b works on 65GB VRAM."
docs.unsloth.ai/basics/gpt-o...
"Collection of scripts demonstrating different optimization and fine-tuning techniques for OpenAI's GPT-OSS models (20B and 120B parameters).
...
For full-parameter training on one node of 8 GPUs, ..."
github.com/huggingface/...

"The Agar Mini is available in two distinct versions ...
Wired Edition: Powered by QMK firmware, ... is fully compatible with VIA, VIAL, ...
Dual-Mode Wireless Edition: Built on ZMK firmware, ... is fully customizable via the zmk.studio editor."
kbdfans.com/products/aga...

My notes on Gemini CLI, including poking around in their system prompt which I've extracted into a more readable rendered Gist simonwillison.net/2025/Jun/25/...
25.06.2025 17:55 — 👍 81 🔁 10 💬 5 📌 1
The "secret project" I've been working on at my job has gone public (and open source) today! Check it out!
25.06.2025 15:36 — 👍 4 🔁 1 💬 0 📌 0Since I had already used the Gemini API, I had to unset the GEMINI_API_KEY in order to authenticate with my Google account.
GEMINI_API_KEY="" gemini
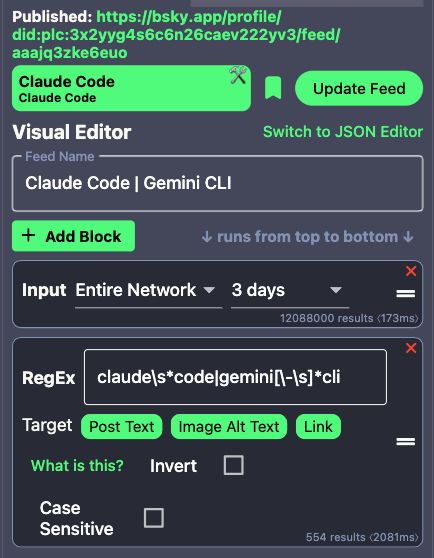
Skyfeed settings for the Claude Code | Gemini CLI feed.
I expanded the Claude code feed to include the Gemini CLI.
bsky.app/profile/did:...
bsky.app/profile/did:...
This feed will be moved to
bsky.app/profile/did:...
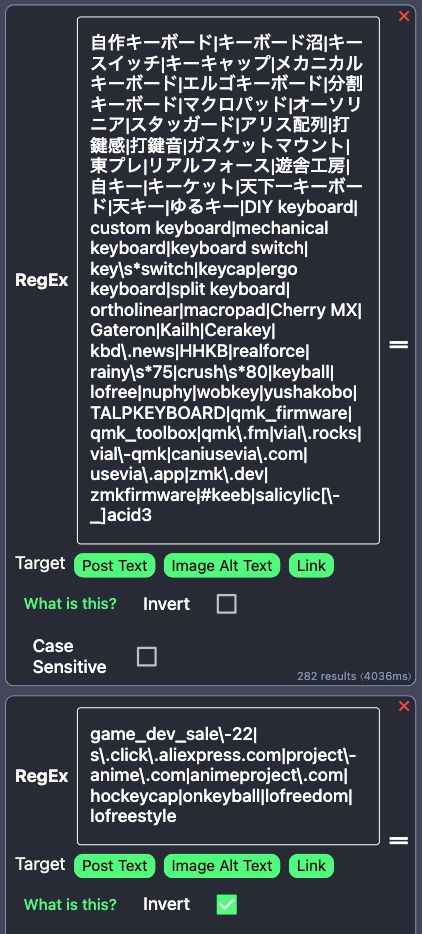
RegEx patterns for Custom Keyboard feed.
RegEx patterns for Custom Keyboard feed.
23.06.2025 10:51 — 👍 0 🔁 0 💬 0 📌 0Posts related to custom keyboard, DIY keyboard, mechanical keyboard, key switch, keycap, etc.
自作キーボード, キースイッチ, キーキャップなどを含むポスト.
bsky.app/profile/did:...
Posts related to `Claude Code`.
Claude Code を含むポスト。
bsky.app/profile/did:...
Jupyter Notebookと生成AIの組み合わせ、あると思います。チャット用のサイドウィンドウを表示したり、%%aiでNotebookの中から生成AIに問い合わせできたり。各種AI利用の他、Ollamaなどにも対応してるのでローカルLLMも利用可。
01.06.2025 06:59 — 👍 2 🔁 1 💬 0 📌 0Thanks! I fixed the feeds.
08.05.2025 18:11 — 👍 0 🔁 0 💬 0 📌 0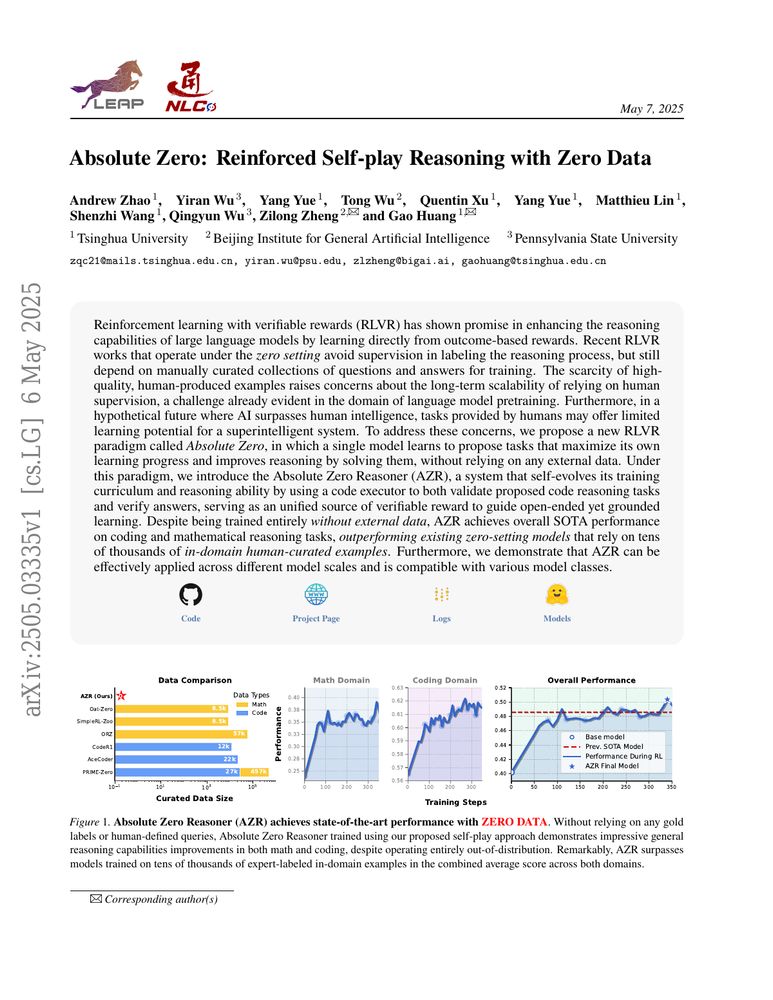
Reinforcement learning with verifiable rewards (RLVR) has shown promise in enhancing the reasoning capabilities of large language models by learning directly from outcome-based rewards. Recent RLVR works that operate under the zero setting avoid supervision in labeling the reasoning process, but still depend on manually curated collections of questions and answers for training. The scarcity of high-quality, human-produced examples raises concerns about the long-term scalability of relying on human supervision, a challenge already evident in the domain of language model pretraining. Furthermore, in a hypothetical future where AI surpasses human intelligence, tasks provided by humans may offer limited learning potential for a superintelligent system. To address these concerns, we propose a new RLVR paradigm called Absolute Zero, in which a single model learns to propose tasks that maximize its own learning progress and improves reasoning by solving them, without relying on any external data. Under this paradigm, we introduce the Absolute Zero Reasoner (AZR), a system that self-evolves its training curriculum and reasoning ability by using a code executor to both validate proposed code reasoning tasks and verify answers, serving as an unified source of verifiable reward to guide open-ended yet grounded learning. Despite being trained entirely without external data, AZR achieves overall SOTA performance on coding and mathematical reasoning tasks, outperforming existing zero-setting models that rely on tens of thousands of in-domain human-curated examples. Furthermore, we demonstrate that AZR can be effectively applied across different model scales and is compatible with various model classes.
[5/30] 396 Likes, 96 Comments, 4 Posts
2505.03335, cs․LG | cs․AI | cs․CL, 06 May 2025
🆕Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Yang Yue, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, Gao Huang
"Write Karabiner-Elements configuration in TypeScript. ... Easier-to-understand TypeScript/JavaScript syntax, Strong-typed abstractions and key aliases with IDE support, Structured config files instead of one big file"
github.com/evan-liu/kar...
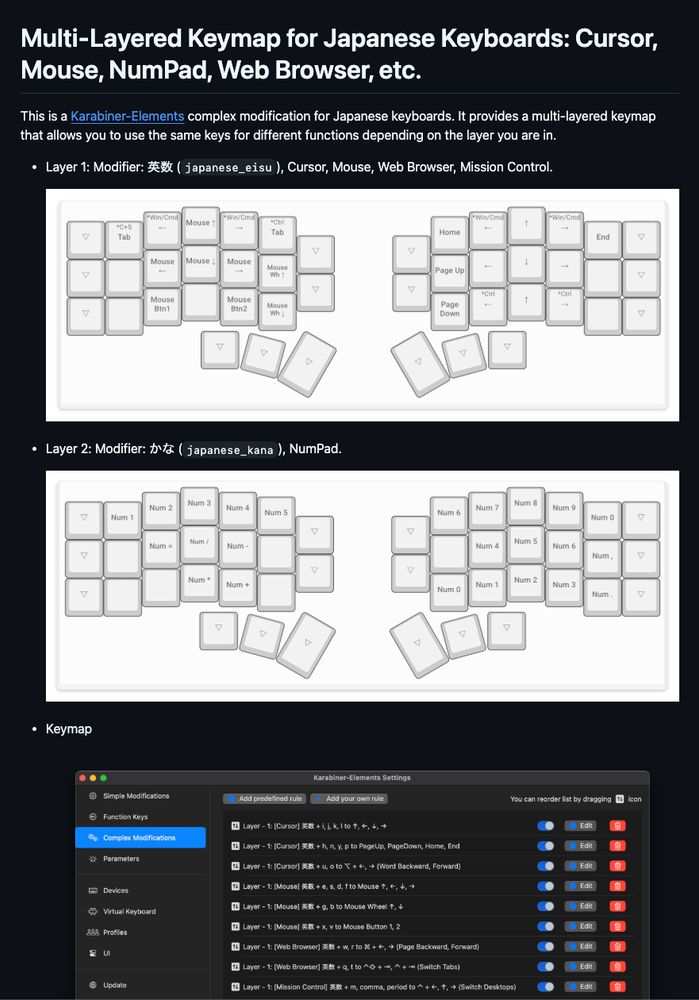
Screenshot of layers and keymap.
Karabiner-Elements でマルチレイヤのキーマップを作った。karabiner.ts というライブラリを使ったらレイヤーが簡単に実装できた!
layer('japanese_eisuu', '英数 + ijkl').manipulators([
map('i').to('↑'),
map('j').to('←'),
map('k').to('↓'),
map('l').to('→'),
]),
それと久しぶりに Deno を使ってみたが、こういう簡単なプログラムならかなり楽。
github.com/susumuota/ka...
"By serving as an intermediary in user interactions, it can autonomously generate context-aware responses, prefill required information, and facilitate seamless communication with external systems, significantly reducing cognitive load and interaction friction."
11.04.2025 02:57 — 👍 0 🔁 0 💬 0 📌 0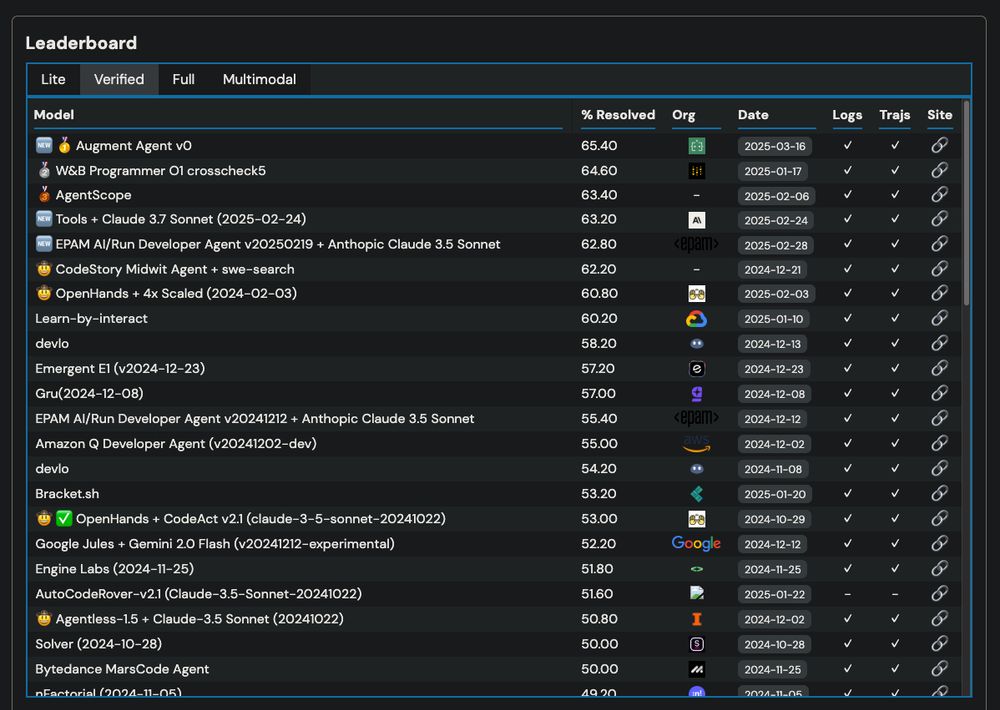
Results of SWE-bench Verified at 2025-04-07.
SWE-bench Verified 56.0% は 2024-12 頃のモデルとコンパラブル。
www.swebench.com#verified

"Visual Studio Codeのエージェントモードを全ユーザーに提供します。このモードはMCPをサポートしており、必要なあらゆるコンテキストや機能へのアクセスを可能にします。... エージェントモードのモデルは、Claude 3.5と3.7 Sonnet、Google Gemini 2.0 Flash、OpenAI GPT-4oから選択できます。現在、エージェントモードはClaude 3.7 Sonnetを使用した場合、SWE-bench Verifiedで56.0%の合格率を達成しています。"
github.blog/jp/2025-04-0...
"... the word “writing” no longer refers to this physical act but the higher abstraction of arranging ideas into a readable format. Similarly, once the physical act of coding can be automated, the meaning of “programming” will change to refer to the act of arranging ideas into executable programs."
07.04.2025 08:06 — 👍 0 🔁 0 💬 0 📌 0
"... if a task can only be done by a handful of those most educated, that task is considered intellectual. One example is writing, the physical act of copying words onto paper. In the past, when only a small portion of the population was literate, writing was considered intellectual."
07.04.2025 08:05 — 👍 1 🔁 0 💬 1 📌 0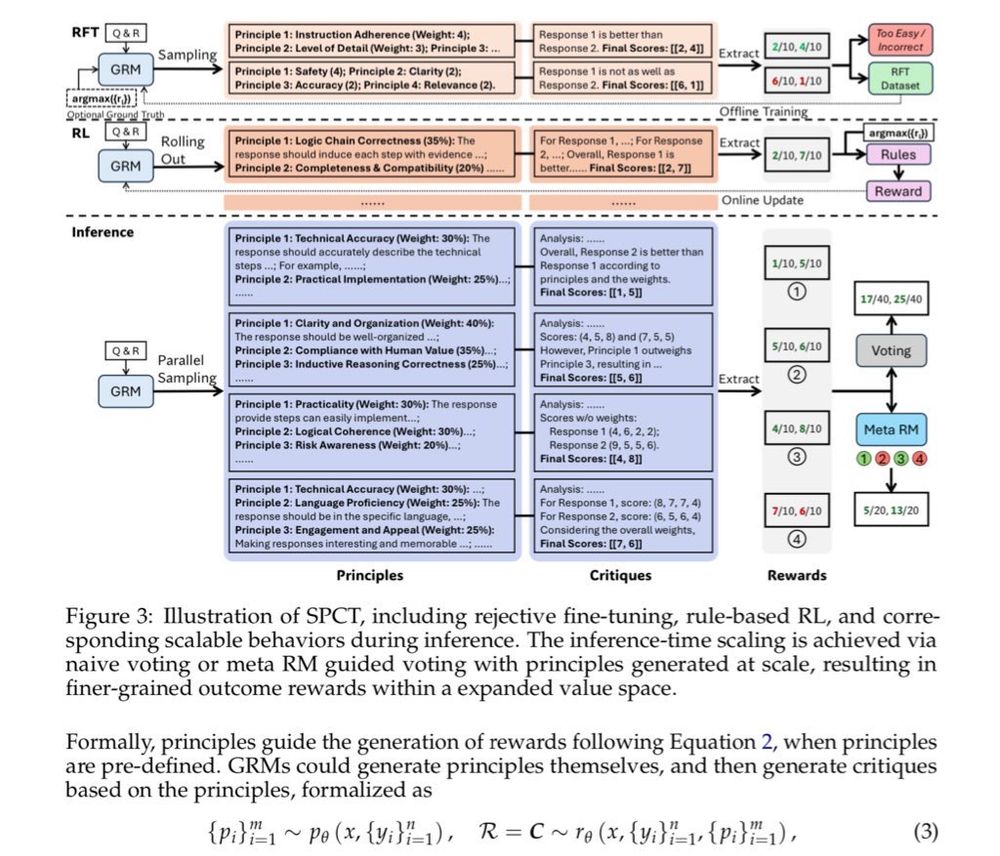
Well the latest DeepSeek is very satisfying from an humanities perspective. The trick to generalize RL is replacing scalar grades with… source criticism (qualitative principles and critiques). arxiv.org/pdf/2504.02495
04.04.2025 08:01 — 👍 44 🔁 5 💬 0 📌 2"A key challenge of RL is to obtain accurate reward signals for LLMs in various domains beyond verifiable questions or artificial rules. ... we investigate how to improve reward modeling (RM) with more inference compute for general queries, i.e. the inference-time scalability of generalist RM"
05.04.2025 04:05 — 👍 0 🔁 0 💬 0 📌 0
image alt text can be 2000 characters long.
I just realised that image alt text can be 2000 characters long.
I have fixed @paper.bsky.social to allow 2000 chars.


















