Interesting. Is this because they have govt contracts and those would be jeopardized? Or uncertainty around whether those models will be banned for use in America, which adds a huge risk premium?
05.05.2025 16:51 — 👍 0 🔁 0 💬 1 📌 0
for all methods, it is better for data to be on-policy and be labelled as good/bad relative to the current state of the policy.
but ultimately this is a learning dynamics problem that transcends how the data is sampled
19.12.2024 20:27 — 👍 2 🔁 0 💬 1 📌 0
unpaired methods work the way we hope paired methods would, simultaneously increasing the relative prob of good outputs and decreasing the relative prob of bad outputs. this allows you to skip SFT entirely
19.12.2024 20:25 — 👍 2 🔁 0 💬 1 📌 0
it's not really on vs. off-policy. in theory, paired methods should increase the prob of good outputs, decrease prob of bad outputs. in practice, they decrease *both*. you need to do SFT beforehand so that you can pay this price and hope that relative to the base model, p(good|x) is still higher
19.12.2024 20:23 — 👍 0 🔁 0 💬 1 📌 0
all paired preference methods suffer from this problem while also being more inflexible. unpaired preference methods are always the way to go IME
19.12.2024 18:02 — 👍 1 🔁 0 💬 1 📌 0
Source: old.reddit.com/r/LocalLLaMA...
26.11.2024 23:35 — 👍 1 🔁 0 💬 0 📌 0
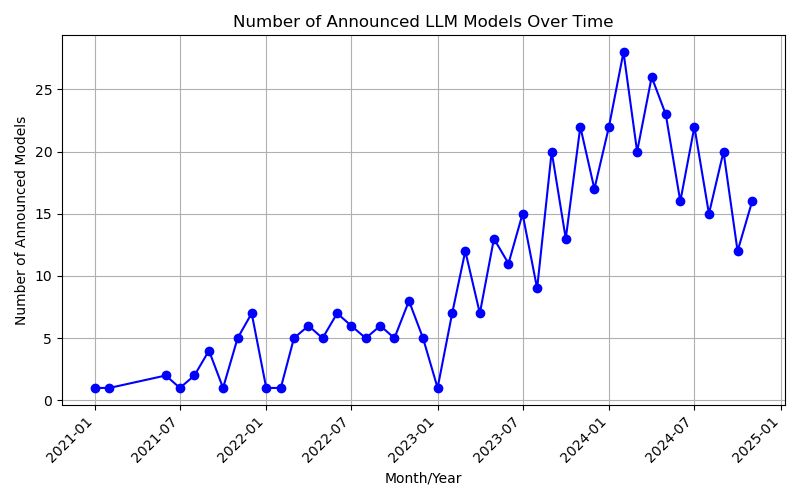
🤔
26.11.2024 23:35 — 👍 16 🔁 2 💬 4 📌 0

Evolution of Preference Optimization Techniques | Hippocampus's Garden
RLHF is not the only method for AI alignment. This article introduces modern algorithms like DPO and KTO that offer simpler and more stable alternatives.
RLHF is not the only method for AI alignment. This post introduces modern algorithms like DPO, KTO, and DiscoPOP that offer simpler and more stable alternatives.
Evolution of Preference Optimization Techniques | Hippocampus's Garden
hippocampus-garden.com/preference_o...
24.11.2024 15:13 — 👍 6 🔁 1 💬 0 📌 0

Reference-Based Metrics Are Biased Against Blind and Low-Vision Users’ Image Description Preferences
Rhea Kapur, Elisa Kreiss. Proceedings of the Third Workshop on NLP for Positive Impact. 2024.
I'm excited to kick off my Bluesky presence with wonderful news: Our paper "Reference-Based Metrics Are Biased Against Blind and Low-Vision Users' Image Description Preferences" won a Best Paper Award at the NLP for Positive Impact Workshop at EMNLP! Read it here: aclanthology.org/2024.nlp4pi-...
24.11.2024 18:39 — 👍 193 🔁 20 💬 4 📌 2
nominating myself @kawinethayarajh.bsky.social
21.11.2024 19:02 — 👍 1 🔁 0 💬 1 📌 0
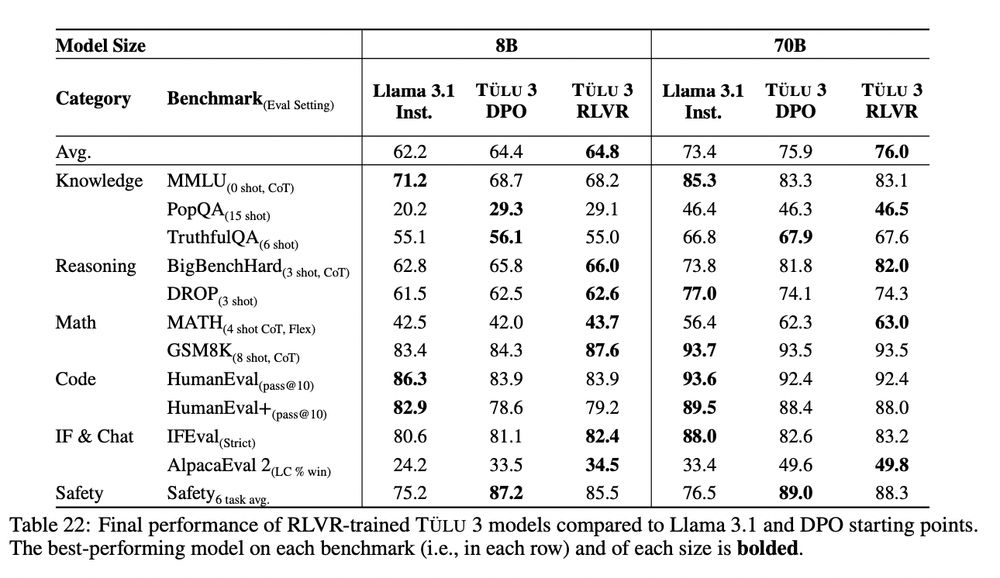
These differences with the DPO version don't seem statistically significant?
21.11.2024 18:39 — 👍 1 🔁 0 💬 1 📌 0
(almost) all good poetry has high perplexity. it's by design something an out-of-the-box llm would be bad at. alignment on one poet would actually help imo.
21.11.2024 05:24 — 👍 2 🔁 0 💬 1 📌 0
Moderately grumpy UToronto alumnus nominating myself 🙋
18.11.2024 23:19 — 👍 0 🔁 0 💬 0 📌 0
Could i be added (recent alumnus)? Thank you!
18.11.2024 23:16 — 👍 1 🔁 0 💬 0 📌 0
Everyone is fixated on replicating o1 when there would be way more utility in figuring out what makes Claude so special.
18.11.2024 18:44 — 👍 4 🔁 0 💬 0 📌 0
Would love to be added thanks!
17.11.2024 16:41 — 👍 1 🔁 0 💬 0 📌 0
Assistant Professor at @cs.ubc.ca and @vectorinstitute.ai working on Natural Language Processing. Book: https://lostinautomatictranslation.com/
Princeton computer science prof. I write about the societal impact of AI, tech ethics, & social media platforms. https://www.cs.princeton.edu/~arvindn/
BOOK: AI Snake Oil. https://www.aisnakeoil.com/
Incoming assistant prof at MIT CSAIL, CS PhD from Stanford. HCI, human-AI interaction, social computing.
CS Ph.D. student at Stanford. Oil painter. HCI, NLP, generative agents, human-centered AI
Research in NLP (mostly LM interpretability & explainability).
Assistant prof at UMD CS + CLIP.
Previously @ai2.bsky.social @uwnlp.bsky.social
Views my own.
sarahwie.github.io
Professor of Natural and Artificial Intelligence @Stanford. Safety and alignment @GoogleDeepMind.
Helping machines make sense of the world. Asst Prof @icepfl.bsky.social; Before: @stanfordnlp.bsky.social @uwnlp.bsky.social AI2 #NLProc #AI
Website: https://atcbosselut.github.io/
a mediocre combination of a mediocre AI scientist, a mediocre physicist, a mediocre chemist, a mediocre manager and a mediocre professor.
see more at https://kyunghyuncho.me/
San Diego Dec 2-7, 25 and Mexico City Nov 30-Dec 5, 25. Comments to this account are not monitored. Please send feedback to townhall@neurips.cc.
PhD student @uwnlp.bsky.social
Assistant Professor @Mila-Quebec.bsky.social
Co-Director @McGill-NLP.bsky.social
Researcher @ServiceNow.bsky.social
Alumni: @StanfordNLP.bsky.social, EdinburghNLP
Natural Language Processor #NLProc
Incoming assistant professor at UCSD CSE in MLSys. Currently recruiting students! Also academic partner at Together AI. https://danfu.org/
Assistant Professor @ UChicago CS/DSI (NLP & HCI) | Writing with AI ✍️
https://minalee-research.github.io/
PhD student @ Penn
alonj.github.io
Postdoctoral fellow at Harvard Data Science Initiative | Former computer science PhD at Columbia University | ML + NLP + social sciences
https://keyonvafa.com
Associate Professor in CS @ Georgia Tech
NLP/ML researcher
https://cocoxu.github.io/
Stanford CS PhD working on RL and LLMs with Emma Brunskill and Chris Piech. Co-creator of Trace. Prev @GoogleDeepMind @MicrosoftResearch
Specifically
- Offline RL
- In-context RL
- Causality
https://anie.me/about
Unverified hot takes go to this account
PhD student @stanfordnlp.bsky.social. Robotics Intern at the Toyota Research Institute. I like language, robots, and people.
On the academic job market!
Stanford Professor of Linguistics and, by courtesy, of Computer Science, and member of @stanfordnlp.bsky.social and The Stanford AI Lab. He/Him/His. https://web.stanford.edu/~cgpotts/
PhD grad from UofT CompLing. Interested in narrative understanding, affective computing, language variation and style, and generally using NLP technologies to understand humans and society.
priya22.github.io





















