
Abstract graphic featuring concentric arcs and rectangular segments in varying shades of blue on a white background. Two purple text boxes appear: one on the left reading ‘Research Focus’ and one on the right reading ‘January 12, 2026.’
A look at what’s next in AI, plus new research in multimodal reasoning, long-horizon robotics, scalable self-supervised learning, GPU optimization with AI, and interpretable LLM reasoning. msft.it/6012tfazi
12.01.2026 18:37 —
👍 6
🔁 1
💬 0
📌 0
Eric Zimmermann, Harley Wiltzer, Justin Szeto, David Alvarez-Melis, Lester Mackey: KerJEPA: Kernel Discrepancies for Euclidean Self-Supervised Learning https://arxiv.org/abs/2512.19605 https://arxiv.org/pdf/2512.19605 https://arxiv.org/html/2512.19605
23.12.2025 06:34 —
👍 1
🔁 2
💬 0
📌 0
This project was a collaboration with Eric Zimmerman Harley Wiltzer, Justin Szeto, and @dmelis.bsky.social
Many helpful discussions shaped this work, and we’re happy to discuss with anyone interested in representation learning, self-supervision, or kernel methods.
26.12.2025 23:18 —
👍 0
🔁 0
💬 0
📌 0
•We derive closed-form high-dimensional limits for sliced MMDs and KSDs, providing both theoretical insight and practical guidance.
26.12.2025 23:18 —
👍 0
🔁 0
💬 1
📌 0
Key contributions:
•We show how LeJEPA can be viewed as a special case of a more general kernel discrepancy framework.
•We introduce KerJEPAs, which allow for richer regularization via alternative kernels.
26.12.2025 23:18 —
👍 0
🔁 0
💬 1
📌 0
Doing so allows us to place LeJEPA within a broader family of self-supervised methods and to design more flexible objectives beyond Gaussian assumptions.
26.12.2025 23:18 —
👍 0
🔁 0
💬 1
📌 0
I’m happy to share our new paper, “KerJEPA: Kernel Discrepancies for Euclidean Self-Supervised Learning”:
arxiv.org/abs/2512.19605
This work builds on the LeJEPA framework by reinterpreting its regularization objective through the lens of kernel discrepancies.
26.12.2025 23:12 —
👍 1
🔁 0
💬 1
📌 0
Search Jobs | Microsoft Careers
If you're a PhD student interested in interning with me or one of my amazing colleagues at Microsoft Research New England @msftresearch.bsky.social
this summer, please apply here
jobs.careers.microsoft.com/global/en/jo...
If you'd like to work with me, please include my name in your cover letter!
22.10.2025 00:43 —
👍 0
🔁 0
💬 0
📌 0

Microsoft Research Lab - New York City - Microsoft Research
Apply for a research position at Microsoft Research New York & collaborate with academia to advance economics research, prediction markets & ML.
Microsoft Research New York City (www.microsoft.com/en-us/resear...) is seeking applicants for multiple Postdoctoral Researcher positions in ML/AI!
These are positions for up to 2 years, starting in July 2026.
Application deadline: October 22, 2025
12.09.2025 14:57 —
👍 8
🔁 4
💬 1
📌 0
Only in LA 🐢
11.10.2025 03:35 —
👍 1
🔁 0
💬 0
📌 0

Very excited to share our preprint: Self-Speculative Masked Diffusions
We speed up sampling of masked diffusion models by ~2x by using speculative sampling and a hybrid non-causal / causal transformer
arxiv.org/abs/2510.03929
w/ @vdebortoli.bsky.social, Jiaxin Shi, @arnauddoucet.bsky.social
07.10.2025 22:09 —
👍 13
🔁 6
💬 0
📌 0
Could this be our future? (Sound on)
01.10.2025 13:21 —
👍 1
🔁 0
💬 0
📌 0

The Microsoft Research Undergraduate Internship Program offers 12-week internships in our Redmond, NYC, or New England labs for rising juniors and seniors who are passionate about technology. Apply by October 6: msft.it/6015scgSJ
12.09.2025 15:00 —
👍 6
🔁 2
💬 0
📌 3
If you're an undergraduate interested in interning with me or one of my amazing colleagues at Microsoft Research New England this summer, please apply here: msft.it/6015scgSJ
17.09.2025 03:00 —
👍 0
🔁 0
💬 0
📌 0

Tomorrow we're excited to host @sarahalamdari.bsky.social at Chalmers for the AI4Science seminar and hear about generative models for protein design! Talk at 3pm CEST. 🤩
For more info, including details on how to join virtually, please see psolsson.github.io/AI4ScienceSe...
@smnlssn.bsky.social
10.09.2025 08:24 —
👍 8
🔁 3
💬 0
📌 0
Search Jobs | Microsoft Careers
We may have the chance to hire an outstanding researcher 3+ years post PhD to join Tarleton Gillespie, Mary Gray and me in Cambridge MA bringing critical sociotechnical perspectives to bear on new technologies.
jobs.careers.microsoft.com/global/en/jo...
28.07.2025 17:26 —
👍 90
🔁 49
💬 0
📌 3
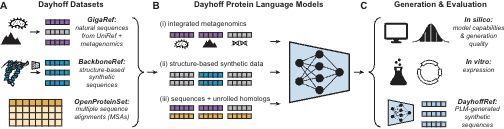
In 1965, Margaret Dayhoff published the Atlas of Protein Sequence and Structure, which collated the 65 proteins whose amino acid sequences were then known.
Inspired by that Atlas, today we are releasing the Dayhoff Atlas of protein sequence data and protein language models.
25.07.2025 22:05 —
👍 66
🔁 28
💬 3
📌 3
So you want to skip our thinning proofs—but you’d still like our out-of-the-box attention speedups? I’ll be presenting the Thinformer at two ICML workshop posters tomorrow!
Catch me at Es-FoMo (1-2:30, East hall A) and at LCFM (10:45-11:30 & 3:30-4:30, West 202-204)
19.07.2025 07:04 —
👍 5
🔁 4
💬 0
📌 0
Jikai Jin, Lester Mackey, Vasilis Syrgkanis: It's Hard to Be Normal: The Impact of Noise on Structure-agnostic Estimation https://arxiv.org/abs/2507.02275 https://arxiv.org/pdf/2507.02275 https://arxiv.org/html/2507.02275
04.07.2025 06:53 —
👍 2
🔁 5
💬 0
📌 0
 15.07.2025 03:30 —
👍 4
🔁 0
💬 0
📌 0
15.07.2025 03:30 —
👍 4
🔁 0
💬 0
📌 0

Low-Rank Thinning
The goal in thinning is to summarize a dataset using a small set of representative points. Remarkably, sub-Gaussian thinning algorithms like Kernel Halving and Compress can match the quality of unifor...
Off to ICML next week?
Check out my student Annabelle’s paper in collaboration with @lestermackey.bsky.social and colleagues on low-rank thinning!
New theory, dataset compression, efficient attention and more:
arxiv.org/abs/2502.12063
12.07.2025 16:27 —
👍 11
🔁 5
💬 0
📌 1
Your data is low-rank, so stop wasting compute! In our new paper on low-rank thinning, we share one weird trick to speed up Transformer inference, SGD training, and hypothesis testing at scale. Come by ICML poster W-1012 Tuesday at 4:30!
14.07.2025 18:29 —
👍 25
🔁 7
💬 2
📌 2
Jikai Jin, Lester Mackey, Vasilis Syrgkanis
It's Hard to Be Normal: The Impact of Noise on Structure-agnostic Estimation
https://arxiv.org/abs/2507.02275
04.07.2025 04:40 —
👍 2
🔁 1
💬 0
📌 0
2025 Call For Ethics Reviewers
If you are able and willing to participate in the review process, please sign up at this form. Feel free to share this call with your colleagues.
NeurIPS is seeking additional ethics reviewers this year. If you are able and willing to participate in the review process, please sign up at the form in the link:
neurips.cc/Conferences/...
Please share this call with your colleagues!
02.07.2025 16:06 —
👍 11
🔁 8
💬 0
📌 0

甘利 俊一 栄誉研究員が「京都賞」を受賞
甘利 俊一栄誉研究員(本務:帝京大学 先端総合研究機構 特任教授)は、人工ニューラルネットワーク、機械学習、情報幾何学分野での先駆的な研究が評価され、第40回(2025)京都賞(先端技術部門 受賞対象分野:情報科学)を受賞しました。
Shunichi Amari has been awarded the 40th (2025) Kyoto Prize in recognition of his pioneering research in the fields of artificial neural networks, machine learning, and information geometry
www.riken.jp/pr/news/2025...
20.06.2025 13:26 —
👍 35
🔁 12
💬 2
📌 0
If you’d like to expand your analysis to support equal weighted kernel thinning coresets, have a look at Low-Rank Thinning (arxiv.org/pdf/2502.12063); that bounds kernel thinning MMD directly in terms of eigenvalue decay
01.05.2025 18:07 —
👍 1
🔁 0
💬 1
📌 0
Very cool!
01.05.2025 17:56 —
👍 1
🔁 0
💬 0
📌 0

🏆 I'm delighted to share that I've won a 2025 COPSS Emerging Leader Award! 😃 And congratulations to my fellow winners! 🙌🏽
Check out how each of us is improving and advancing the profession of #statistics and #datascience here: tinyurl.com/copss-emerging-leader-award
11.03.2025 06:47 —
👍 13
🔁 4
💬 3
📌 2




