This Thursday at @facct.bsky.social, @jennahgosciak.bsky.social's presenting our work at the 10:45am "Audits 2" session! We collaborated across @cornellbowers.bsky.social, @mit.edu, & @stanfordlaw.bsky.social to study health estimate biases from delayed race data collection: arxiv.org/abs/2506.13735
24.06.2025 15:40 — 👍 17 🔁 1 💬 1 📌 0
Excited to share our work on the impact of reporting delays on disparity audits in healthcare 😄 Project started at the Stanford RegLab Summer Institute last year, and continued with an amazing group of collaborators! @jennahgosciak.bsky.social will present this at FAccT -- do drop by if attending!
24.06.2025 15:37 — 👍 6 🔁 1 💬 0 📌 0
We also encourage everyone to check out research on pipeline aware fairness (🔗 arxiv.org/pdf/2309.17337), demographic data collection (🔗 arxiv.org/abs/2011.02282), and broader challenges with disparity assessments (🔗 dl.acm.org/doi/10.1145/3593013.3594015), which influenced our work!
(12/n)
24.06.2025 14:51 — 👍 3 🔁 0 💬 0 📌 0
Huge thanks to Stanford PHS for their support with using American Family Cohort data that enabled this study! Also thank you to members of the RegLab for providing helpful feedback from different perspectives!
(11/n)
24.06.2025 14:51 — 👍 4 🔁 0 💬 1 📌 0
- Conduct audits dynamically, considering how inputs like race may change over time.
- Invest in improving data collection systems; imputation on its own is not a solution.
- Better understand the mechanisms of delay, as it is difficult to understand and study such questions retrospectively.
(10/n)
24.06.2025 14:51 — 👍 5 🔁 0 💬 1 📌 0
As the use of algorithmic systems to make high-stakes decisions increases, it will be important to regularly audit these systems. Our paper has three main takeaways for practitioners:
(9/n)
24.06.2025 14:51 — 👍 4 🔁 0 💬 1 📌 0
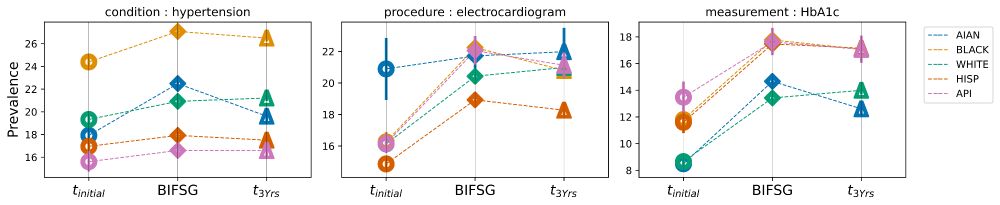
Figure that compares three types of prevalence estimates: the initial point of assessment (t_initial), estimates imputed with BIFSG, and estimates 3 years from the initial assessment (t_3Yrs). Prevalence is estimated at the national level for hypertension diagnoses, electrocardiogram procedures, and hbA1c measurements.
What if we try to correct for delays by imputing race? We test the effectiveness of Bayesian Improved First Name, Surname, and Geocoding (BIFSG), a common method for race imputation. BIFSG does not lead to substantial improvement as it often overestimates prevalence for non-white race groups.
(8/n)
24.06.2025 14:51 — 👍 4 🔁 0 💬 1 📌 0
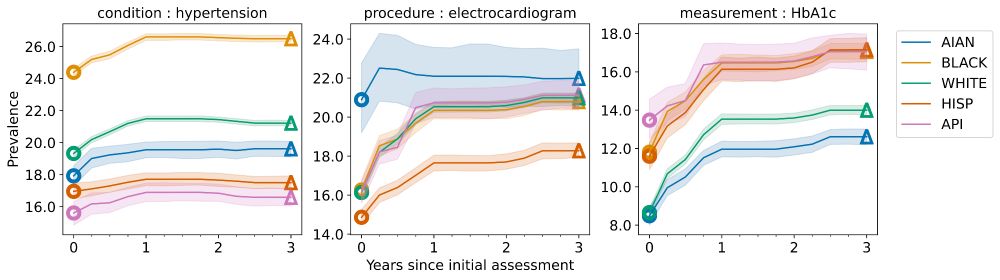
Figure that shows disparity assessments at the national level over time for hypertension diagnoses, electrocardiogram procedures, and hbA1c measurements.
We observe similar impacts at the national level and across other health outcomes, though with less variation.
(7/n)
24.06.2025 14:51 — 👍 4 🔁 0 💬 1 📌 0
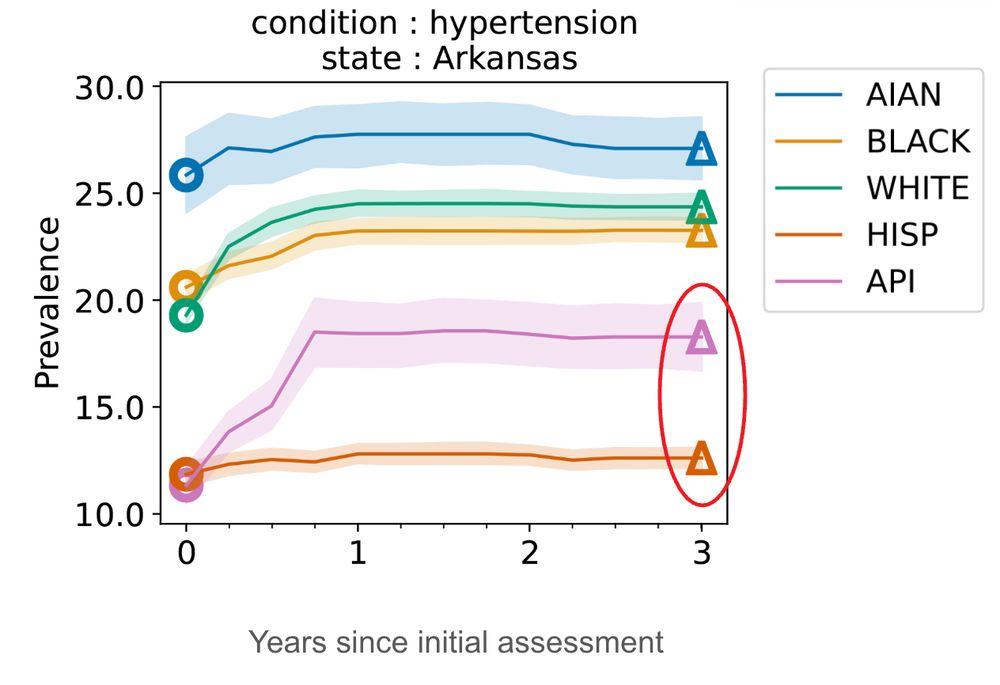
Figure that shows differences in hypertension prevalence for patients in Arkansas. Prevalence estimates appear on the y-axis and years from the initial assessment date are on the x-axis. We fix a cohort of patients, some of whom do not have race information due to delays in reporting. Over time, we recover race information for these patients and are able to more accurately estimate disparities. Initially, there appears to be no disparity between Hispanic and Asian/Pacific Islanders. Three years from the initial assessment date, there is a much more noticeable gap, which is highlighted in red.
Consider a particularly striking example: prevalence of hypertension diagnoses in Arkansas. Failing to account for delays would not represent the true disparity between Asian and Pacific Islander patients vs. Hispanic patients.
(6/n)
24.06.2025 14:51 — 👍 4 🔁 0 💬 1 📌 0
Why do these differences matter? Delays can distort disparity assessments. We examine the impact of delays retrospectively on a fixed cohort of patients at the national, state, and practice level. Not accounting for delays can distort and mis-represent the true disparity.
(5/n)
24.06.2025 14:51 — 👍 4 🔁 0 💬 1 📌 0
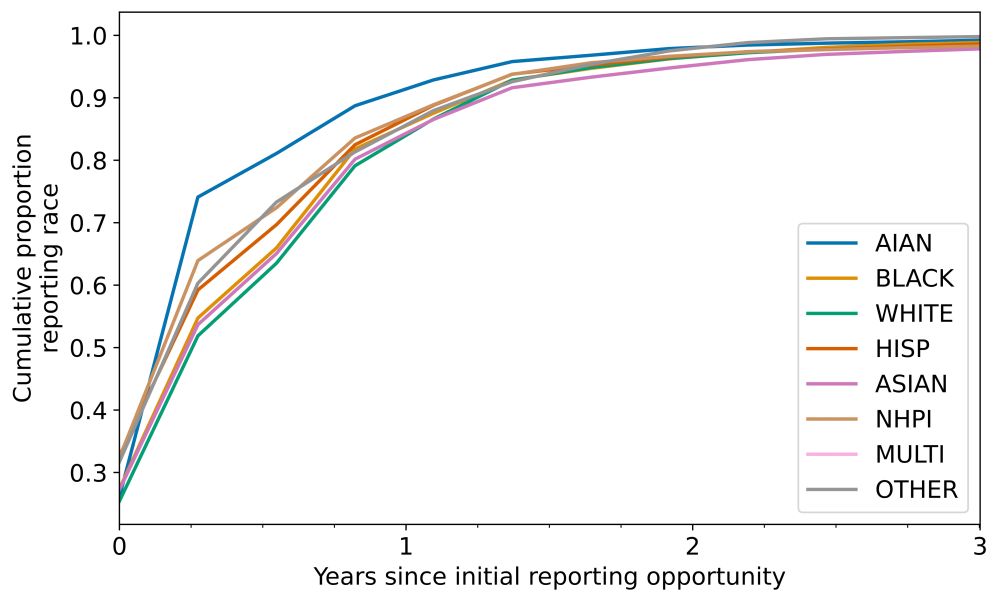
Figure that shows differences in the cumulative proportion reporting race over time by race and ethnicity. Groups like AIAN and NHPI have lower rates of delayed reporting.
We see differences in race reporting delays by race and ethnicity. Patients with delays are also older, tend to have more visits, and experience higher rates of adverse health outcomes such as clinical diagnoses, procedures, and measurements.
(4/n)
24.06.2025 14:51 — 👍 4 🔁 0 💬 1 📌 0
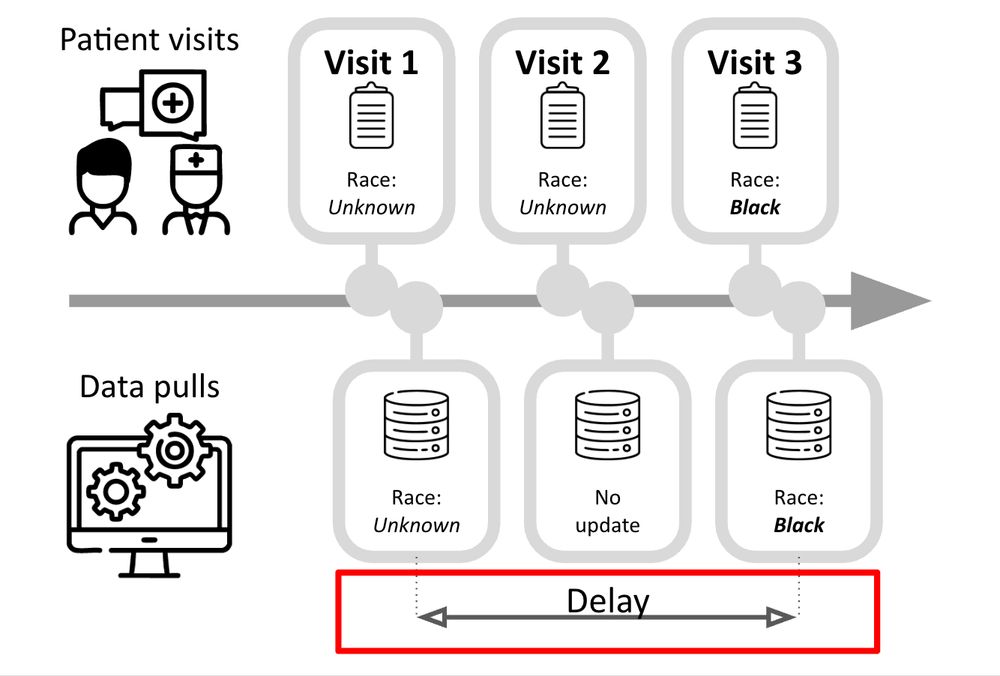
Figure that shows patient visits over time alongside asynchronous data pulls. Information like race may at first be unknown, as recorded on the patient's first visit, but by visit 3 this information is collected. The time lag in the data collection is what we define as a "delay."
In our data, race information may not be reported or collected on a patient’s 1st health visit. However, over time, information on race may eventually be obtained. This is what we refer to as a "delay" in race reporting, which we observe via longitudinal EHR data.
(3/n)
24.06.2025 14:51 — 👍 4 🔁 0 💬 1 📌 0

Figure that shows a stylized representation of electronic health records with information like name, date of birth, sex, date, and race.
We are increasingly aware that AI may exacerbate disparities, particularly in 🏥healthcare. Our work demonstrates that it is important to audit AI systems over time. We show in a large dataset of electronic health records that ~73% of patients experience race reporting delays.
(2/n)
24.06.2025 14:51 — 👍 6 🔁 0 💬 1 📌 0

"Bias Delayed is Bias Denied? Assessing the Effect of Reporting Delays on Disparity Assessments"
Conducting disparity assessments at regular time intervals is critical for surfacing potential biases in decision-making and improving outcomes across demographic groups. Because disparity assessments fundamentally depend on the availability of demographic information, their efficacy is limited by the availability and consistency of available demographic identifiers. While prior work has considered the impact of missing data on fairness, little attention has been paid to the role of delayed demographic data. Delayed data, while eventually observed, might be missing at the critical point of monitoring and action -- and delays may be unequally distributed across groups in ways that distort disparity assessments. We characterize such impacts in healthcare, using electronic health records of over 5M patients across primary care practices in all 50 states. Our contributions are threefold. First, we document the high rate of race and ethnicity reporting delays in a healthcare setting and demonstrate widespread variation in rates at which demographics are reported across different groups. Second, through a set of retrospective analyses using real data, we find that such delays impact disparity assessments and hence conclusions made across a range of consequential healthcare outcomes, particularly at more granular levels of state-level and practice-level assessments. Third, we find limited ability of conventional methods that impute missing race in mitigating the effects of reporting delays on the accuracy of timely disparity assessments. Our insights and methods generalize to many domains of algorithmic fairness where delays in the availability of sensitive information may confound audits, thus deserving closer attention within a pipeline-aware machine learning framework.
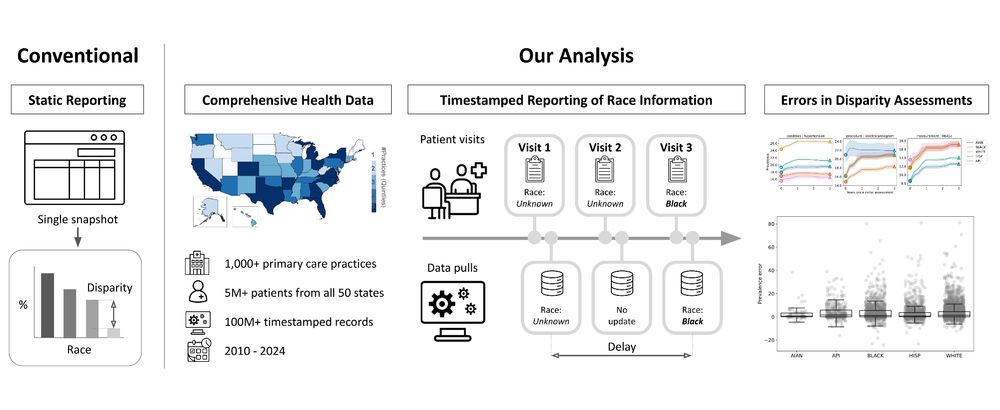
Figure contrasting a conventional approach to conducting disparity assessments, which is static, to the analysis we conduct in this paper. Our analysis (1) uses comprehensive health data from over 1,000 primary care practices and 5 million patients across the U.S., (2) timestamped information on the reporting of race to measure delay, and (3) retrospective analyses of disparity assessments under varying levels of delay.
I am presenting a new 📝 “Bias Delayed is Bias Denied? Assessing the Effect of Reporting Delays on Disparity Assessments” at @facct.bsky.social on Thursday, with @aparnabee.bsky.social, Derek Ouyang, @allisonkoe.bsky.social, @marzyehghassemi.bsky.social, and Dan Ho. 🔗: arxiv.org/abs/2506.13735
(1/n)
24.06.2025 14:51 — 👍 13 🔁 4 💬 1 📌 3

A screenshot of our paper's:
Title: A Framework for Auditing Chatbots for Dialect-Based Quality-of-Service Harms
Authors: Emma Harvey, Rene Kizilcec, Allison Koenecke
Abstract: Increasingly, individuals who engage in online activities are expected to interact with large language model (LLM)-based chatbots. Prior work has shown that LLMs can display dialect bias, which occurs when they produce harmful responses when prompted with text written in minoritized dialects. However, whether and how this bias propagates to systems built on top of LLMs, such as chatbots, is still unclear. We conduct a review of existing approaches for auditing LLMs for dialect bias and show that they cannot be straightforwardly adapted to audit LLM-based chatbots due to issues of substantive and ecological validity. To address this, we present a framework for auditing LLM-based chatbots for dialect bias by measuring the extent to which they produce quality-of-service harms, which occur when systems do not work equally well for different people. Our framework has three key characteristics that make it useful in practice. First, by leveraging dynamically generated instead of pre-existing text, our framework enables testing over any dialect, facilitates multi-turn conversations, and represents how users are likely to interact with chatbots in the real world. Second, by measuring quality-of-service harms, our framework aligns audit results with the real-world outcomes of chatbot use. Third, our framework requires only query access to an LLM-based chatbot, meaning that it can be leveraged equally effectively by internal auditors, external auditors, and even individual users in order to promote accountability. To demonstrate the efficacy of our framework, we conduct a case study audit of Amazon Rufus, a widely-used LLM-based chatbot in the customer service domain. Our results reveal that Rufus produces lower-quality responses to prompts written in minoritized English dialects.
I am so excited to be in 🇬🇷Athens🇬🇷 to present "A Framework for Auditing Chatbots for Dialect-Based Quality-of-Service Harms" by me, @kizilcec.bsky.social, and @allisonkoe.bsky.social, at #FAccT2025!!
🔗: arxiv.org/pdf/2506.04419
23.06.2025 14:44 — 👍 30 🔁 10 💬 1 📌 2

"Characterizing Bias: Benchmarking Large Language Models in Simplified versus Traditional Chinese" Abstract:
While the capabilities of Large Language Models (LLMs) have been studied in both Simplified and Traditional Chinese, it is yet unclear whether LLMs exhibit differential performance when prompted in these two variants of written Chinese. This understanding is critical, as disparities in the quality of LLM responses can perpetuate representational harms by ignoring the different cultural contexts underlying Simplified versus Traditional Chinese, and can exacerbate downstream harms in LLM-facilitated decision-making in domains such as education or hiring. To investigate potential LLM performance disparities, we design two benchmark tasks that reflect real-world scenarios: regional term choice (prompting the LLM to name a described item which is referred to differently in Mainland China and Taiwan), and regional name choice (prompting the LLM to choose who to hire from a list of names in both Simplified and Traditional Chinese). For both tasks, we audit the performance of 11 leading commercial LLM services and open-sourced models -- spanning those primarily trained on English, Simplified Chinese, or Traditional Chinese. Our analyses indicate that biases in LLM responses are dependent on both the task and prompting language: while most LLMs disproportionately favored Simplified Chinese responses in the regional term choice task, they surprisingly favored Traditional Chinese names in the regional name choice task. We find that these disparities may arise from differences in training data representation, written character preferences, and tokenization of Simplified and Traditional Chinese. These findings highlight the need for further analysis of LLM biases; as such, we provide an open-sourced benchmark dataset to foster reproducible evaluations of future LLM behavior across Chinese language variants (this https URL).
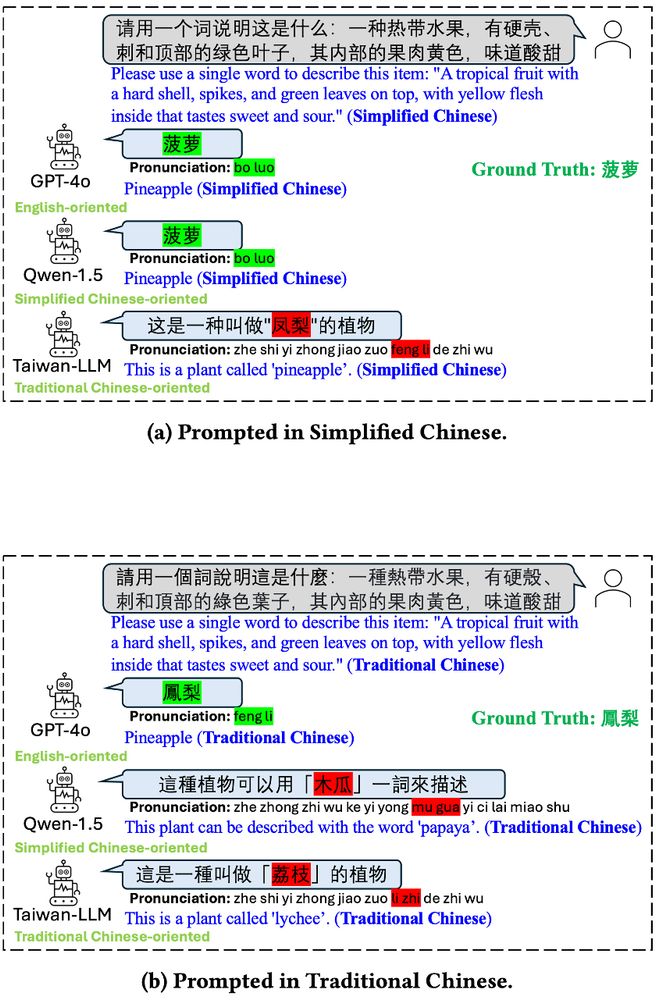
Figure showing that three different LLMs (GPT-4o, Qwen-1.5, and Taiwan-LLM) may answer a prompt about pineapples differently when asked in Simplified Chinese vs. Traditional Chinese.
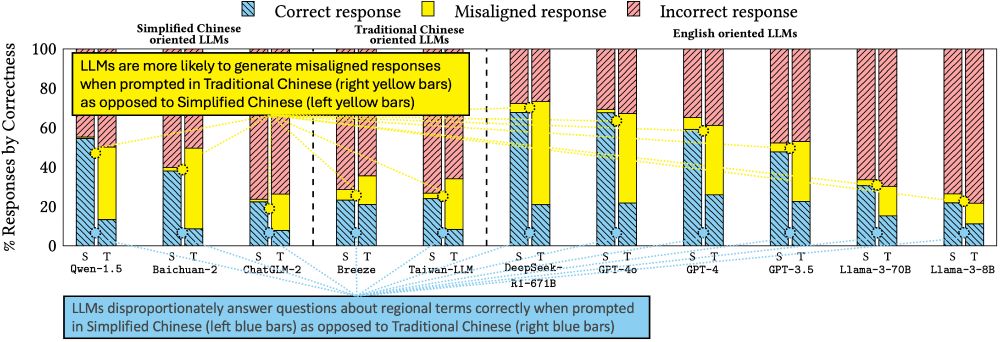
Figure showing that LLMs disproportionately answer questions about regional-specific terms (like the word for "pineapple," which differs in Simplified and Traditional Chinese) correctly when prompted in Simplified Chinese as opposed to Traditional Chinese.
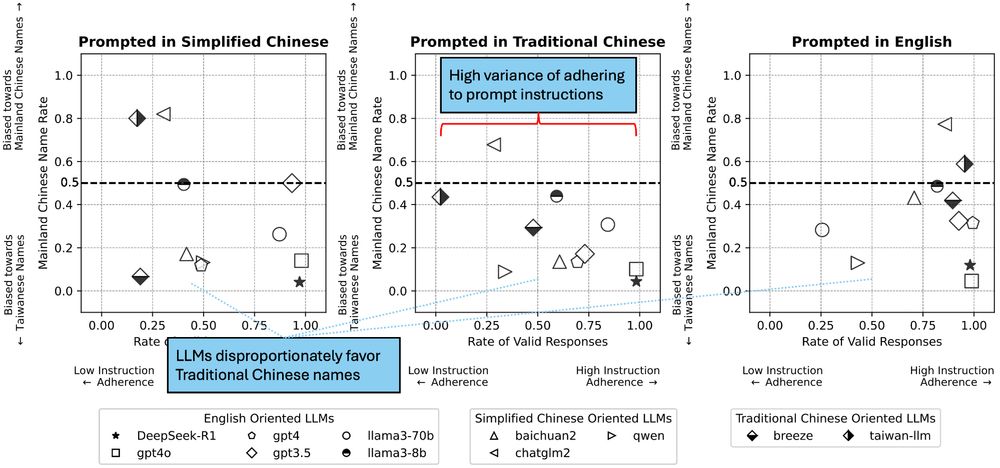
Figure showing that LLMs have high variance of adhering to prompt instructions, favoring Traditional Chinese names over Simplified Chinese names in a benchmark task regarding hiring.
🎉Excited to present our paper tomorrow at @facct.bsky.social, “Characterizing Bias: Benchmarking Large Language Models in Simplified versus Traditional Chinese”, with @brucelyu17.bsky.social, Jiebo Luo and Jian Kang, revealing 🤖 LLM performance disparities. 📄 Link: arxiv.org/abs/2505.22645
22.06.2025 21:15 — 👍 17 🔁 4 💬 1 📌 3

It was a pleasure to present our (@jennahgosciak.bsky.social @tungdnguyen.bsky.social @informor.bsky.social) large-scale study of Reddit community's AI rules in the AI Ethics and Concerns session at #CHI25! The paper is now available open access in the ACM library: dl.acm.org/doi/10.1145/....
30.04.2025 01:08 — 👍 14 🔁 2 💬 0 📌 0
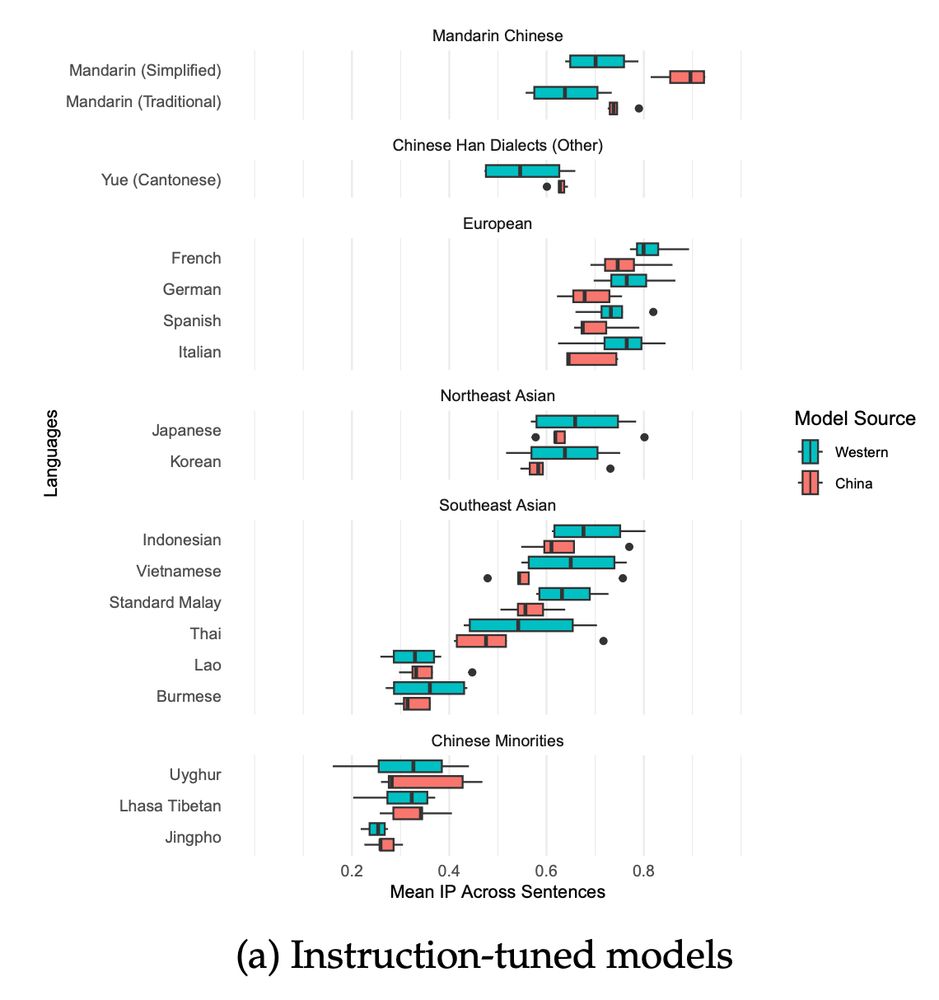
[New preprint!] Do Chinese AI Models Speak Chinese Languages? Not really. Chinese LLMs like DeepSeek are better at French than Cantonese. Joint work with
Unso Jo and @dmimno.bsky.social . Link to paper: arxiv.org/pdf/2504.00289
🧵
09.04.2025 20:27 — 👍 25 🔁 6 💬 1 📌 0
*NEW DATASET AND PAPER* (CHI2025): How are online communities responding to AI-generated content (AIGC)? We study this by collecting and analyzing the public rules of 300,000+ subreddits in 2023 and 2024. 1/
26.03.2025 17:17 — 👍 16 🔁 5 💬 1 📌 2
*NEW PAPER* How are online communities adapting to the presence of AI-generated content (AIGC)? To answer this question we collected the community rules for 300,000 public subreddits and identified rules governing the use of AI. /1
22.10.2024 13:22 — 👍 10 🔁 1 💬 1 📌 1
phd student at uw seattle & max planck institute (imprs-phds) | ai/ml, science of science, critical demography, economic sociology, model multiplicity | i also run. https://avisokay.github.io/ https://www.strava.com/athletes/9804160
Data Science Institute Postdoctoral Fellow, Columbia University
emfeltham.github.io
The 11th International Conference on Computational Social Science (IC2S2) will be held in Norrköping, Sweden, July 21-24, 2025.
Website: https://www.ic2s2-2025.org/
Visualization and Interaction Design. Understanding and improving (maybe) research practices of analytical sociologists
https://vvseva.quarto.pub/
PhD Student, Institute for Analytical Sociology (IAS)
Political Sociologist studying policymaking processes in U.S. Congress.
Program Chair @ic2s2.bsky.social
Website: https://hendrik-erz.de
I develop @zettlr.com, a free academic writing app.
Cornell Tech professor (information science, AI-mediated Communication, trustworthiness of our information ecosystem). New York City. Taller in person. Opinions my own.
PhD candidate @Wharton OID. Interests: causal inference, partial identification, fairness, discrimination
Computer science doctorand at Uppsala University, @uuinfolab.bsky.social.
Mining social networks, discovering new music, occasionally playing baseball and softball.
Probably not George Michael, but search engines believe otherwise.
PhD Student in Social Data Science, University of Copenhagen
AI & Society | Algorithmic Fairness | ML | Education Data Science
https://tereza-blazkova.github.io/
she/her 🌈 🐢 PhD student in cs at Princeton researching ethics of algorithmic decision-making
https://www.poetryfoundation.org/poetry-news/63112/the-ford-faberge-by-marianne-moore
I work on tools, machines & their maintenance.
amritkwatra.com
Assistant professor in the University of Michigan School of Information. https://www.benzevgreen.com
researching AI [evaluation, governance, accountability]
Researcher of online rumors & disinformation. Former basketball player. Prof at University of Washington, HCDE. Co-founder of the UW Center for an Informed Public. Personal account: Views may not reflect those of my employer. #RageAgainstTheBullshitMachine
economist. Posts Reflect Me Only! collects/analyzes: poll, market, social media/online data, to study: news, public opinion, ads, market design
President of Signal, Chief Advisor to AI Now Institute
Book: https://thecon.ai
Web: https://faculty.washington.edu/ebender
Founder & PI @aial.ie, @tcddublin.bsky.social
AI accountability, AI audits & evaluation, critical data studies. Cognitive scientist by training. Ethiopian in Ireland. She/her
I work with communities on citizen science for safer, fairer, more understanding Internet. Founder: Citizens & Technology Lab. Assistant Prof in Communication at Cornell · Guatemalan-American. @natematias@social.coop
natematias.com
citizensandtech.org
Associate Professor of Public Policy, Politics, and Education @UVA.
I share social science.




















