
Memorization vs. generalization in deep learning: implicit biases, benign overfitting, and more
Or: how I learned to stop worrying and love the memorization
What is the relationship between memorization and generalization in AI? Is there a fundamental tradeoff? In infinitefaculty.substack.com/p/memorizati... I’ve reviewed some of the evolving perspectives on memorization & generalization in machine learning, from classic perspectives through LLMs.
18.02.2026 15:54 — 👍 129 🔁 27 💬 4 📌 5
Interesting convergence:
The trick that made predictive self-supervised vision models work seems to be what the brain was doing all along
w/ @predictivebrain.bsky.social: visual cortex is most sensitive to high-level prediction errors -- even in V1
Now published:
journals.plos.org/ploscompbiol...
03.02.2026 10:35 — 👍 21 🔁 5 💬 0 📌 0
This paper had a pretty shocking headline result (40% of voxels!), so I dug into it, and I think it is wrong. Essentially: they compare two noisy measures and find that about 40% of voxels have different sign between the two. I think this is just noise!
05.01.2026 17:22 — 👍 234 🔁 97 💬 8 📌 9
so nice to see this out sush!!
19.11.2025 08:47 — 👍 1 🔁 0 💬 1 📌 0
archive.ph/smEj0 (or, unpaywalled 🤫)
07.11.2025 10:32 — 👍 2 🔁 0 💬 0 📌 0

The Case That A.I. Is Thinking
ChatGPT does not have an inner life. Yet it seems to know what it’s talking about.
This is, without a doubt, the best popular article about current state of AI. And on whether LLMs are truly 'thinking' or 'understanding' -- and what that question even means
www.newyorker.com/magazine/202...
07.11.2025 10:32 — 👍 5 🔁 0 💬 1 📌 0
omg. what journal? name and shame
19.09.2025 12:34 — 👍 0 🔁 0 💬 0 📌 0
huh! if these effects are similar and consistent, I think it should work, but the q. is how do you get a vector representation for novel pseudowords? we currently use lexicosemantic word vectors and they are undefined for novel words.
so how to represent the novel words? v. interesting test case
19.09.2025 12:32 — 👍 0 🔁 0 💬 0 📌 0
@nicolecrust.bsky.social might be of interest
18.09.2025 11:52 — 👍 0 🔁 0 💬 0 📌 0
New paper on memorability, with @davogelsang.bsky.social !
18.09.2025 10:45 — 👍 10 🔁 0 💬 0 📌 0
Together, our results support a classic idea: cognitive limitations can be a powerful inductive bias for learning
Yet they also reveal a curious distinction: a model with more human-like *constraints* is not necessarily more human-like in its predictions
18.08.2025 12:40 — 👍 0 🔁 0 💬 0 📌 0
This paradox – better language models yielding worse behavioural predictions – could not be explained by prior explanations: The mechanism appears distinct from those linked to superhuman training scale or memorisation
18.08.2025 12:40 — 👍 0 🔁 0 💬 1 📌 0
However, we then used these models to predict human behaviour
Strikingly these same models that were demonstrably better at the language task, were worse at predicting human reading behaviour
18.08.2025 12:40 — 👍 0 🔁 0 💬 1 📌 0

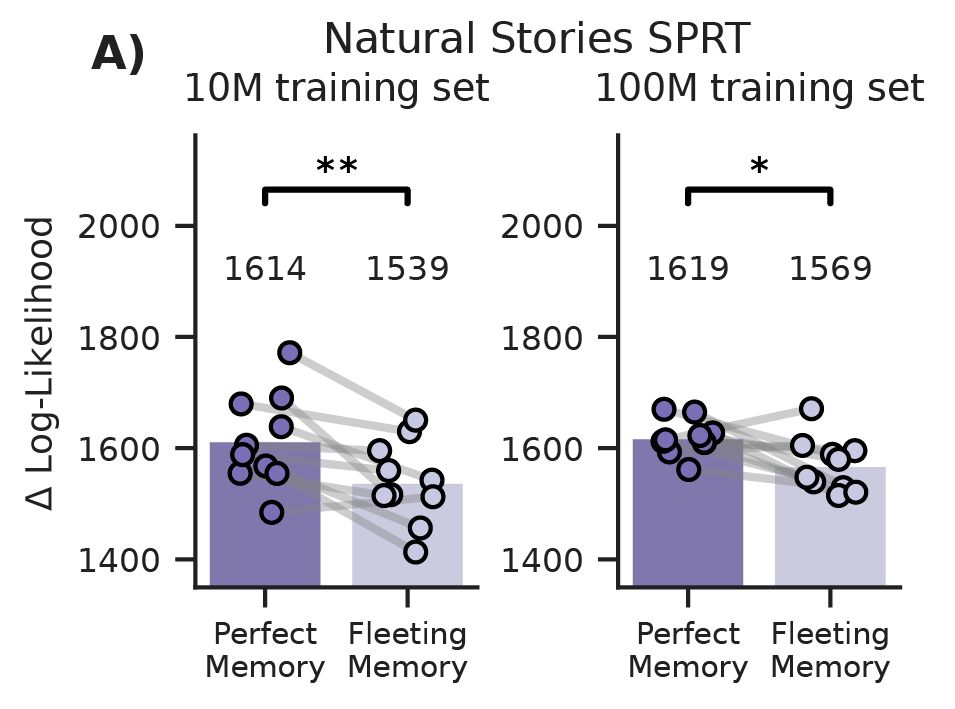
The benefit was robust
Fleeting memory models achieved better next-token prediction (lower loss) and better syntactic knowledge (higher accuracy) on the BLiMP benchmark
This was consistent across seeds and for both 10M and 100M training sets
18.08.2025 12:40 — 👍 0 🔁 0 💬 1 📌 0

But we noticed this naive decay was too strong
Human memory has a brief 'echoic' buffer that perfectly preserves the immediate past. When we added this – a short window of perfect retention before the decay -- the pattern flipped
Now, fleeting memory *helped* (lower loss)
18.08.2025 12:40 — 👍 0 🔁 0 💬 1 📌 0

Our first attempt, a "naive" memory decay starting from the most recent word, actually *impaired* language learning. Models with this decay had higher validation loss, and this worsened (even higher loss) as the decay became stronger
18.08.2025 12:40 — 👍 0 🔁 0 💬 1 📌 0

To test this in a modern context, we propose the ‘fleeting memory transformer’
We applied a power-law memory decay to the self-attention scores, simulating how access to past words fades over time, and ran controlled experiments on the developmentally realistic BabyLM corpus
18.08.2025 12:40 — 👍 0 🔁 0 💬 1 📌 0
However, this appears difficult to reconcile with the success of transformers, which can learn language very effectively, despite lacking working memory limitations or other recency biases
Would the blessing of fleeting memory still hold in transformer language models?
18.08.2025 12:40 — 👍 0 🔁 0 💬 1 📌 0
A core idea in cognitive science is that the fleetingness of working memory isn't a flaw
It may actually help at learning language by forcing a focus on the recent past and providing an incentive to discover abstract structure rather than surface details
18.08.2025 12:40 — 👍 2 🔁 0 💬 1 📌 0
Poster Presentation
On Wednesday, Maithe van Noort will present a poster on “Compositional Meaning in Vision-Language Models and the Brain”
First results from a much larger project on visual and linguistic meaning in brains and machines, with many collaborators -- more to come!
t.ly/TWsyT
12.08.2025 11:14 — 👍 0 🔁 0 💬 0 📌 0
Poster Presentation
On Friday, during a contributed talk (and a poster), @wiegerscheurer will present the project he spearheaded: “A hierarchy of spatial predictions across human visual cortex during natural vision”
(Full preprint soon)
t.ly/fTJqy
12.08.2025 11:14 — 👍 3 🔁 1 💬 1 📌 0

CCN has arrived here here in Amsterdam!
Come find me to meet or catch up
Some highlights from students and collaborators:
12.08.2025 11:14 — 👍 8 🔁 0 💬 1 📌 0

Waarom kom ik toch niet op die naam?
Eh, je weet wel wie... dinges! Heb jij ook soms zo’n moeite om op een naam te komen? Hersenonderzoeker Micha Heilbron legt uit hoe dat komt - en waarom een naam eigenlijk niet zo belangrijk is.
Waarom vergeet je namen maar weet je nog precies wat iemand doet? En zijn herinneringen ooit echt helemaal weg?
Ik ging bij Oplossing Gezocht in gesprek over hoe ons brein informatie opslaat en waarom vergeten eigenlijk heel slim is:
www.nemokennislink.nl/publicaties/...
15.07.2025 08:47 — 👍 3 🔁 0 💬 0 📌 0
Exciting new preprint from the lab: “Adopting a human developmental visual diet yields robust, shape-based AI vision”. A most wonderful case where brain inspiration massively improved AI solutions.
Work with @zejinlu.bsky.social @sushrutthorat.bsky.social and Radek Cichy
arxiv.org/abs/2507.03168
08.07.2025 13:03 — 👍 140 🔁 59 💬 3 📌 11
i’m all in the “this is a neat way to help explain things” camp fwiw :)
23.05.2025 15:53 — 👍 0 🔁 0 💬 0 📌 0
Our findings, together with some other recent studies, suggest the brain may use a similar strategy — constantly predicting higher-level features — to efficiently learn robust visual representations of (and from!) the natural world
23.05.2025 11:39 — 👍 6 🔁 0 💬 0 📌 0
Baritone, researcher, designer
bascornelissen.nl
Postdoc Utrecht University | PhD Leiden Uni | Political History | Computational Methods | NLP | Dataviz | Here for politics, papers & plots
Associate Professor at GroNLP ( @gronlp.bsky.social ) #NLP | Multilingualism | Interpretability | Language Learning in Humans vs NeuralNets | Mum^2
Head of the InClow research group: https://inclow-lm.github.io/
Multimodal Communication and Learning in Social Interactions (CoCoDev team). Associate Professor of Computer/Cognitive Science at Aix-Marseille University.
afourtassi.github.io
asst prof computational neuroscience UIUC
https://publish.illinois.edu/pospisil-lab/
Sardinian. Assistant prof at the illc in Amsterdam. Language & cognition w/ models & experiments. Roughly Bayesian. Past: Tübingen, Centre for Language Evolution in Edinburgh (He/Him)
ACL Rolling Review (https://aclrollingreview.org)
Tweets by the ARR Communications / Support Team
Cognitive scientist focusing on language processing and the phenomenology of vision
Postdoc in visual cognitive neuroscience - Donders Institute, Radboud University -
https://sites.google.com/view/marcogandolfo/publications
Science philosopher on a burning planet
Writing a book on ecopopulism, wrote one on everyday activism.
https://intra-action.com/about
https://www.uu.nl/staff/CFJulien/Publications
Research Leader at https://csl.sony.fr. My work blends linguistics, artificial intelligence, and complex systems science to understand how humans create and share meaning through language and narrative. Read more at https://remivantrijp.com
Aspiring philosopher; tolerable human; "amusing combination of sardonic detachment & literally all the feelings felt entirely unironically all at once" [he/his]
❤️💚 Tweede Kamerlid @groenlinks_pvda
✏️ Onderwijs, Kinderopvang, Emancipatiebeleid & Nationaal Programma Leefbaarheid en Veiligheid
💪🏼 strijdt voor gelijke kansen en rechten
📖 schreef 'Rood in Wassenaar'
i am a cognitive scientist working on auditory perception at the University of Auckland and the Yale Child Study Center 🇳🇿🇺🇸🇫🇷🇨🇦
lab: themusiclab.org
personal: mehr.nz
intro to my research: youtu.be/-vJ7Jygr1eg
PhD student at Harvard/MIT interested in neuroscience, language, AI | @kempnerinstitute.bsky.social @mitbcs.bsky.social | prev: Princeton neuro | coltoncasto.github.io
Cog Neuro PhD @york.ac.uk 🧠 Using MEG/OPM & EEG - interested in Predictive Coding, AI/ML, Sensory Integration, Consciousness, & ASMR
MSc Student in NeuroAI @ McGill & Mila
w/ Blake Richards & Shahab Bakhtiari
PhD student at Stanford | Interested in language processing by humans and machines | prev. UTokyo Medicine | UTokyo-Princeton Exchange '19-'20 | https://taka-yamakoshi.github.io/
Associate Professor of Computer Science and Psychology @ Princeton. Posts are my views only. https://www.cs.princeton.edu/~bl8144/
Unparalleled reporting and commentary on politics and culture, plus humor and cartoons, fiction and poetry. Get our Daily newsletter: http://nyer.cm/gtI6pVM
Follow The New Yorker’s writers and contributors: https://go.bsky.app/Gh5bFwS
























