Instruction tuning unlocks incredible skills in LLMs, but at a cost: they become dangerously overconfident.
You face a choice: a well-calibrated base model or a capable but unreliable instruct model.
What if you didn't have to choose? What if you could navigate the trade-off?
(1/8)
30.10.2025 17:00 — 👍 2 🔁 1 💬 1 📌 0

Cross-Tokenizer Distillation via Approximate Likelihood Matching
Distillation has shown remarkable success in transferring knowledge from a Large Language Model (LLM) teacher to a student LLM. However, current distillation methods predominantly require the same tok...
Check out the paper for lots of details.
We are also releasing our code as part of `tokenkit`, a new library implementing advanced tokenization transfer methods. More to follow on that👀
Paper: arxiv.org/abs/2503.20083
Code: github.com/bminixhofer/...
w/ Ivan Vulić and @edoardo-ponti.bsky.social
02.04.2025 06:41 — 👍 3 🔁 0 💬 1 📌 0
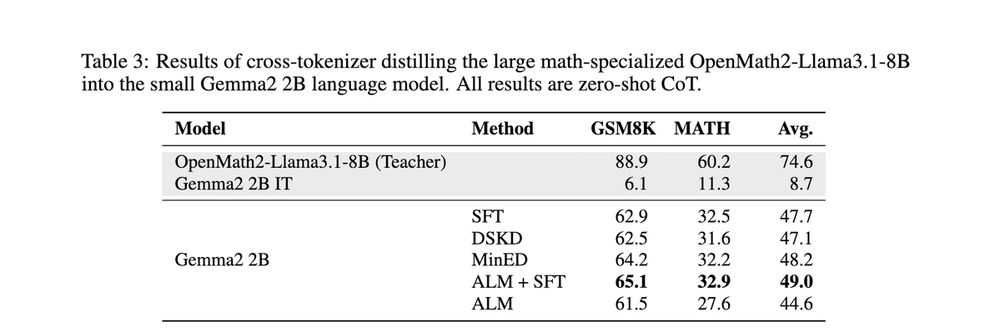
2️⃣We also use ALM to directly transfer knowledge from a large teacher (with one tokenizer) to a smaller student (with another tokenizer).
We test this by distilling a large maths-specialized Llama into a small Gemma model.🔢
02.04.2025 06:39 — 👍 3 🔁 0 💬 1 📌 0
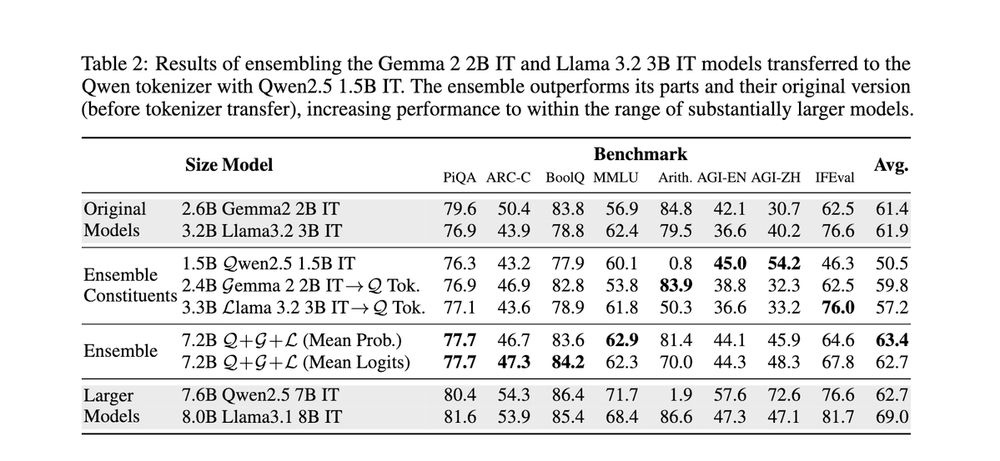
1️⃣continued: we can also transfer different base models to the same tokenizer, then ensemble them by combining their logits.
This would not be possible if they had different tokenizers.
We try ensembling Gemma, Llama and Qwen. They perform better together than separately!🤝
02.04.2025 06:39 — 👍 3 🔁 0 💬 1 📌 0
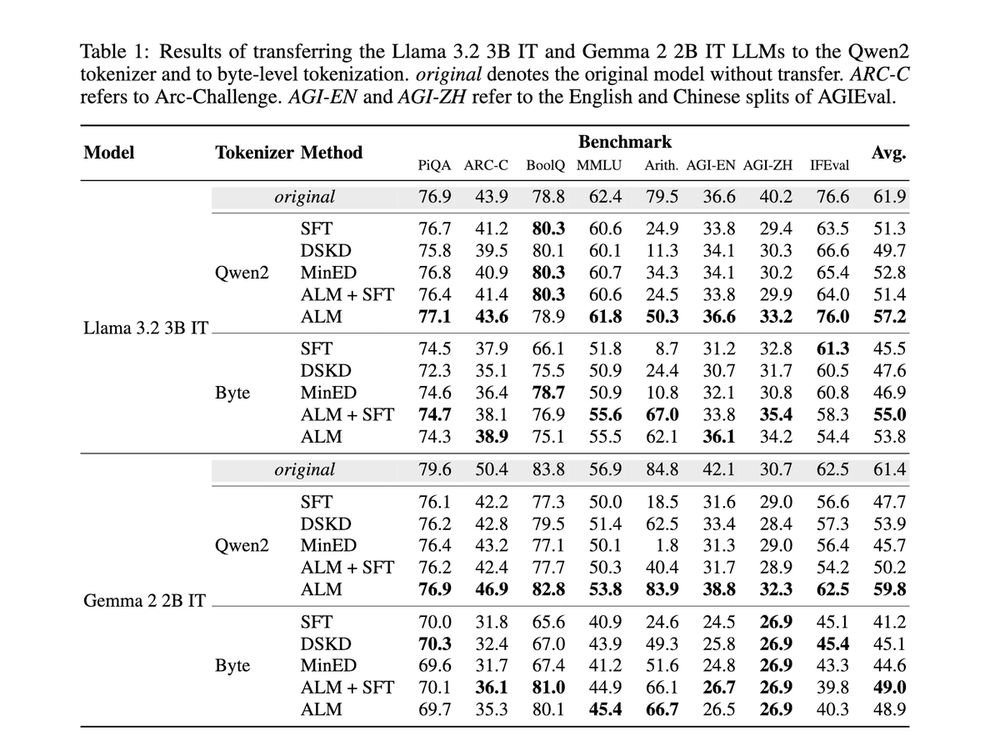
We investigate two use cases of ALM in detail (but there's definitely more!)
1️⃣Tokenizer transfer: the teacher is the model with its original tokenizer; the student is the same model with a new tokenizer.
Here, ALM even lets us distill subword models to a byte-level tokenizer😮
02.04.2025 06:38 — 👍 3 🔁 1 💬 1 📌 0
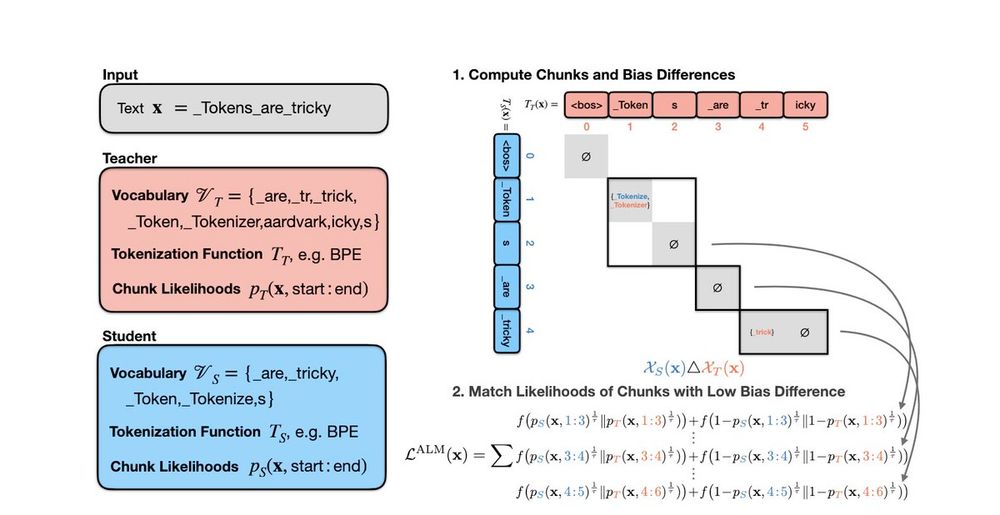
Chunks of tokens with different tokenization biases are not fairly comparable!⚠️⚠️
We thus develop a method to find chunks with low tokenization bias differences (making them *approximately comparable*), then learn to match the likelihoods of those✅
02.04.2025 06:38 — 👍 2 🔁 0 💬 1 📌 0

Our greatest adversary in this endeavour is *tokenization bias*.
Due to tokenization bias, a sequence of subword tokens can leak information about the future contents of the text they encode.
02.04.2025 06:37 — 👍 2 🔁 0 💬 1 📌 0
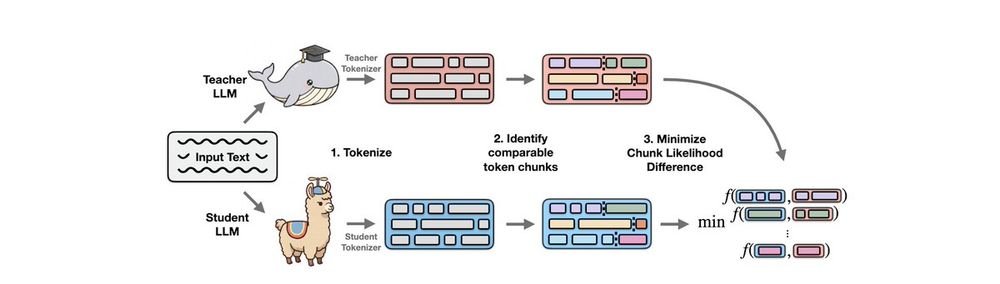
Most distillation methods so far needed the teacher and the student to have the same tokenizer.
We lift this restriction by first identifying comparable chunks of tokens in a sequence (surprisingly, this is not so easy!), then minimizing the difference between their likelihoods.
02.04.2025 06:37 — 👍 2 🔁 0 💬 1 📌 0
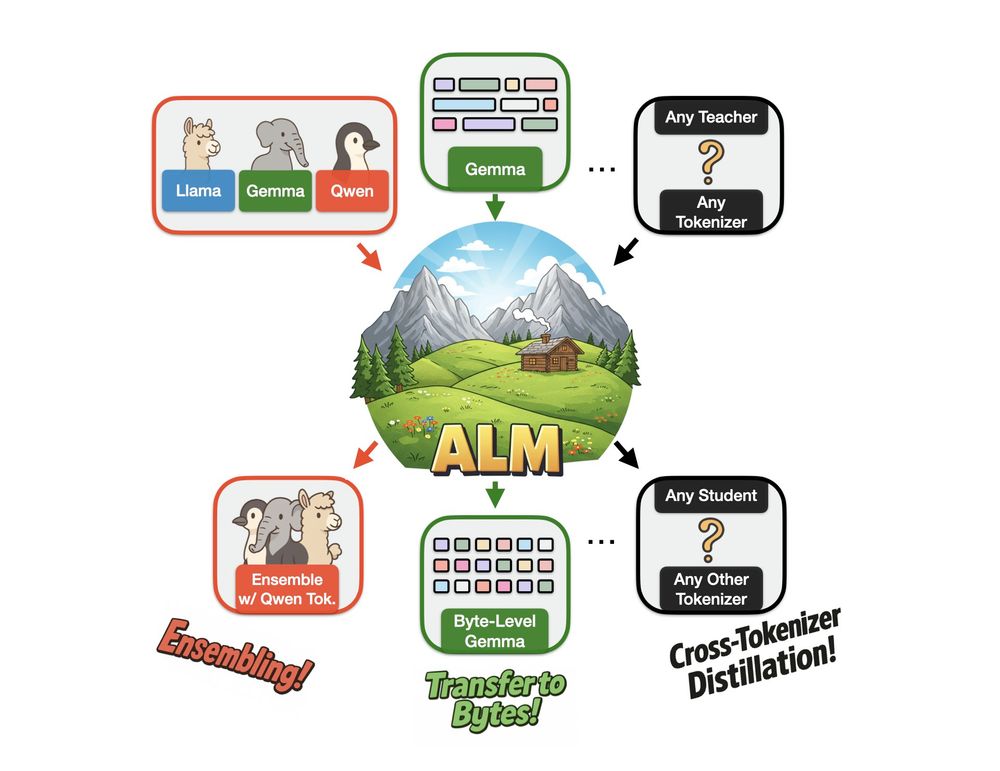
Image illustrating that ALM can enable Ensembling, Transfer to Bytes, and general Cross-Tokenizer Distillation.
We created Approximate Likelihood Matching, a principled (and very effective) method for *cross-tokenizer distillation*!
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
02.04.2025 06:36 — 👍 26 🔁 14 💬 1 📌 0
Two amazing papers from my students at #NeurIPS today:
⛓️💥 Switch the vocabulary and embeddings of your LLM tokenizer zero-shot on the fly (@bminixhofer.bsky.social)
neurips.cc/virtual/2024...
🌊 Align your LLM gradient-free with spectral editing of activations (Yifu Qiu)
neurips.cc/virtual/2024...
12.12.2024 17:45 — 👍 46 🔁 8 💬 2 📌 0
Assistant Professor at @cs.ubc.ca and @vectorinstitute.ai working on Natural Language Processing. Book: https://lostinautomatictranslation.com/
Postdoc @ai2.bsky.social & @uwnlp.bsky.social
PhD Student at LMU Munich. Focus on RL, reward learning and learning from human preferences.
Getting paid to complain about LLM Evaluation at Cohere. #NLP #NLProc
https://dennis-aumiller.de
DeepMind Professor of AI @Oxford
Scientific Director @Aithyra
Chief Scientist @VantAI
ML Lead @ProjectCETI
geometric deep learning, graph neural networks, generative models, molecular design, proteins, bio AI, 🐎 🎶
Working on evaluation of AI models (via human and AI feedback) | PhD candidate @cst.cam.ac.uk
Web: https://arduin.io
Github: https://github.com/rdnfn
Latest project: https://app.feedbackforensics.com
Post-doc @ University of Edinburgh. Working on Synthetic Speech Evaluation at the moment.
🇳🇴 Oslo 🏴 Edinburgh 🇦🇹 Graz
Assistant professor in Natural Language Processing at the University of Edinburgh and visiting professor at NVIDIA | A Kleene star shines on the hour of our meeting.
NLP PhD Student @ University of Cambridge
NLP PhD @ Cambridge Language Technology Lab
paulsbitsandbytes.com
PhD student @ Language Technology Lab, University of Cambridge. Making GPUs go brrrr
PhD student in NLP at Cambridge | ELLIS PhD student
https://lucasresck.github.io/
PhD student at Language Technology Lab, University of Cambridge
ELLIS @ellis.eu Ph.D student at @ukplab.bsky.social and @Cambridge_Uni | Prev. @UofT PSI Lab 🇨🇦
Multicultural, Multilingual, Generalization
https://ccliu2.github.io/
PhD student @CambridgeLTL; Previously @DLAB @EPFL; Interested in NLP and CSS. Apple Scholar, Gates Scholar.
Language Technology Lab (LTL) at the University of Cambridge. Computational Linguistics / Machine Learning / Deep Learning. Focus: Multilingual NLP and Bio NLP.
The Trinity College Library in Cambridge comprises the modern student library, the Wren Library, and significant rare books, manuscript and archive collections.
https://www.trin.cam.ac.uk/library/home/
https://trinitycollegelibrarycambridge.wordpress.com/






















