Interested in a PhD looking at trajectories of repetitive negative thought using machine learning and computational modelling?
Take a look at our project in the @drivehealth.bsky.social portfolio and get in touch with any questions!
showcase.drive-health.org.uk/project/quan...
02.12.2025 13:16 — 👍 11 🔁 8 💬 0 📌 0
⚠️ Warning: Joining our team as a postdoc has a known side effect of receiving multiple job offers shortly after. We currently have 3 such cases.
If you are willing to take that risk, applications close in 1 week. The upside is you'll be in a supportive and stimulating environment in munich.
23.11.2025 14:15 — 👍 12 🔁 1 💬 0 📌 1
Join us in beautiful Munich! If you have any questions about the city, the group or your application, feel free to reach out! ✨
07.11.2025 13:31 — 👍 1 🔁 1 💬 0 📌 0
Model-based exploration is measurable across tasks but not linked to personality and psychiatric assessments
Scientific Reports - Model-based exploration is measurable across tasks but not linked to personality and psychiatric assessments
Publication alert! Our latest paper with @kristinwitte.bsky.social and @ericschulz.bsky.social is out in Scientific Reports: rdcu.be/eydDQ! We explore whether model-based exploration strategies can be used to capture individual differences. Curious how cognitive models meet personality science?
31.07.2025 07:38 — 👍 15 🔁 3 💬 0 📌 0
Beyond thrilled that this work has now been published in Scientific Reports 🎉
rdcu.be/eydDQ
29.07.2025 15:55 — 👍 10 🔁 1 💬 0 📌 0
Re-posting is appreciated: We have a fully funded PhD position in CMC lab @cmc-lab.bsky.social (at @tudresden_de). You can use forms.gle/qiAv5NZ871kv... to send your application and find more information. Deadline is April 30. Find more about CMC lab: cmclab.org and email me if you have questions.
20.02.2025 14:50 — 👍 77 🔁 89 💬 3 📌 8
Join us in Munich as a PhD Student! I've been in this lab for about 4.5 years and still love seeing these people everyday. Feel free to reach out if you have any questions.
11.04.2025 09:00 — 👍 2 🔁 0 💬 0 📌 0
I'm hoping to hire a postdoc this year to join our growing lab at Yale! Looking for someone interested in EMA/digital phenotyping, formal theories, complex systems, & computational psychiatry.
If this sounds like you, please reach out! Official ad coming soon.
07.01.2025 17:53 — 👍 108 🔁 65 💬 0 📌 0
Thank a lot! That is very interesting indeed. We also found that across all tasks the model-free switch probability (probability of choosing a different option than on the previous trial) is more reliable and has greater convergent validity. Very happy to discuss more about this.
11.12.2024 08:49 — 👍 1 🔁 0 💬 0 📌 0
OSF | Sign in
This work was pregistered with the OSF and all code and data is publicly available.
Preregistration: osf.io/cavj3
data and code: osf.io/ra7su/
10.12.2024 09:21 — 👍 1 🔁 0 💬 0 📌 0
In sum, we show that simplified modelling and creating latent factors improves robustness. Still, extracted strategies are more linked to working memory than real-world exploration, raising questions about the validity of few-armed bandit tasks for studying exploration.
10.12.2024 09:21 — 👍 1 🔁 0 💬 1 📌 0

Our changes improved the convergence of exploration strategies across tasks. The latent factors were however still not related to any self-reported measures of exploration or to any psychiatric constructs. They did however show a strong correlation with working memory capacity.
10.12.2024 09:21 — 👍 0 🔁 0 💬 1 📌 0
We subsequently made two main changes to the analyses: 1) We simplified and unified the computational modelling for the Horizon task and the 2-armed bandit. 2) We constructed theoretically informed latent constructs for the exploration strategies across all tasks.
10.12.2024 09:21 — 👍 0 🔁 0 💬 1 📌 0

When using the standard modelling approaches, the test-retest reliability of all model parameters and most task measures was rather poor. We also found low correlations between model parameters from different tasks, despite these parameters measuring the same strategies.
10.12.2024 09:21 — 👍 0 🔁 0 💬 1 📌 0

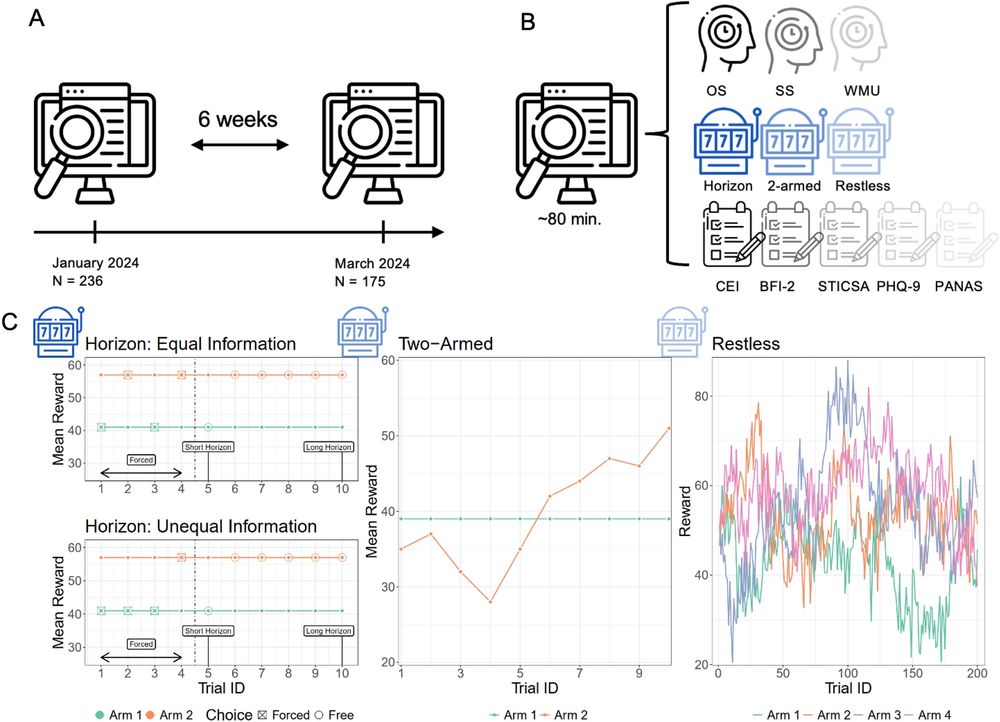
We tested these requirements by collecting data on three bandit tasks, five questionnaires and three working memory tasks. We retested participants on all tasks after 6 weeks, to test for temporal stability.
10.12.2024 09:21 — 👍 0 🔁 0 💬 1 📌 0
This type of approach is very valuable. However, for treating individual differences in model parameters as cognitive traits, we need the model parameters to be:
🕐stable over time
🔗converging across tasks
📋related to real-world exploration
10.12.2024 09:21 — 👍 1 🔁 0 💬 1 📌 0
A growing number of studies uses few-armed bandit tasks to test how people explore. Recently, an increasing body of research (including our own) turned to individual differences in this behaviour and related model parameters to questionnaire measures of psychiatric traits.
10.12.2024 09:21 — 👍 0 🔁 0 💬 1 📌 0
Preprint alert! We explore 3 exploration tasks, testing if they measure a stable construct & its link to real-world exploration. We find improved robustness of latent factors compared to single-task estimates.
With Mirko Thalmann & @ericschulz.bsky.social
🔗https://osf.io/preprints/psyarxiv/tzuey
10.12.2024 09:21 — 👍 29 🔁 12 💬 2 📌 1
Ph.D. in Psychology | Currently on Job Market | saurabhr.github.io
AI technical gov & risk management research. PhD student @MIT_CSAIL, fmr. UK AISI. I'm on the CS faculty job market! https://stephencasper.com/
Recently a principal scientist at Google DeepMind. Joining Anthropic. Most (in)famous for inventing diffusion models. AI + physics + neuroscience + dynamical systems.
UK AI Security Institute
Former Ada Lovelace Institute, Google, DeepMind, OII
AI policy researcher, wife guy in training, fan of cute animals and sci-fi. Started a Substack recently: https://milesbrundage.substack.com/
AI safety at Anthropic, on leave from a faculty job at NYU.
Views not employers'.
I think you should join Giving What We Can.
cims.nyu.edu/~sbowman
Human being. Trying to do good. CEO @ Encultured AI. AI Researcher @ UC Berkeley. Listed bday is approximate ;)
Anthropic and Import AI. Previously OpenAI, Bloomberg, The Register. Weird futures.
AI accountability, audits & eval. Keen on participation & practical outcomes. CS PhDing @UCBerkeley.
Senior Research Scientist at Google DeepMind. AGI Alignment researcher. Views my dog's.
Research Scientist @DeepMind | Previously @OSFellows & @hrdag. RT != endorsements. Opinions Mine. Pronouns: he/him
evals accelerationist, Head of Policy at METR, working hard on responsible scaling policies
Check out my artisanal hand-crafted "AI Bluesky" starter pack here: https://bsky.app/starter-pack/chris.bsky.social/3lbefurb2xh2u
how shall we live together?
societal impacts researcher at Anthropic
saffronhuang.com
METR is a research nonprofit that builds evaluations to empirically test AI systems for capabilities that could threaten catastrophic harm to society.
We are a research institute investigating the trajectory of AI for the benefit of society.
epoch.ai
sentio ergo sum. developing the science of evals at METR. prev NYU, cohere
Alignment Stress-Testing Team Lead at Anthropic. Opinions my own. Previously: MIRI, OpenAI, Google, Yelp, Ripple. (he/him/his)
Research scientist in AI alignment at Google DeepMind. Co-founder of Future of Life Institute. Views are my own and do not represent GDM or FLI.
Researcher at @ox.ac.uk (@summerfieldlab.bsky.social) & @ucberkeleyofficial.bsky.social, working on AI alignment & computational cognitive science. Author of The Alignment Problem, Algorithms to Live By (w. @cocoscilab.bsky.social), & The Most Human Human.
Cognitive scientist working at the intersection of moral cognition and AI safety. Currently: Google Deepmind. Soon: Assistant Prof at NYU Psychology. More at sites.google.com/site/sydneymlevine.



























