Pretrained ViTs usually come in rigid sizes (S, B, L, H). But your hardware constraints don't
We built a way to make DINO or CLIP fully elastic in <5 mins without any retraining ⚡️
Get the exact model size you need, not just what was released
Find Walter at #NeurIPS Poster 4709 | Thu 4:30-7:30 PM
03.12.2025 13:38 — 👍 2 🔁 1 💬 1 📌 0

On the occasion of the 1000th citation of our Sinkhorn-Knopp self-supervised representation learning paper, I've written a whole post about the history and the key bits of this method that powers the state-of-the-art SSL vision models.
Read it here :): docs.google.com/document/d/1...
15.10.2025 10:00 — 👍 18 🔁 4 💬 1 📌 0
Today, we release Franca, a new vision Foundation Model that matches and often outperforms DINOv2.
The data, the training code and the model weights are open-source.
This is the result of a close and fun collaboration
@valeoai.bsky.social (in France) and @funailab.bsky.social (in Franconia)🚀
21.07.2025 14:58 — 👍 21 🔁 4 💬 0 📌 0
Agreed, very interesting! Future engines that run on information? 🤯
23.12.2024 18:24 — 👍 7 🔁 0 💬 0 📌 0
Our Lab is now also on bsky! 🥳
10.12.2024 09:37 — 👍 21 🔁 1 💬 2 📌 0
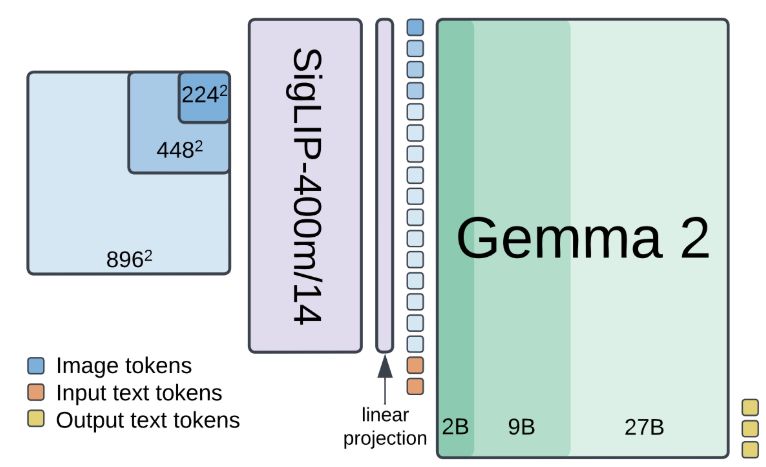
🚀🚀PaliGemma 2 is our updated and improved PaliGemma release using the Gemma 2 models and providing new pre-trained checkpoints for the full cross product of {224px,448px,896px} resolutions and {3B,10B,28B} model sizes.
1/7
05.12.2024 18:16 — 👍 68 🔁 21 💬 1 📌 5
https://tinyurl.com/BristolCVLectureship
Pls RT
Permanent Assistant Professor (Lecturer) position in Computer Vision @bristoluni.bsky.social [DL 6 Jan 2025]
This is a research+teaching permanent post within MaVi group uob-mavi.github.io in Computer Science. Suitable for strong postdocs or exceptional PhD graduates.
t.co/k7sRRyfx9o
1/2
04.12.2024 17:22 — 👍 23 🔁 14 💬 1 📌 1
Also @phdcomics.bsky.social is on 🦋 👏. slowly nesting here.
27.11.2024 08:25 — 👍 4 🔁 0 💬 0 📌 0
Yay, @xkcd.com is on 🦋
27.11.2024 07:54 — 👍 2 🔁 0 💬 0 📌 0
Nice 👏! We love small (M)LLMs :) will training code also be released?
26.11.2024 19:13 — 👍 3 🔁 1 💬 0 📌 0

Sam next to his poster; I'm still very impressed he did all this for his MSc thesis! #BMVC2024
26.11.2024 10:25 — 👍 5 🔁 1 💬 0 📌 0
exactly. hence the new post-(pre)training term perhaps? post-training seems to be a good generic term for the RLHF/preference tuning etc in NLP allenai.org/papers/tulu-.... so by saying post-pretraining, we could emphasize the fact it's unsupervised
26.11.2024 08:30 — 👍 1 🔁 0 💬 0 📌 0
"Post-pretraining", "unsupervised domain adaptation" fits, but I think is used for different tasks
26.11.2024 08:01 — 👍 2 🔁 0 💬 2 📌 0


This means we can simply send an adapted RGB image to the server to get a personalised output.
We also show that the gains don't just come from adding a new learnable model, but instead from the interplay between the pretrained one and the PGN.
26.11.2024 07:28 — 👍 2 🔁 0 💬 1 📌 0

This CNN (e.g. running on a phone) outputs a softmax over a set of learned tokens. These are then combined and used for the adaptation. This allows efficient learning, but also for moving the signal back into pixel-space via pseudo-inverse.
26.11.2024 07:28 — 👍 1 🔁 0 💬 1 📌 0

Also known as reprogramming, works from @phillipisola.bsky.social showed that even adjusting singular pixels allows adapting a model. We take this one step further and make the input-only adaptation signal dependent on the image itself: We introduce a lightweight CNN, the Prompt Generation Network.
26.11.2024 07:28 — 👍 4 🔁 0 💬 2 📌 0
LoRA is great but one disadvantage is that if you have 1000s of these adapters and want to serve them in an efficient way, it's very difficult: GPUs are inefficient when you e.g. use one adapter for only one sample in a large batch. The solution is to adapt the model strictly in input-space.
26.11.2024 07:28 — 👍 3 🔁 0 💬 1 📌 0
LoRA et al. enable personalised model generation and serving, which is crucial as finetuned models still outperform general ones in many tasks. However, serving a base model with many LoRAs is very inefficient! Now, there's a better way: enter Prompt Generation Networks, presented today #BMVC
26.11.2024 07:28 — 👍 31 🔁 5 💬 1 📌 0
Hello world!
Is there any tool to sync twitter and bluesky posting?
20.11.2024 20:53 — 👍 3 🔁 0 💬 1 📌 0
My growing list of #computervision researchers on Bsky.
Missed you? Let me know.
go.bsky.app/M7HGC3Y
19.11.2024 23:00 — 👍 131 🔁 42 💬 88 📌 9

Sky Follower Bridge - Chrome Web Store
Instantly find and follow the same users from your Twitter follows on Bluesky.
The thingie that brings over your twitter followers worked jolly well for me. Very cool! I am following another 500 people now thanks to that…
chromewebstore.google.com/detail/sky-f...
19.11.2024 10:28 — 👍 150 🔁 10 💬 13 📌 4
San Diego Dec 2-7, 25 and Mexico City Nov 30-Dec 5, 25. Comments to this account are not monitored. Please send feedback to townhall@neurips.cc.
Assistant Professor at Leiden University, NL. Computer Vision, Video Understanding.
https://hazeldoughty.github.io
Comics by Jorge Cham: Oliver's Great Big Universe, Elinor Wonders Why, ScienceStuff and PHD Comics
Probabilistic ML researcher at Google Deepmind
Assistant Professor at the University of Cambridge @eng.cam.ac.uk, working on 3D computer vision and inverse graphics, previously postdoc at Stanford and PhD at Oxford @oxford-vgg.bsky.social
https://elliottwu.com/
Associate professor @ Cornell Tech
Principal research scientist at Google DeepMind. Synthesized views are my own.
📍SF Bay Area 🔗 http://jonbarron.info
This feed is a mostly-incomplete mirror of https://x.com/jon_barron, I recommend you just follow me there.
Bot. I daily tweet progress towards machine learning and computer vision conference deadlines. Maintained by @chriswolfvision.bsky.social
Head of the Computer Vision lab; TU Delft.
- Fundamental empirical Deep Learning research
- Visual inductive priors for data efficiency
Web: https://jvgemert.github.io/
Computer Vision & Machine Learning
📍 Pioneer Centre for AI, University of Copenhagen
🌐 https://www.belongielab.org
Associate Professor in EECS at MIT. Neural nets, generative models, representation learning, computer vision, robotics, cog sci, AI.
https://web.mit.edu/phillipi/
Professor, University Of Copenhagen 🇩🇰 PI @belongielab.org 🕵️♂️ Director @aicentre.dk 🤖 Board member @ellis.eu 🇪🇺 Formerly: Cornell, Google, UCSD
#ComputerVision #MachineLearning
Interpretable Deep Networks. http://baulab.info/ @davidbau
Research Scientist Meta/FAIR, Prof. University of Geneva, co-founder Neural Concept SA. I like reality.
https://fleuret.org
www.dgp.toronto.edu/~hertzman
Professor at Columbia. Computer Vision and Machine Learning
Research Scientist at valeo.ai | Teaching at Polytechnique, ENS | Alumni at Mines Paris, Inria, ENS | AI for Autonomous Driving, Computer Vision, Machine Learning | Robotics amateur
⚲ Paris, France 🔗 abursuc.github.io
Distinguished Scientist at Google. Computational Imaging, Machine Learning, and Vision. Posts are personal opinions. May change or disappear over time.
http://milanfar.org
Director, Max Planck Institute for Intelligent Systems; Chief Scientist Meshcapade; Speaker, Cyber Valley.
Building 3D humans.
https://ps.is.mpg.de/person/black
https://meshcapade.com/
https://scholar.google.com/citations?user=6NjbexEAAAAJ&hl=en&oi=ao