
🚀Proud to share our work on the training dynamics in Transformers with Wassim Bouaziz & @viviencabannes.bsky.social @Inria @MetaAI
📝Easing Optimization Paths arxiv.org/pdf/2501.02362 (accepted @ICASSP 2025 🥳)
📝Clustering Heads 🔥https://arxiv.org/pdf/2410.24050
🖥️ github.com/facebookrese...
1/🧵
04.02.2025 11:56 — 👍 5 🔁 4 💬 1 📌 1

Dumb and Dumber gif: Jim Carrey plugging his ears while his companion babbles at him about something.
On top of Jim, it says "Me, Writing ICML Papers"
On top of his babbling companion, it says "DeepSeek Takes".
28.01.2025 18:42 — 👍 62 🔁 2 💬 2 📌 1
The bottom-up approach, starting from simpler systems, is much more interesting imo.
Studying how intelligence emerges naturally from simple rules is much more likely to teach us how intelligence arose in the first place.
2/2
19.01.2025 19:53 — 👍 0 🔁 0 💬 0 📌 0
LLMs and today's AI research chase top-down intelligence through abstract reasoning. This path might get us to AGI faster but I don’t think it will help us understand how intelligence emerged in nature.
1/2
19.01.2025 19:53 — 👍 0 🔁 0 💬 1 📌 0
3- Ultimately, I believe we won't get to AGI until we solve the deeper challenge: giving true agency and meaning to these machines.
3/3
22.12.2024 13:49 — 👍 1 🔁 0 💬 0 📌 0
2- @garymarcus.bsky.social raises a valid point: solving ARC through training isn't true AGI, and such claims are mainly hype. Real AGI should tackle these puzzles through reasoning alone, like humans do - not by optimizing for the benchmark. And I agree with it.
2/3
22.12.2024 13:49 — 👍 1 🔁 0 💬 1 📌 0
I am usually quite critical of LLM hypey breakthroughs, but I don’t see an issue with OpenAI training on ARC.
There is an issue, but it’s more fundamental and multifaceted.
1- As it’s often the case, the benchmark here has become the goal. @fchollet.bsky.social also said solving ARC != AGI
1/3
22.12.2024 13:49 — 👍 2 🔁 0 💬 1 📌 0
By not doing research only on LLMs ;)
22.12.2024 13:44 — 👍 3 🔁 0 💬 0 📌 0
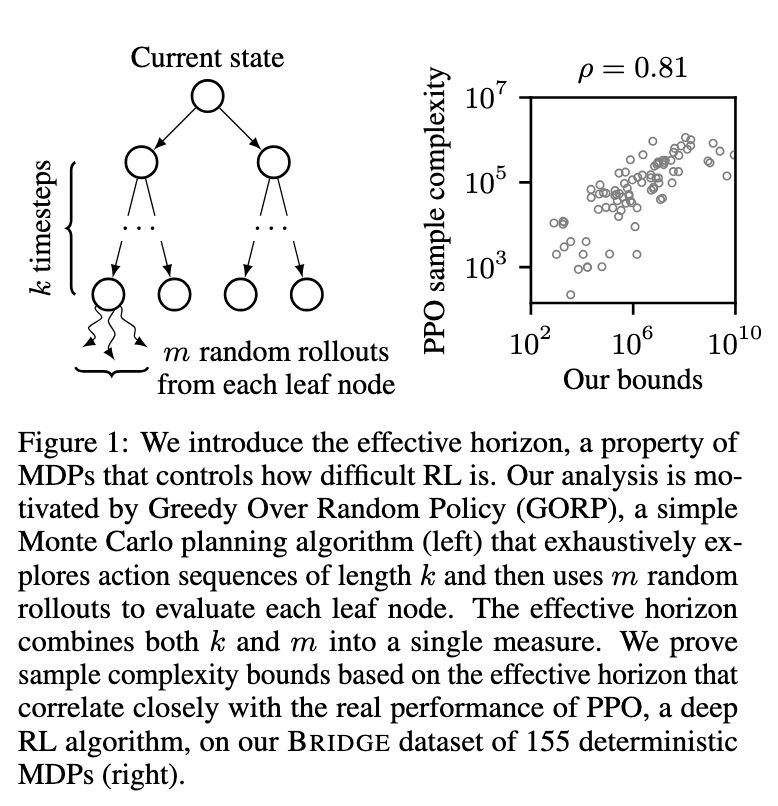
e introduce the effective horizon, a property of
MDPs that controls how difficult RL is. Our analysis is mo-
tivated by Greedy Over Random Policy (GORP), a simple
Monte Carlo planning algorithm (left) that exhaustively ex-
plores action sequences of length k and then uses m random
rollouts to evaluate each leaf node. The effective horizon
combines both k and m into a single measure. We prove
sample complexity bounds based on the effective horizon that
correlate closely with the real performance of PPO, a deep
RL algorithm, on our BRIDGE dataset of 155 deterministic
MDPs (right).
Kind of a broken record here but proceedings.neurips.cc/paper_files/...
is totally fascinating in that it postulates two underlying, measurable structures that you can use to assess if RL will be easy or hard in an environment
23.11.2024 18:18 — 👍 151 🔁 28 💬 8 📌 2
🤩
23.11.2024 11:30 — 👍 0 🔁 0 💬 0 📌 0
When I was 5, I loved science, which I took to be planets and magnets and chemicals and shit.
Soon I realized science was a collective human activity, and these were just the objects of its attention.
Anyway, whenever I read an OpEd on how science isn't political, I think "Are you 5 years old?"
22.11.2024 04:32 — 👍 8079 🔁 1240 💬 136 📌 65
I could note find any paper or work proposing AI frameworks like this.
I suppose cause it's hard, but maybe I am missing something?
21.11.2024 16:24 — 👍 0 🔁 0 💬 0 📌 0
Since discovering @drmichaellevin.bsky.social work, I have been fascinated by hierarchical multi-agent systems in which the hierarchy develops across different ontological levels.
So hierarchy that goes
engineers -> the company they work for,
rather than
engineers -> their boss.
21.11.2024 16:24 — 👍 3 🔁 1 💬 1 📌 0
Right on point, as I am getting more and more interested in this topic :)
21.11.2024 15:56 — 👍 1 🔁 0 💬 0 📌 0
If you're an RL researcher or RL adjacent, pipe up to make sure I've added you here!
go.bsky.app/3WPHcHg
09.11.2024 16:42 — 👍 70 🔁 26 💬 52 📌 0
Not sure another social media app will increase my productivity.
But at least I can justify this one as useful for work.
21.11.2024 14:37 — 👍 4 🔁 0 💬 0 📌 0
Researcher at Inria. Simulating the origins of life, cognition and culture. Using methods from ALife and AI.
Publications: https://scholar.google.com/citations?hl=en&user=rBnV60QAAAAJ&view_op=list_works&sortby=pubdate
Prev. posts still on X same username
Research Engineer @ Huawei. Previously @ Inria Flowers
Interested in ML, RL, Multi-agent systems & LLMs
https://corentinlger.github.io/
PhD Student at Technical University of Madrid (UPM) | Reinforcement Learning, decision-making & control, Autonomous Systems.🤖
L'account ufficiale del Post (ilpost.it)
Strengthening Europe's Leadership in AI through Research Excellence | ellis.eu
Professor a NYU; Chief AI Scientist at Meta.
Researcher in AI, Machine Learning, Robotics, etc.
ACM Turing Award Laureate.
http://yann.lecun.com
Associate Professor at Polytechnique Montreal and Mila.
Assistant Professor @Princeton. Developing robots that plan and learn to help people. Prev: @Cornell, @MIT, @Harvard.
https://tomsilver.github.io/
Assistant Prof at @UMontreal @mila-quebec.bsky.social @MontrealRobots
. CIFAR AI Chair, RL_Conference chair. Creating generalist problem-solving agents for the real world. He/him/il.
Scientist @ DeepMind and Honorary Fellow @ U of Edinburgh.
RL, agency, philosophy, foundations, AI.
https://david-abel.github.io
AI Scientist | Professor | Techno-Optimist
chriskanan.com
Professor for Lifelong Machine Learning @ Uni Bremen | OWL-ML Lab: https://owl-ml.com | Board @ ContinualAI | QueerInAI | CoLLAs 2026 Program Chair | He/him 🏳️🌈🇪🇺
FAIR Researcher @metaai.bsky.social Previously Mila-Quebec, Microsoft Research, Adobe Research, IIT Roorkee
Associate Professor @ Georgia Tech
computer vision & robotics/embodied AI
http://faculty.cc.gatech.edu/~zk15
👾 Research Scientist, Google Deepmind, Affiliate Faculty Mila.
🎓Ph.D. Reasoning and Learning Lab, McGill University, Mila.
🐀Researcher in Reinforcement Learning
📸 Enjoys Photography
🤖 Build Things
👩🏫 Educator and Mentor
PhD student at UW, NLP + ML
day-time ML researcher 💻, night-time confused thinker 🤔, sharp 3-point shooter 🏀. postdoc @ tübingen 🇩🇪, was phd @ aalto 🇫🇮 and msc @ bogazici 🇹🇷. istanbul lover.
Research in AI / ML / RL @Mila_Quebec / @UMontreal, formerly research @Ualberta, @AmiiThinks, @rlai_lab



















