With GDM friends Adam Fisch, @jonathanberant.bsky.social, Alekh Agarwal, and special guest Anastasios Angelopoulos.
10.06.2025 15:24 — 👍 2 🔁 1 💬 0 📌 0
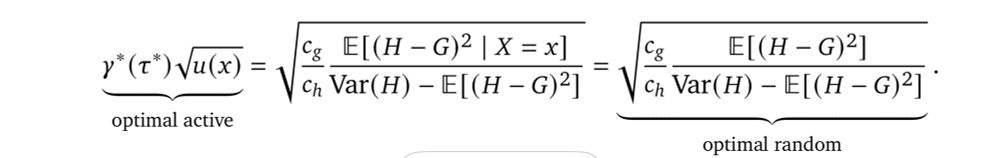
We offer cost-optimal policies for selecting which rater should annotate which examples, which link the cost, the annotation noise, and the *uncertainty* of the cheaper rater.
10.06.2025 15:24 — 👍 1 🔁 1 💬 1 📌 0
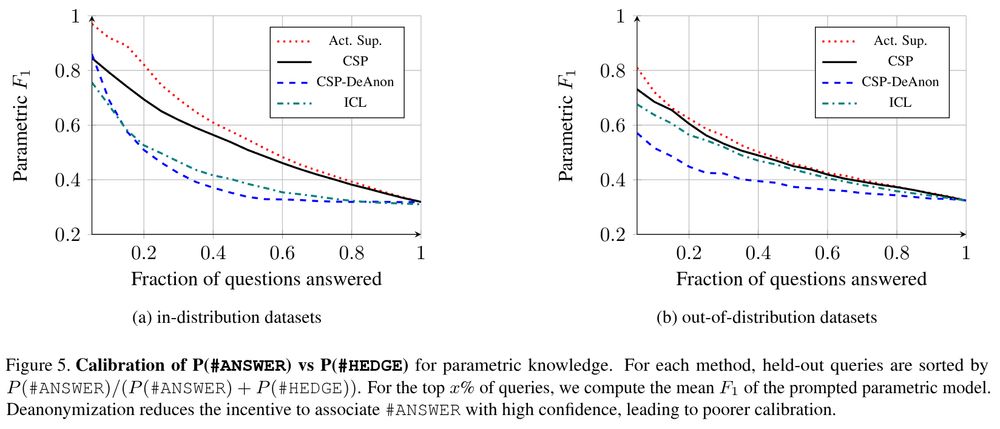
calibration of p(answer), which is learned only when the helper identity is anonymized
An ablation reveals the importance of mechanism design: when the helper identities are known to the asker during training (CSP-DeAnon), calibrated hedging is no longer learned.
24.03.2025 15:39 — 👍 6 🔁 1 💬 1 📌 0
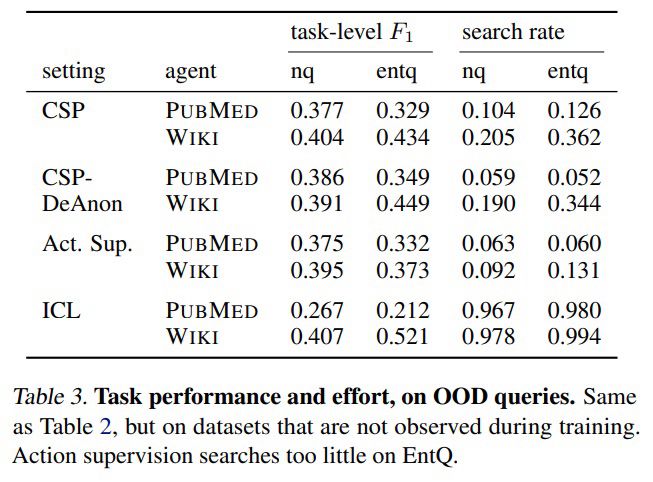
task f1 and tool use
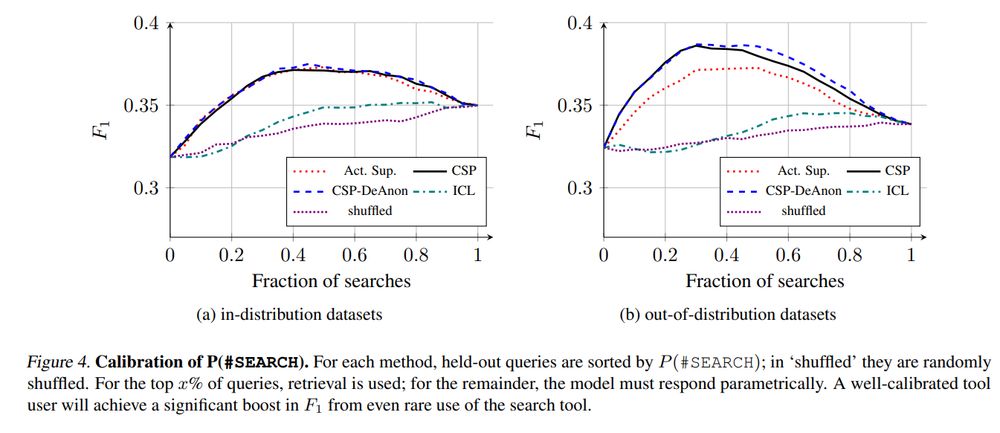
calibration curves for tool use, showing that collaborative self play teaches when to use the retrieval tools
In practice, collaborative self-play + reinforced self-training (ReST) lead to improved task performance, better calibration of confidence markers, and more efficient tool use.
24.03.2025 15:39 — 👍 5 🔁 1 💬 2 📌 0
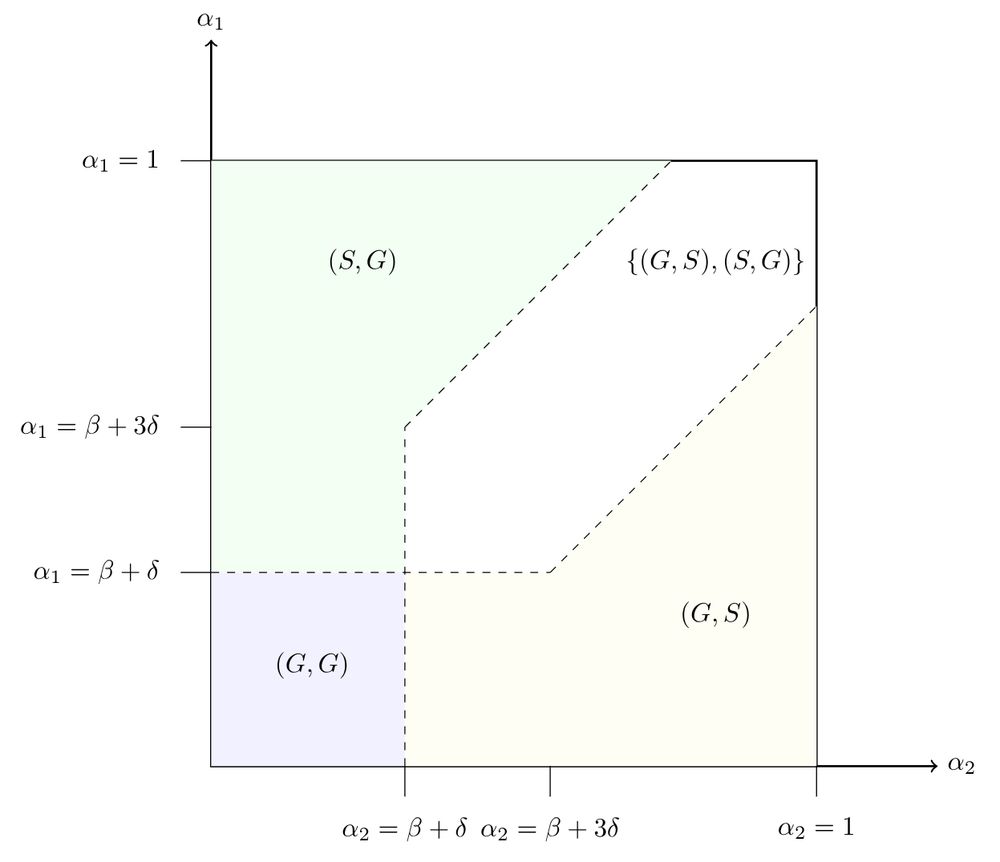
illustration of the equilibria of the formal model of costly information provision
A bit of game theory can help explain when this can work: we model the setup as a game of public utility provision, where the public utility is the extra information provided by the costly retrieval action. The game has a unique equilibrium when the tools are sufficiently distinct (or both bad).
24.03.2025 15:39 — 👍 4 🔁 1 💬 1 📌 0

an example rollout, in which the asker receives contrasting advice from its helpers, and must rely on their confidence to find the accurate response
Because the identity of each helper is hidden from the asker, it is forced to rely on confidence signals when faced with incompatible answers from the helpers. Maximizing effort-penalized accuracy of the full rollout can teach the LLM to use these confidence markers correctly.
24.03.2025 15:39 — 👍 3 🔁 1 💬 1 📌 0
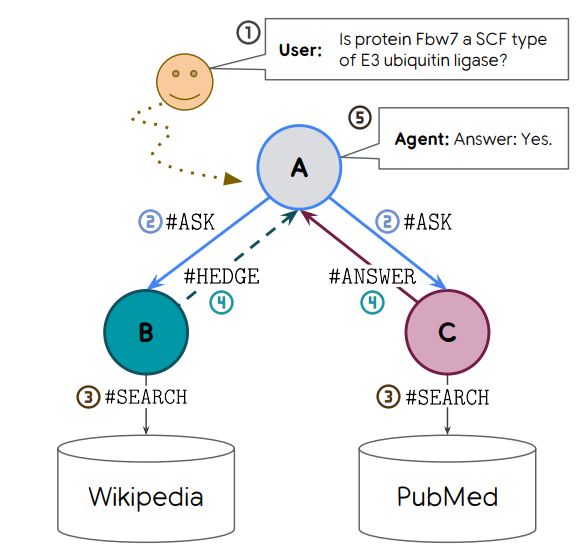
schematic illustrating the collaborative self play scenario
We focus on two capabilities: knowing when to use a costly retrieval tool, and hedging non-confident answers. To teach these capabilities, we create a small multi-agent society, in which two "helpers" can use specialized retrieval tools to pass information back to an "asker"
24.03.2025 15:39 — 👍 5 🔁 1 💬 1 📌 0

Don't lie to your friends: Learning what you know from collaborative self-play
Jacob Eisenstein, Reza Aghajani, Adam Fisch, Dheeru Dua, Fantine Huot, Mirella Lapata, Vicky Zayats, Jonathan Berant
To be helpful assistants, AI agents must be aware of their own capabilities and limitations. This includes knowing when to answer from parametric knowledge versus using tools, when to trust tool outputs, and when to abstain or hedge. Such capabilities are hard to teach through supervised fine-tuning because they require constructing examples that reflect the agent's specific capabilities. We therefore propose a radically new approach to teaching agents what they know: \emph{collaborative self-play}. We construct multi-agent collaborations in which the group is rewarded for collectively arriving at correct answers. The desired meta-knowledge emerges from the incentives built into the structure of the interaction. We focus on small societies of agents that have access to heterogeneous tools (corpus-specific retrieval), and therefore must collaborate to maximize their success while minimizing their effort. Experiments show that group-level rewards for multi-agent communities can induce policies that \emph{transfer} to improve tool use and selective prediction in settings where individual agents are deployed in isolation.
A way to help models "be aware of their own capabilities and limitations" from @jacobeisenstein.bsky.social et al: arxiv.org/abs/2503.14481 #MLSky
22.03.2025 16:09 — 👍 40 🔁 9 💬 3 📌 0
Fun work led by @amouyalsamuel.bsky.social and with Aya. Coming in I didn't think LLMs should have difficulties with answering questions on some of the GP sentences we used, but turns out they had! See Samuel's thread for more info...
12.03.2025 19:23 — 👍 0 🔁 0 💬 0 📌 0

One intriguing follow-up: some component of the sentence understanding cognitive model fails on GP sentence. Is this component also present in LLMs? If not, then why so many LLMs are influenced by our manipulations in the same way humans are?
12.03.2025 19:12 — 👍 1 🔁 1 💬 1 📌 0

There are many more cool insights you can find in our paper.
One takeaway from this paper for the psycholinguistics community: run your reading comprehension experiment on LLM first. You might get a general idea of the human results.
(Last image I swear)
12.03.2025 19:12 — 👍 1 🔁 1 💬 1 📌 0

These experiments replicated the results from the sentence comprehension one: our manipulations had the same effect on the paraphrase or drawing correctness as they had on the sentence comprehension task.
In this image: While the teacher taught the puppies looked at the board.
12.03.2025 19:12 — 👍 1 🔁 1 💬 2 📌 0

We also ran two additional experiments with LLMs that are challenging to perform on humans.
1. We asked the LLM to paraphrase our sentence
2. We asked text-to-image models to draw the sentences
In this image: While the horse pulled the submarine moved silently.
12.03.2025 19:12 — 👍 2 🔁 1 💬 1 📌 0
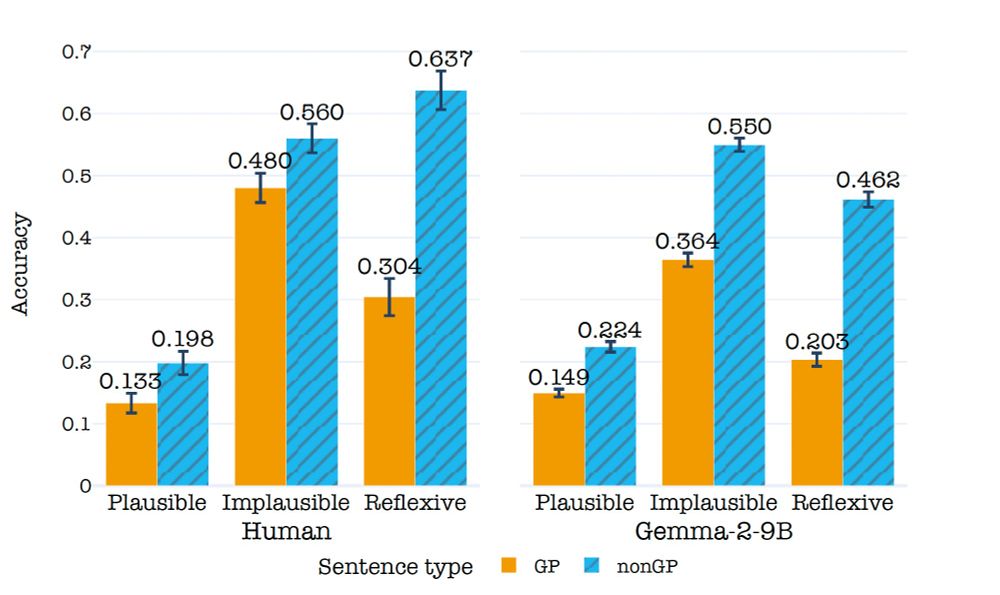
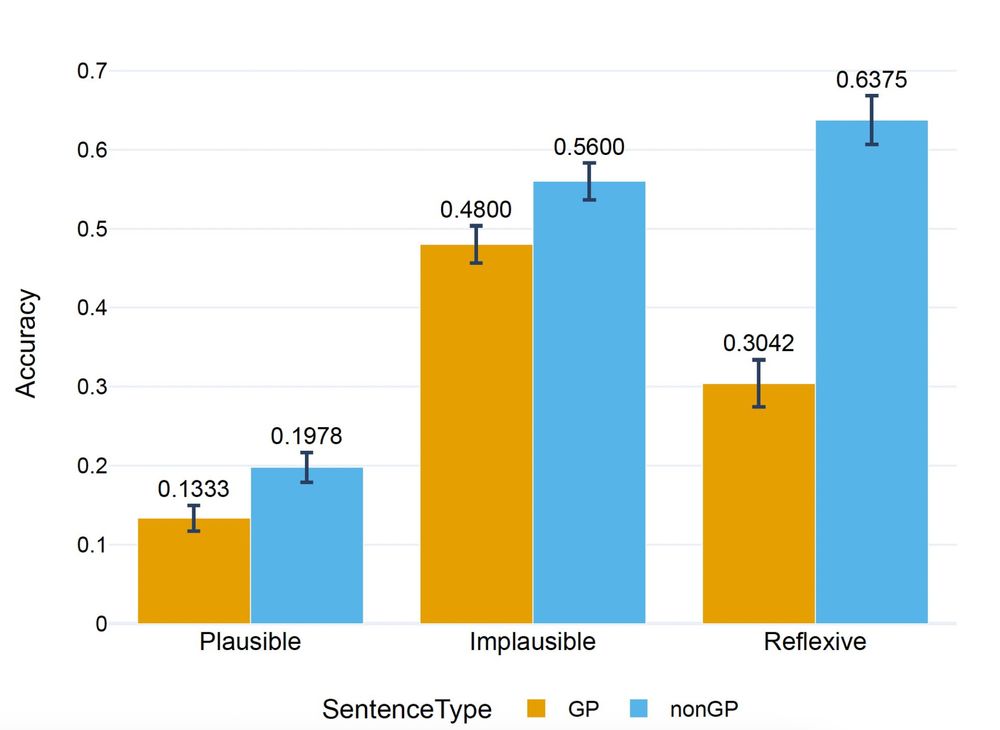
To answer our second question, we ran the same sentence comprehension experiment we ran on humans with over 60 LLMs.
We found that LLMs also struggle with GP sentences and that, interestingly, the manipulations we did to test our hypotheses impacted LLMs as they did with humans
12.03.2025 19:12 — 👍 1 🔁 1 💬 1 📌 0
In our latest paper with Aya Meltzer-Asscher and @jonathanberant.bsky.social, we try to answer both these questions.
We devise hypotheses explaining why GP sentences are harder to process and test them. Human subjects answered a reading comprehension question about a sentence they read.
12.03.2025 19:12 — 👍 1 🔁 1 💬 1 📌 0
The old man the boat.
You probably had to read that sentence twice. It's because it's a garden path (GP) sentence. GP sentences are read slower and often misunderstood. This begs the questions:
1. Why are these sentences harder to process?
2. How do LLMs deal with them?
12.03.2025 19:12 — 👍 1 🔁 1 💬 1 📌 1

Inference-time procedures (e.g. Best-of-N, CoT) have been instrumental to recent development of LLMs. Standard RLHF focuses only on improving the trained model. This creates a train/inference mismatch.
𝘊𝘢𝘯 𝘸𝘦 𝘢𝘭𝘪𝘨𝘯 𝘰𝘶𝘳 𝘮𝘰𝘥𝘦𝘭 𝘵𝘰 𝘣𝘦𝘵𝘵𝘦𝘳 𝘴𝘶𝘪𝘵 𝘢 𝘨𝘪𝘷𝘦𝘯 𝘪𝘯𝘧𝘦𝘳𝘦𝘯𝘤𝘦-𝘵𝘪𝘮𝘦 𝘱𝘳𝘰𝘤𝘦𝘥𝘶𝘳𝘦?
Check out below.
11.02.2025 16:26 — 👍 25 🔁 6 💬 1 📌 4

InfAlign: Inference-aware language model alignment
Ananth Balashankar, Ziteng Sun, Jonathan Berant, Jacob Eisenstein, Michael Collins, Adrian Hutter, Jong Lee, Chirag Nagpal, Flavien Prost, Aradhana Sinha, Ananda Theertha Suresh, Ahmad Beirami
Excited to share 𝐈𝐧𝐟𝐀𝐥𝐢𝐠𝐧!
Alignment optimization objective implicitly assumes 𝘴𝘢𝘮𝘱𝘭𝘪𝘯𝘨 from the resulting aligned model. But we are increasingly using different and sometimes sophisticated inference-time compute algorithms.
How to resolve this discrepancy?🧵
01.01.2025 19:59 — 👍 55 🔁 11 💬 2 📌 1
Sure, but the take that "we should allow people to publicly make such comments because otherwise we would never know that the problem exists" seems odd to me, and I assume that is not your claim.
14.12.2024 18:54 — 👍 1 🔁 0 💬 1 📌 0
I haven't either don't know if such discussions exist or not.
14.12.2024 18:46 — 👍 0 🔁 0 💬 1 📌 0
Others shouldn't speak similarly, this doesn't seem like "hiding" to me. You can be aware of problems and discuss them appropriately and that is orthogonal to expecting public speakers to not make such offhand comments (when bias is not even the topic of discussion)
14.12.2024 18:41 — 👍 0 🔁 0 💬 1 📌 0
I think he only said the first part?
13.12.2024 23:50 — 👍 0 🔁 0 💬 0 📌 0

We’re really excited to release this large collaborative work for unifying web agent benchmarks under the same roof.
In this TMLR paper, we dive in-depth into #BrowserGym and #AgentLab. We also present some unexpected performances from Claude 3.5-Sonnet
12.12.2024 17:55 — 👍 20 🔁 11 💬 1 📌 2
Really curious to know how all this turned out keep reporting!
12.12.2024 04:49 — 👍 0 🔁 0 💬 0 📌 0
I will also be at NeurIPS! Happy to chat about post-training, reasoning, and interesting ways you use multiple agents for things.
09.12.2024 19:34 — 👍 1 🔁 0 💬 0 📌 0
Google Chief Scientist, Gemini Lead. Opinions stated here are my own, not those of Google. Gemini, TensorFlow, MapReduce, Bigtable, Spanner, ML things, ...
Assist. Prof.@OhioState, co-director OSU NLP. I like to think about intelligence and manifest it into language agents
MegaSenior Research Scientist at ServiceNow Research, Former Google. WebAgents, Remote Sensing, Climate Change, Opinions are my own
Researcher in NLP, ML, computer music. Prof @uwcse @uwnlp & helper @allen_ai @ai2_allennlp & familiar to two cats. Single reeds, tango, swim, run, cocktails, מאַמע־לשון, GenX. Opinions not your business.
Associate Professor at Utah. Work on NLP, ML, AI. https://svivek.com
Research Scientist at Google DeepMind working on Gemini and Adaptive Compute LLMs
#NLP research @ai2.bsky.social; OLMo post-training
https://pdasigi.github.io/
Postdoctoral Fellow at Princeton Language and Intelligence | Past: Computer Science PhD at Tel Aviv University & Apple Scholar in AI/ML | Interested in the foundations of deep learning
https://noamrazin.github.io/
PhD student at @cmurobotics.bsky.social working on efficient algorithms for interactive learning (e.g. imitation / RL / RLHF). no model is an island. prefers email. https://gokul.dev/. on the job market!
Incoming asst professor at MIT EECS, Fall 2025. Research scientist at Databricks. CS PhD @StanfordNLP.bsky.social. Author of ColBERT.ai & DSPy.ai.
NLP, Linguistics, Cognitive Science, AI, ML, etc.
Job currently: Research Scientist (NYC)
Job formerly: NYU Linguistics, MSU Linguistics
Computational semantics and pragmatics, interpretability and occasionally some psycholinguistics. he/him. 🦝
https://sebschu.com
NLP PhD Candidate at Tel Aviv University (Google PhD Fellow) | Working on LLM reasoning and Language Agents | Prev. Research intern at Meta FAIR and AI2
The Association for Computational Linguistics (ACL) is a scientific and professional organization for people working on Natural Language Processing/Computational Linguistics.
Hash tags: #NLProc #ACL2026NLP
Chief AI Scientist at Databricks. Founding team at MosaicML. MIT/Princeton alum. Lottery ticket enthusiast. Working on data intelligence.
AI safety at Anthropic, on leave from a faculty job at NYU.
Views not employers'.
I think you should join Giving What We Can.
cims.nyu.edu/~sbowman
Research in NLP (mostly LM interpretability & explainability).
Assistant prof at UMD CS + CLIP.
Previously @ai2.bsky.social @uwnlp.bsky.social
Views my own.
sarahwie.github.io






















