
We’re updating olmOCR, our model for turning PDFs & scans into clean text with support for tables, equations, handwriting, & more. olmOCR 2 uses synthetic data + unit tests as verifiable rewards to reach state-of-the-art performance on challenging documents. 🧵
22.10.2025 16:09 —
👍 37
🔁 6
💬 1
📌 3
Introducing OLMo-2-0325-32B-Instruct! It's the spring RL curve time. This time, we used GRPO for RLVR and trained a pretty nice fully open source model!
13.03.2025 19:19 —
👍 12
🔁 1
💬 1
📌 0
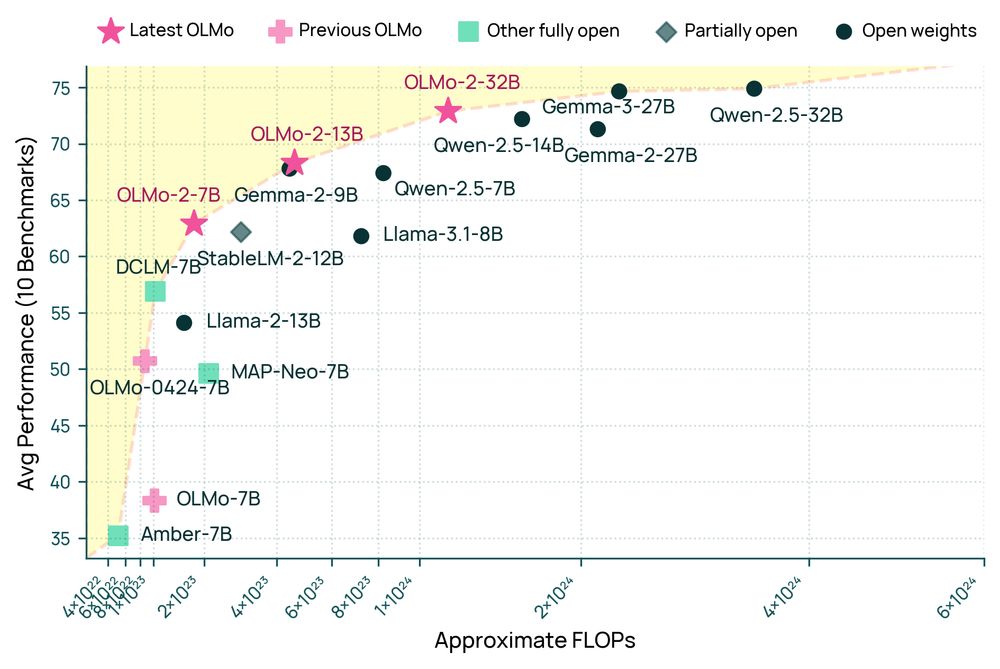
Announcing OLMo 2 32B: the first fully open model to beat GPT 3.5 & GPT-4o mini on a suite of popular, multi-skill benchmarks.
Comparable to best open-weight models, but a fraction of training compute. When you have a good recipe, ✨ magical things happen when you scale it up!
13.03.2025 18:36 —
👍 58
🔁 15
💬 3
📌 3
How to curate instruction tuning datasets while targeting specific skills? This is a common question developers face while post-training LMs.
In this work led by @hamishivi.bsky.social we found that simple embedding based methods scale much better than fancier computationally intensive ones.
04.03.2025 19:20 —
👍 1
🔁 0
💬 0
📌 0
also some other tülu contributors are on the market:
@ljvmiranda.bsky.social (ljvmiranda921.github.io) and Xinxi Lyu (alrope123.github.io) are also applying to phd programs, and @valentinapy.bsky.social (valentinapy.github.io) is on the faculty market, hire them all!!
30.01.2025 19:25 —
👍 1
🔁 1
💬 0
📌 0
Here's a significant update to Tülu 3: we scaled up the post-training recipe to Llama 3.1 405B. Tülu 3 405B beats Llama's 405B instruct model and also Deepseek V3.
Huge shoutout to @hamishivi.bsky.social and @vwxyzjn.bsky.social who led the scale up, and to the rest of the team!
30.01.2025 19:21 —
👍 7
🔁 0
💬 0
📌 0
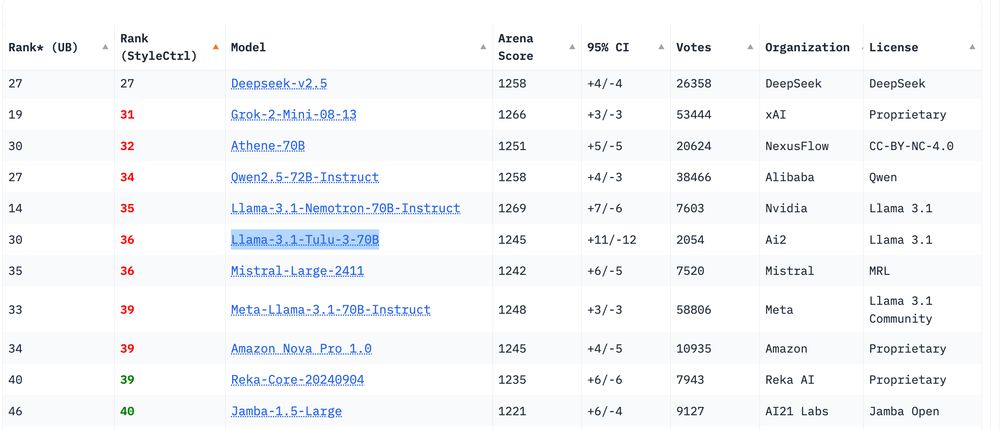
Very pleased to see Tulu 3 70B more or less tied with Llama 3.1 70B Instruct on style controlled ChatBotArena. The only model anywhere close to that with open code and data for post-training! Lots of stuff people can build on.
Next looking for OLMo 2 numbers.
08.01.2025 17:13 —
👍 24
🔁 3
💬 0
📌 0

Excited to see Tulu 3 sits in between Llama 3.1 and 3.3 instruct on the chatbot arena leaderboard right now!
Particularly happy it is top 20 for Math and Multi-turn prompts :)
All the details and data on how to train a model this good are right here: arxiv.org/abs/2411.15124
08.01.2025 17:47 —
👍 15
🔁 3
💬 0
📌 0
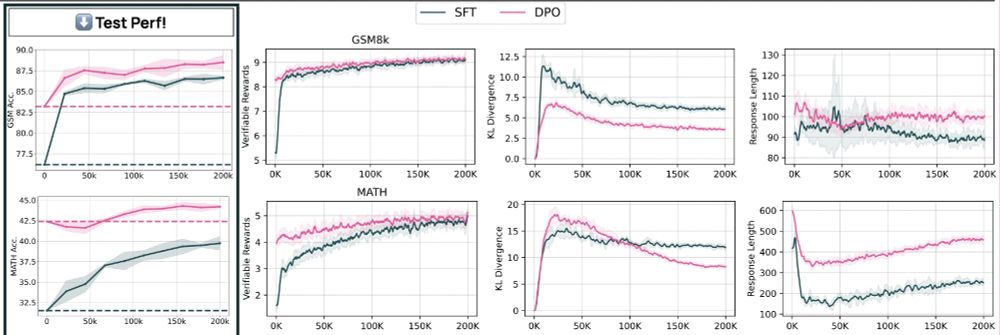
Test accuracy, train rewards, kl divergence, and response lenght training curves when training Tulu 3 SFT and Tulu 3 DPO on the MATH or GSM8k train sets, and evaluating on MATH/GSM8k using RLVR. Performance significantly improves in both cases.
New OpenAI RL finetuning API reminds me a lot of RLVR, which we used for Tülu 3 (arxiv.org/abs/2411.15124).
Using RL to train against labels is a simple idea, but very effective (>10pt gains just using GSM8k train set).
It's implemented for you to use in Open-Instruct 😉: github.com/allenai/open...
06.12.2024 20:24 —
👍 7
🔁 1
💬 1
📌 0
Job Application for Predoctoral Young Investigator, OLMo at The Allen Institute for AI
Our team at Ai2 (OLMo) is looking for a predoctoral researcher. You get to work on exciting research in building open LMs while preparing for a PhD.
Apply here: job-boards.greenhouse.io/thealleninst...
04.12.2024 17:04 —
👍 2
🔁 0
💬 0
📌 0
GitHub - allenai/OLMo: Modeling, training, eval, and inference code for OLMo
Modeling, training, eval, and inference code for OLMo - allenai/OLMo
We just updated the OLMo repo at github.com/allenai/OLMo!
There are now several training configs that together reproduce the training runs that lead to the final OLMo 2 models.
In particular, all the training data is available, tokenized and shuffled exactly as we trained on it!
02.12.2024 20:13 —
👍 54
🔁 11
💬 0
📌 0
How does your cat feel about wearing a Garmin device and adding you as a connection?
27.11.2024 18:15 —
👍 1
🔁 0
💬 1
📌 0
OLMo 2 is out! We released 7B and 13B models that are *fully open*, and compete with the best open-weight models out there.
Importantly, we use the same post-training recipe as our recently released Tülu 3, and it works remarkably well, more so at the 13B size.
26.11.2024 21:28 —
👍 2
🔁 0
💬 0
📌 0
As a reviewer, I did not find it particularly useful. The recommendations I received were already addressed by my initial review. As an author, the mix of reviews we got were roughly the same quality as usual.
This is an interesting idea though, and I hope there's a way to make it work.
25.11.2024 14:52 —
👍 3
🔁 0
💬 0
📌 0
We even developed two *new* instruction following evals for this setup:
1) IFEval-OOD, a variant of IFEval (Zhou et al., 2023) but with a disjoint set of constraints.
2) HREF, a more general IF eval targeting a diverse set of IF tasks.
Detailed analyses on these evals are coming out soon.
23.11.2024 23:53 —
👍 1
🔁 0
💬 0
📌 0
We presented some preliminary findings on generalization and overfitting in the report based on this setup, and will put out more analysis soon.
23.11.2024 23:53 —
👍 1
🔁 0
💬 1
📌 0
From a traditional ML perspective, this setup may seem obvious, i.e., a dev-test split of an eval. But none of our modern evals are in-distribution anymore, and we expect our models to generalize across distributions. So we adapted the traditional setup to use newer and harder evals as unseen ones.
23.11.2024 23:53 —
👍 1
🔁 0
💬 1
📌 0
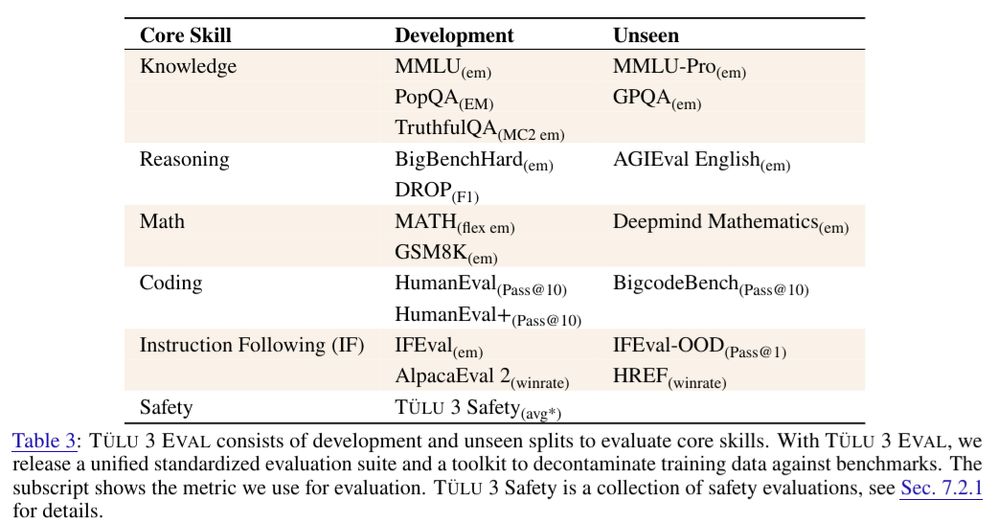
For each "core skill" we care about, we chose a separate set of "development" and "unseen" evaluations. We tracked the performance of models only on the former during development and evaluated only the final checkpoints on the unseen ones.
23.11.2024 23:53 —
👍 1
🔁 0
💬 1
📌 0
A common approach for improving LM performance at specific skills is to *synthesize* training data that is similar to corresponding evals. But how do we ensure that we are not simply overfitting to those benchmarks? It is worth highlighting our approach to evaluation for Tülu 3 in this regard.
23.11.2024 23:53 —
👍 8
🔁 0
💬 1
📌 0
GitHub - allenai/open-instruct
Contribute to allenai/open-instruct development by creating an account on GitHub.
Want to post-train on your own data? Here's our training code: github.com/allenai/open....
Reproducing LM evaluations can be notoriously difficult. So we released our evaluation framework where you can specify and tweak every last detail and reproduce what we did: github.com/allenai/olmes.
23.11.2024 04:20 —
👍 0
🔁 0
💬 0
📌 0
Super excited to release Tülu 3, a suite of open SoTA post-trained models, data, code, evaluation framework, and most importantly post-training recipes.
I learned A LOT about LM post-training working on this project. We wrote it all up so now you can too.
Paper: allenai.org/papers/tulu-...
23.11.2024 04:20 —
👍 8
🔁 0
💬 1
📌 1
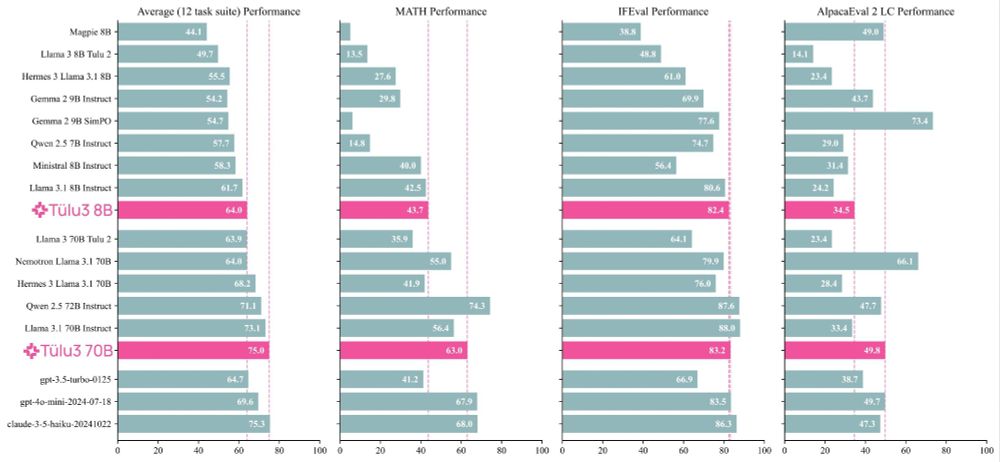
Excited to release Tulu 3! We worked hard to try and make the best open post-training recipe we could, and the results are good!
I was lucky enough to work on almost every stage of the pipeline in one way or another. Some comments + highlights ⬇️
21.11.2024 17:45 —
👍 9
🔁 5
💬 1
📌 0
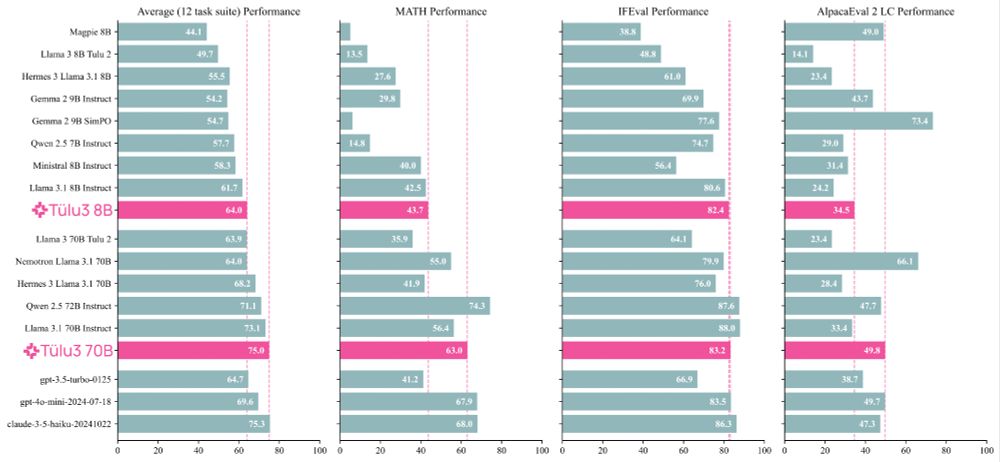
Meet Tülu 3, a set of state-of-the-art instruct models with fully open data, eval code, and training algorithms.
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
21.11.2024 17:15 —
👍 111
🔁 31
💬 2
📌 7

Open Post-Training recipes!
Some of my personal highlights:
💡 We significantly scaled up our preference data!
💡 RL with Verifiable Rewards to improve targeted skills like math and precise instruction following
💡 evaluation toolkit for post-training (including new unseen evals!)
21.11.2024 18:40 —
👍 22
🔁 1
💬 0
📌 0

