Hello world
26.02.2025 21:08 — 👍 1 🔁 0 💬 0 📌 0

Newton-Schulz isn't the answer even for instantaneous whitening.
PSGD: MSE( Q.T Q H , I ) = 5.2e-3
Zero-Power NS 100 iterations: MSE( NS(G) , I ) = 8.2e-1
True Inverse: MSE( H^(-1/2) H H^(-1/2), I ) = 6.1e-3
PSGD whitens information significantly better than the Newton-Schulz iters found in Muon
27.12.2024 09:24 — 👍 2 🔁 0 💬 0 📌 0

Xilin is back at it again. Results are clear: damping hurts precision, but lower precision needs it if the underlying Hessian is extremely poorly conditioned.
07.12.2024 16:46 — 👍 2 🔁 0 💬 0 📌 0

PSGD tracking Muon on modded nanoGPT
02.12.2024 05:30 — 👍 2 🔁 1 💬 0 📌 0
Be in touch!
30.11.2024 18:12 — 👍 0 🔁 0 💬 0 📌 0
Who is going to NeurIPS?
30.11.2024 17:55 — 👍 3 🔁 0 💬 1 📌 0
Cheers !
30.11.2024 01:14 — 👍 0 🔁 0 💬 0 📌 0
Maybe just a skill issue but I couldn't get the darn thing to run. I wanted to whiten the gradients before giving them to velo to see how effective performance. Would you be interested in helping me with a few experiments?
29.11.2024 07:52 — 👍 1 🔁 0 💬 1 📌 0
Totally agree!
29.11.2024 05:28 — 👍 1 🔁 0 💬 0 📌 0
The rejects were horribly misinformed self contradictory but extremely confident. PSGD, SOAP and friends are taking over regardless of academia.
28.11.2024 20:17 — 👍 0 🔁 2 💬 0 📌 0
Lol AI stats reviews consisted of one 5 rating: Top 10% of accepted papers with a confidence or 5 - absolutely certain. The reviewer raved and ranted about how good PSGD.
And two confident 4 rejects with a score of 1. And one borderline reject with a confidence of 4.
28.11.2024 20:17 — 👍 2 🔁 0 💬 1 📌 0
Here was a post I made showing MARS actually helping initial convergence of PSGD. I believe this is happening because MARS is reducing the variance of the gradients which here resulted in a bit faster convergence. But it is unclear how this effects PSGD later in training!
bsky.app/profile/hess...
28.11.2024 02:16 — 👍 3 🔁 0 💬 1 📌 0
Hi @clementpoiret.bsky.social I am one of the co-authors of PSGD from 2022, and actively working on PSGD Kron with Xilin and @evanatyourservice.bsky.social glad you are excited about PSGD Kron!
28.11.2024 02:16 — 👍 3 🔁 1 💬 1 📌 0
SmolVLM was just released 🚀
It's a great, small, and fully open VLM that I'm really excited about for fine-tuning and on-device use cases 💻
It also comes with 0-day MLX support via mlx-vlm, here's it running at > 80 tok/s on my M1 Max 🤯
26.11.2024 16:36 — 👍 12 🔁 2 💬 1 📌 2
Just put together a starter pack for Deep Learning Theory. Let me know if you'd like to be included or suggest someone to add to the list!
go.bsky.app/2qnppia
22.11.2024 21:35 — 👍 88 🔁 32 💬 29 📌 5

PSGD ❤️ MARS
MARS is a new exciting variance reduction technique from @quanquangu.bsky.social 's group which can help stabilize and accelerate your deep learning pipeline. All that is needed is a gradient buffer. Here MARS speeds up the convergence of PSGD ultimately leading to a better solution.
26.11.2024 04:21 — 👍 15 🔁 5 💬 2 📌 2
Evan is @evanatyourservice.bsky.social
26.11.2024 04:09 — 👍 2 🔁 0 💬 0 📌 0
Bro pfp change messes w me so much.
25.11.2024 00:37 — 👍 1 🔁 0 💬 0 📌 0

Oftentimes PSGD will be slow to close plasticity resulting in slightly slower convergence but ultimately a better solution.
25.11.2024 00:34 — 👍 2 🔁 0 💬 0 📌 0
We are learning the curvature. It can take some time. You can get it to converge faster if you increase the LR of the curvature fitting.
25.11.2024 00:13 — 👍 3 🔁 0 💬 1 📌 0
Okayyy I should actually start posting about PSGD here
24.11.2024 19:24 — 👍 7 🔁 0 💬 1 📌 0
Hello World!
24.11.2024 16:35 — 👍 3 🔁 0 💬 2 📌 0
Hey hey hey the Hessian code is sitting there. I just have to port it to the standard torch.optim style. Right now it uses closure. We can use hvps but we can also use finite differences.
24.11.2024 07:05 — 👍 1 🔁 0 💬 0 📌 0
This is only kron whitening btw. We should port the Hessian version too.
24.11.2024 06:49 — 👍 0 🔁 0 💬 1 📌 0
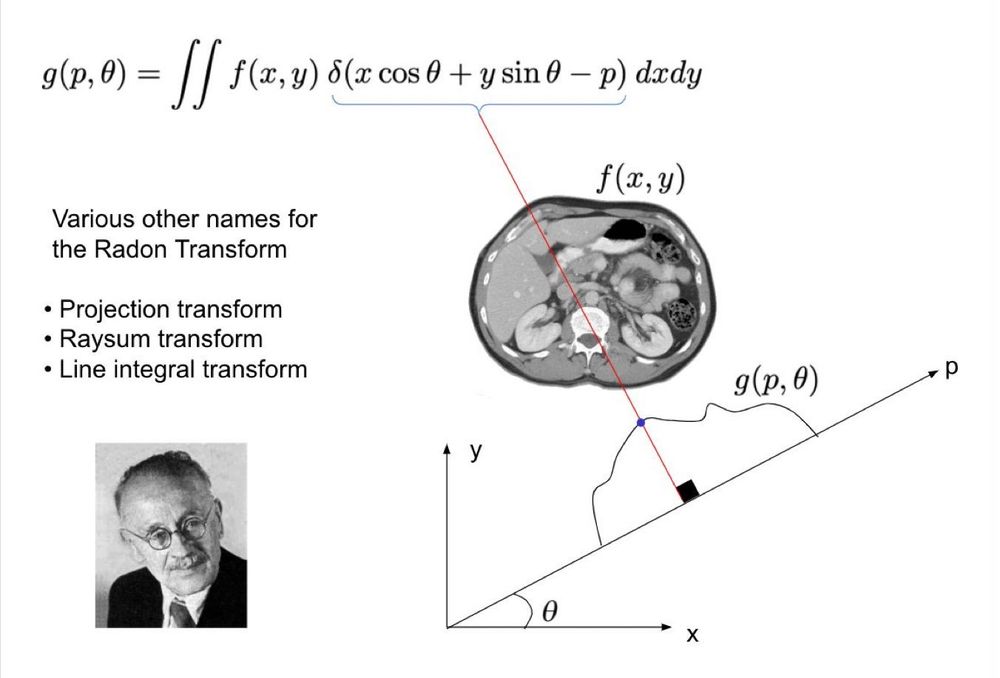
Radon Transform (RT) was formulated in 1917 but remained useless in practice until CT scanners were invented in the 60s
But RT isn't just for CTs. It's a sort of generalization of marginals in probability
RT g(p,θ): Shoot rays at θ+90 & offset p, measure line integrals of f(x,y) along the ray
1/n
24.11.2024 00:33 — 👍 85 🔁 12 💬 2 📌 0

Just some light reading
24.11.2024 04:40 — 👍 6 🔁 0 💬 1 📌 0
Assistant Professor of CS at UCLA
Machine learning, Optimization, Data-efficient learning
speech synthesis and LLM nerd, DMs open, working on LLM stuff
https://felix-red-panda.com
based in Berlin, Germany
NLP at Tel Aviv Uni and Google DeepMind
Ph.D. in Neuroimaging | AI/Computer Vision Researcher | Making training and inference more efficient | 🇲🇫 CTO & Startup Founder | Linux Aficionado
Statistician, Computational Biologist, R |> Bioconductor
https://www.huber.embl.de
Textbook: Modern Statistics for Modern Biology https://www.huber.embl.de/msmb/ (with @sherlockpholmes.bsky.social)
ML/RL enthusiast, second-order optimization, plasticity, environmentalist
Chief AI Scientist at Databricks. Founding team at MosaicML. MIT/Princeton alum. Lottery ticket enthusiast. Working on data intelligence.
a mediocre combination of a mediocre AI scientist, a mediocre physicist, a mediocre chemist, a mediocre manager and a mediocre professor.
see more at https://kyunghyuncho.me/
Director, Princeton Language and Intelligence. Professor of CS.
Machine Learning Professor
https://cims.nyu.edu/~andrewgw
Machine learning researcher. Professor in ML department at CMU.
Assistant Prof at Penn CIS | Postdoc at Microsoft Research | PhD from UT Austin CS | Co-founder LeT-All
Research Scientist @ Google DeepMind. Physics of learning, ML / AI, condensed matter. Prev Ph.D. Physics @ UC Berkeley.
Director of the Center for the Advancement of Progress
EECS Prof @UMich, Research on the Foundations of ML+RL+LLM
https://sota.engin.umich.edu/
Foundations of AI. I like simple and minimal examples and creative ideas. I also like thinking about the next token 🧮🧸
Google Research | PhD, CMU |
https://arxiv.org/abs/2504.15266 | https://arxiv.org/abs/2403.06963
vaishnavh.github.io
Research scientist at OpenAI working on reasoning and RL. Previously PhD student at Stanford University working with Percy Liang and Tengyu Ma.
Research Fellow @ Kempner Institute, Harvard University
Theory of Deep Learning / Learning of Deep Theory
























