
Can you solve this algebra puzzle? 🧩
cb=c, ac=b, ab=?
A small transformer can learn to solve problems like this!
And since the letters don't have inherent meaning, this lets us study how context alone imparts meaning. Here's what we found:🧵⬇️
22.01.2026 16:09 — 👍 48 🔁 10 💬 2 📌 2


Hello world 👋
My first paper at UT Austin!
We ask: what happens when medical “evidence” fed into an LLM is wrong? Should your AI stay faithful, or should it play it safe when the evidence is harmful?
We show that frontier LLMs accept counterfactual medical evidence at face value.🧵
21.01.2026 18:45 — 👍 14 🔁 6 💬 3 📌 2
Check out @hibaahsan.bsky.social's paper on spotting (problematic) racial biases in LLMs for healthcare applications 👇
05.11.2025 15:52 — 👍 2 🔁 0 💬 0 📌 0

3/ 🏥 A separate team at Northeastern located where certain signals live inside Olmo and made targeted edits that reduced biased clinical predictions. This kind of audit is only possible because Olmo exposes all its components.
→ buff.ly/HkChr4Q
24.10.2025 18:36 — 👍 0 🔁 1 💬 1 📌 1
Chantal (and Vinith) find that you can jailbreak LLMs with syntax! Some examples: cshaib.github.io/syntax_domai...
24.10.2025 16:26 — 👍 2 🔁 0 💬 0 📌 0
Now to appear at #EMNLP2025 (Findings). We've added more models and experiments: arxiv.org/abs/2502.13319
22.10.2025 12:24 — 👍 2 🔁 0 💬 0 📌 0
Can we distill *circuits* from teacher models into smaller students? 👇
30.09.2025 23:34 — 👍 1 🔁 0 💬 0 📌 0

Who is going to be at #COLM2025?
I want to draw your attention to a COLM paper by my student @sfeucht.bsky.social that has totally changed the way I think and teach about LLM representations. The work is worth knowing.
And you can meet Sheridan at COLM, Oct 7!
bsky.app/profile/sfe...
27.09.2025 20:54 — 👍 39 🔁 8 💬 1 📌 2
Can we quantify what makes some text read like AI "slop"? We tried 👇
24.09.2025 13:28 — 👍 8 🔁 1 💬 0 📌 0
Our new paper asks: what is the goal of “natural language verbalization” interpretability approaches? If a verbalizer is supposed to tell us something about what’s in the target LM and NOT just what’s in the verbalizer LM, how do we actually evaluate that?
17.09.2025 21:45 — 👍 13 🔁 3 💬 0 📌 0

Wouldn’t it be great to have questions about LM internals answered in plain English? That’s the promise of verbalization interpretability. Unfortunately, our new paper shows that evaluating these methods is nuanced—and verbalizers might not tell us what we hope they do. 🧵👇1/8
17.09.2025 19:19 — 👍 26 🔁 8 💬 1 📌 1
About:The New England Mechanistic Interpretability (NEMI) workshop aims to bring together academic and industry researchers from the New England and surround...
New England Mechanistic Interpretability Workshop
This Friday NEMI 2025 is at Northeastern in Boston, 8 talks, 24 roundtables, 90 posters; 200+ attendees. Thanks to
goodfire.ai/ for sponsoring! nemiconf.github.io/summer25/
If you can't make it in person, the livestream will be here:
www.youtube.com/live/4BJBis...
18.08.2025 18:06 — 👍 16 🔁 7 💬 1 📌 3
📢 How factual are LLMs in healthcare?
We’re excited to release FactEHR — a new benchmark to evaluate factuality in clinical notes. As generative AI enters the clinic, we need rigorous, source-grounded tools to measure what these models get right — and what they don’t. 🏥 🤖
11.08.2025 17:25 — 👍 3 🔁 1 💬 1 📌 2
Chatted with @byron.bsky.social at icml about my recent work, so look out for his upcoming "Tokenization is More Than More Than Compression".
19.07.2025 21:11 — 👍 13 🔁 1 💬 1 📌 0

An overview of our AI-in-the-loop expert study pipeline: given a claim from a subreddit, we extract the PIO elements and retrieve the evidence automatically. The evidence, its context, and the evidence are then presented to a medical expert to provide a judgment and a rationale for the factuality of the claim.
Are we fact-checking medical claims the right way? 🩺🤔
Probably not. In our study, even experts struggled to verify Reddit health claims using end-to-end systems.
We show why—and argue fact-checking should be a dialogue, with patients in the loop
arxiv.org/abs/2506.20876
🧵1/
01.07.2025 17:10 — 👍 5 🔁 2 💬 1 📌 1
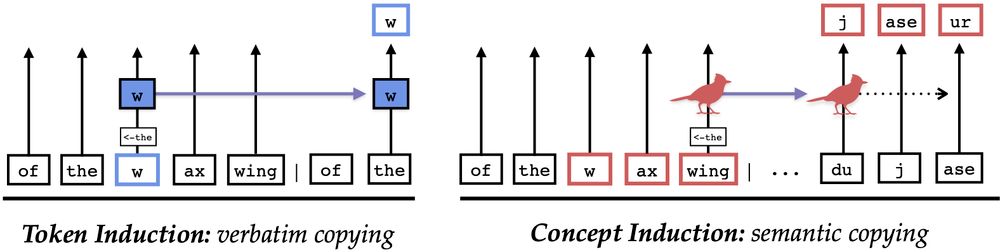
[📄] Are LLMs mindless token-shifters, or do they build meaningful representations of language? We study how LLMs copy text in-context, and physically separate out two types of induction heads: token heads, which copy literal tokens, and concept heads, which copy word meanings.
07.04.2025 13:54 — 👍 76 🔁 19 💬 1 📌 6

Oxford Word of the Year 2024 - Oxford University Press
The Oxford Word of the Year 2024 is 'brain rot'. Discover more about the winner, our shortlist, and 20 years of words that reflect the world.
I'm searching for some comp/ling experts to provide a precise definition of “slop” as it refers to text (see: corp.oup.com/word-of-the-...)
I put together a google form that should take no longer than 10 minutes to complete: forms.gle/oWxsCScW3dJU...
If you can help, I'd appreciate your input! 🙏
10.03.2025 20:00 — 👍 10 🔁 8 💬 0 📌 0
🌟Job ad🌟 We (@gregdnlp.bsky.social, @mattlease.bsky.social and I) are hiring a postdoc fellow within the CosmicAI Institute, to do galactic work with LLMs and generative AI! If you would like to push the frontiers of foundation models to help solve myths of the universe, please apply!
25.02.2025 22:09 — 👍 13 🔁 7 💬 0 📌 3
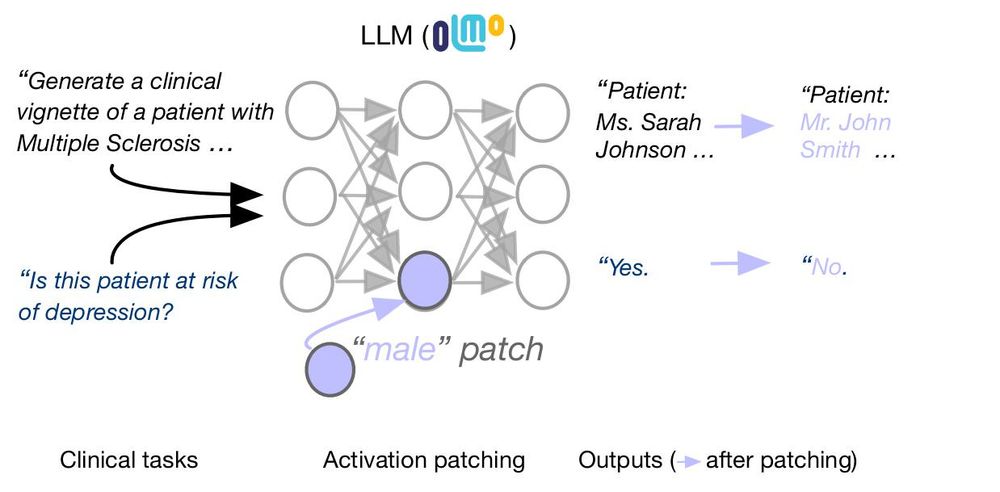
LLMs are known to perpetuate social biases in clinical tasks. Can we locate and intervene upon LLM activations that encode patient demographics like gender and race? 🧵
Work w/ @arnabsensharma.bsky.social, @silvioamir.bsky.social, @davidbau.bsky.social, @byron.bsky.social
arxiv.org/abs/2502.13319
22.02.2025 04:17 — 👍 18 🔁 7 💬 3 📌 2

🚨 Do LLMs fall for spin in medical literature? 🤔
In our new preprint, we find that LLMs are susceptible to biased reporting of clinical treatment benefits in abstracts—more so than human experts. 📄🔍 [1/7]
Full Paper: arxiv.org/abs/2502.07963
🧵👇
15.02.2025 02:34 — 👍 63 🔁 25 💬 3 📌 4
DeepSeek R1 shows how important it is to be studying the internals of reasoning models. Try our code: Here @canrager.bsky.social shows a method for auditing AI bias by probing the internal monologue.
dsthoughts.baulab.info
I'd be interested in your thoughts.
31.01.2025 14:30 — 👍 28 🔁 9 💬 1 📌 1
📣 🌍 We're hiring for 2 Machine Learning researchers to join SOLACE-AI @kingscollegelondon.bsky.social , funded by @wellcometrust.bsky.social . This is your chance to develop cutting-edge AI to directly impact global health responses to climate emergencies. jobs.ac.uk/job/DLM377
27.01.2025 11:55 — 👍 2 🔁 3 💬 0 📌 0
OLMo 2 is out 🥳 7B and 13B trained on 5T tokens, and meticulousy instruction tuned using Tulu 3 recipe.
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social
26.11.2024 21:12 — 👍 260 🔁 44 💬 9 📌 2
And Sheridan Feucht investigates the "implicit vocabulary" of LLMs via token erasure: arxiv.org/abs/2406.20086 (w/David Atkinson and @davidbau.bsky.social)
09.11.2024 21:21 — 👍 2 🔁 0 💬 1 📌 0
Somin Wadhwa has some intriguing findings on distillation with "chain of thought" sequences (e.g., this works better when "reasoning" follows labels, and individual tokens seem to be sufficient): arxiv.org/abs/2406.14511 (w/@Silvio Amir)
09.11.2024 21:21 — 👍 1 🔁 0 💬 1 📌 0
Chantal Shaib reports on syntactic "templates" that LLM's like to repeat: arxiv.org/abs/2407.00211 (w/@yanai.bsky.social and @jessyjli.bsky.social)
09.11.2024 21:21 — 👍 6 🔁 1 💬 1 📌 0
I'll be @ #EMNLP2024 if anyone wants to find snobby coffee / despair about election / or I guess talk research. Some work to be presented👇
09.11.2024 21:21 — 👍 13 🔁 0 💬 1 📌 0

Our work on reducing diagnostic errors with interpretable risk prediction is now on arXiv!
We retrieve evidence from a patient’s record, visualize how it informs a prediction, and test it in a realistic setting. 👇 (1/6)
arxiv.org/abs/2402.10109
w/ @byron.bsky.social and @jwvdm.bsky.social
28.02.2024 18:52 — 👍 2 🔁 1 💬 1 📌 1
Ask me about Reinforcement Learning
Research @ Sony AI
AI should learn from its experiences, not copy your data.
My website for answering RL questions: https://www.decisionsanddragons.com/
Views and posts are my own.
NLP @ Dartmouth College
Formerly @ Amazon AGI (science), CVS Health (science), Jimmy John's (deliveries)
pkseeg.com
Postdoctoral researcher @ CIIRC, CTU, Prague working in vision & language. Also robotics noob. PhD from University of Bristol. Ex. Samsung Research (SAIC-C). I love coffee and plants. And socks.
NLP & Ling; Phd student @UTAustin @UT_Linguistics
website: https://kaijiemo-kj.github.io/
past: circus performer; historian of science; librarian; grantmaker; chief data & evaluation officer at NEH.
present: dad; resident scholar at dartmouth; chief technology officer at the library of virginia.
personal account.
https://scottbot.github.io
defragmenting emotions
#HCI #PeerReview #SciPub
#toolsforthought #ResearchSynthesis
#OpenScience #MetaSci #FoSci
🔎 Research: peer review ethnography
🧑🏫 Teaching: Stats, DataViz
🐢 UMD: College of Info
🌐 PhD Candidate: Info Studies / HCI + Data
🏝️ OASISlab
Associate Prof at EGB Copenhagen Business School & Anti-Corruption Data Collective. Duke PhD. Interested in $$ in politics, state capacity, taxation, stats. Exil-Herthaner
(Associately??) Professing #hci #creativity #toolsforthought #metascience at UMD INFO and HCIL
#immigrant (🇲🇾 ➡️ 🇺🇸 ) #firstgen academic
Building @discoursegraphs.bsky.social #atproto 🤝 #openscience
https://joelchan.me
For professional, see https://cvoelcker.de
If I seem very angry, check if I have been watered in the last 24 hours.
Now 🇺🇸 flavoured, previously available in 🇨🇦 and 🇩🇪
Yale SOM professor & Bulls fan. I study consumer finance, and econometrics is a big part of my research identity. He/him/his
I study algorithms/learning/data applied to democracy/markets/society. Asst. professor at Cornell Tech. https://gargnikhil.com/. Helping building personalized Bluesky research feed: https://bsky.app/profile/paper-feed.bsky.social/feed/preprintdigest
Interested in cognition and artificial intelligence. Research Scientist at Google DeepMind. Previously cognitive science at Stanford. Posts are mine.
lampinen.github.io
ML/AI Robustness in Health @MIT
Postdoc @ Princeton AI Lab
Natural and Artificial Minds
Prev: PhD @ Brown, MIT FutureTech
Website: https://annatsv.github.io/
Anti-cynic. Towards a weirder future. Reinforcement Learning, Autonomous Vehicles, transportation systems, the works. Asst. Prof at NYU
https://emerge-lab.github.io
https://www.admonymous.co/eugenevinitsky
Dedicated to building a transdisciplinary community in machine learning for health.
www.ahli.cc
Conference on Health, Inference, and Learning (chil.ahli.cc)
Machine Learning for Health Symposium (ahli.cc/ml4h)
NLP, AI, LM research director at Ai2; Professor at UW
Assistant Professor, University of Copenhagen; interpretability, xAI, factuality, accountability, xAI diagnostics https://apepa.github.io/























