Interested in 3D DINO features from a single image or unsupervised scene understanding?🦖
Come by our SceneDINO poster at NeuSLAM today 14:15 (Kamehameha II) or Tue, 15:15 (Ex. Hall I 627)!
W/ Jevtić @fwimbauer.bsky.social @olvrhhn.bsky.social Rupprecht, @stefanroth.bsky.social @dcremers.bsky.social
19.10.2025 20:38 — 👍 8 🔁 3 💬 0 📌 0

New opening for Assistant Professor in Machine Learning at Cambridge @eng.cam.ac.uk closing on 22 Sept 2025:
www.jobs.cam.ac.uk/job/49361/
06.08.2025 15:11 — 👍 2 🔁 3 💬 0 📌 0
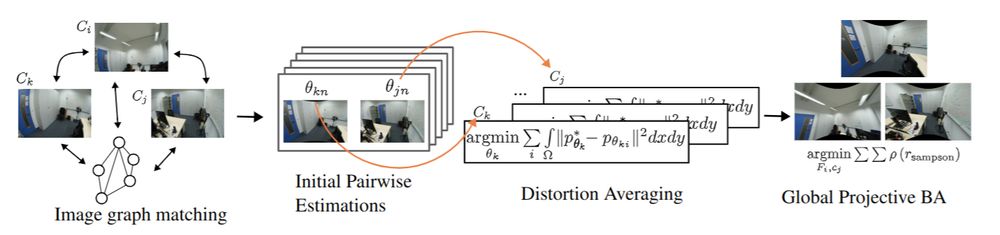
The code for our #CVPR2025 paper, PRaDA: Projective Radial Distortion Averaging, is now out!
Turns out distortion calibration from multiview 2D correspondences can be fully decoupled from 3D reconstruction, greatly simplifying the problem
arxiv.org/abs/2504.16499
github.com/DaniilSinits...
09.07.2025 13:54 — 👍 12 🔁 5 💬 1 📌 0
🦖 We present “Feed-Forward SceneDINO for Unsupervised Semantic Scene Completion”. #ICCV2025
🌍: visinf.github.io/scenedino/
📃: arxiv.org/abs/2507.06230
🤗: huggingface.co/spaces/jev-a...
@jev-aleks.bsky.social @fwimbauer.bsky.social @olvrhhn.bsky.social @stefanroth.bsky.social @dcremers.bsky.social
09.07.2025 13:17 — 👍 24 🔁 10 💬 1 📌 1
Can we match vision and language representations without any supervision or paired data?
Surprisingly, yes!
Our #CVPR2025 paper with @neekans.bsky.social and @dcremers.bsky.social shows that the pairwise distances in both modalities are often enough to find correspondences.
⬇️ 1/4
03.06.2025 09:27 — 👍 27 🔁 12 💬 1 📌 0
We have a PhD opening in Berlin on "Responsible Data Engineering", with a focus on data preparation for ML/AI systems.
This is a fully-funded position with salary level E13 at the newly founded DEEM Lab, as part of @bifold.berlin .
Details available at deem.berlin#jobs-2225
12.05.2025 03:33 — 👍 16 🔁 12 💬 0 📌 0
Can you train a model for pose estimation directly on casual videos without supervision?
Turns out you can!
In our #CVPR2025 paper AnyCam, we directly train on YouTube videos and achieve SOTA results by using an uncertainty-based flow loss and monocular priors!
⬇️
13.05.2025 08:11 — 👍 25 🔁 10 💬 1 📌 1
Happy to be recognized as an Outstanding Reviewer at #CVPR2025 🎊
11.05.2025 11:35 — 👍 10 🔁 1 💬 0 📌 0
While recent methods like Monst3r achieve impressive results, they require datasets with camera pose labels. Such datasets are hard to collect and not available for every domain. AnyCam can directly be trained on any video dataset.
More details: fwmb.github.io/anycam
13.05.2025 08:11 — 👍 1 🔁 0 💬 0 📌 0
Can you train a model for pose estimation directly on casual videos without supervision?
Turns out you can!
In our #CVPR2025 paper AnyCam, we directly train on YouTube videos and achieve SOTA results by using an uncertainty-based flow loss and monocular priors!
⬇️
13.05.2025 08:11 — 👍 25 🔁 10 💬 1 📌 1

📢 #CVPR2025 Highlight: Scene-Centric Unsupervised Panoptic Segmentation 🔥
We present CUPS, the first unsupervised panoptic segmentation method trained directly on scene-centric imagery.
Using self-supervised features, depth & motion, we achieve SotA results!
🌎 visinf.github.io/cups
04.04.2025 13:38 — 👍 22 🔁 6 💬 1 📌 2
🏠 Introducing DepthSplat: a framework that connects Gaussian splatting with single- and multi-view depth estimation. This enables robust depth modeling and high-quality view synthesis with state-of-the-art results on ScanNet, RealEstate10K, and DL3DV.
🔗 haofeixu.github.io/depthsplat/
24.04.2025 08:58 — 👍 39 🔁 13 💬 1 📌 1
🤗 I’m excited to share our recent work: TwoSquared: 4D Reconstruction from 2D Image Pairs.
🔥 Our method produces geometry, texture-consistent, and physically plausible 4D reconstructions
📰 Check our project page sangluisme.github.io/TwoSquared/
❤️ @ricmarin.bsky.social @dcremers.bsky.social
23.04.2025 16:48 — 👍 9 🔁 3 💬 0 📌 1
Announcing the 2025 NAVSIM Challenge! What's new? We're testing not only on real recordings—but also imaginary futures generated from the real ones! 🤯
Two rounds: #CVPR2025 and #ICCV2025. $18K in prizes + several $1.5k travel grants. Submit in May for Round 1! opendrivelab.com/challenge2025/ 🧵👇
13.04.2025 11:08 — 👍 18 🔁 10 💬 1 📌 1

Can we represent fuzzy geometry with meshes? "Volumetric Surfaces" uses layered meshes to represent the look of hair, fur & more without the splatting/volume overhead. Fast, pretty, and runs in real-time on your laptop!
🔗 autonomousvision.github.io/volsurfs/
📄 arxiv.org/pdf/2409.02482
23.04.2025 09:26 — 👍 10 🔁 3 💬 1 📌 0
Check out our latest recent #CVPR2025 paper AnyCam, a fast method for pose estimation in casual videos!
1️⃣ Can be directly trained on casual videos without the need for 3D annotation.
2️⃣ Based around a feed-forward transformer and light-weight refinement.
Code and more info: ⏩ fwmb.github.io/anycam/
23.04.2025 15:52 — 👍 23 🔁 6 💬 1 📌 0

Screenshot of the workshop website "Emergent Visual Abilities and Limits of Foundation Models" at CVPR 2025
Our paper submission deadline for the EVAL-FoMo workshop @cvprconference.bsky.social has been extended to March 19th!
sites.google.com/view/eval-fo...
We welcome submissions (incl. published papers) on the analysis of emerging capabilities / limits in visual foundation models. #CVPR2025
12.03.2025 11:41 — 👍 12 🔁 5 💬 0 📌 1
Check out the recent CVG papers at #CVPR2025, including our (@olvrhhn.bsky.social, @neekans.bsky.social, @dcremers.bsky.social, Christian Rupprecht, and @stefanroth.bsky.social) work on unsupervised panoptic segmentation. The paper will soon be available on arXiv. 🚀
13.03.2025 15:49 — 👍 6 🔁 2 💬 0 📌 0

We are thrilled to have 12 papers accepted to #CVPR2025. Thanks to all our students and collaborators for this great achievement!
For more details check out cvg.cit.tum.de
13.03.2025 13:11 — 👍 36 🔁 12 💬 1 📌 2

TUM AI Lecture Series - FLUX: Flow Matching for Content Creation at Scale (Robin Rombach)
YouTube video by Matthias Niessner
Tomorrow in our TUM AI - Lecture Series with none other than Robin Rombach, CEO Black Forest Labs.
He'll talk about "𝐅𝐋𝐔𝐗: Flow Matching for Content Creation at Scale".
Live stream: youtube.com/live/nrKKLJX...
6pm GMT+1 / 9am PST (Mon Feb 17rd)
16.02.2025 10:28 — 👍 33 🔁 8 💬 0 📌 2
Our 2nd Workshop on Emergent Visual Abilities and Limits of Foundation Models (EVAL-FoMo) is accepting submissions. We are looking forward to talks by our amazing speakers that include @saining.bsky.social, @aidanematzadeh.bsky.social, @lisadunlap.bsky.social, and @yukimasano.bsky.social. #CVPR2025
13.02.2025 16:02 — 👍 7 🔁 3 💬 0 📌 1

Exciting discussions on the future of AI at the Paris AI Action Summit with French Minister of Science Philippe Baptiste and many leading AI researchers
07.02.2025 17:21 — 👍 17 🔁 1 💬 0 📌 0

🏔️⛷️ Looking back on a fantastic week full of talks, research discussions, and skiing in the Austrian mountains!
31.01.2025 19:38 — 👍 32 🔁 11 💬 0 📌 0
🥳Thrilled to share our work, "Implicit Neural Surface Deformation with Explicit Velocity Fields", accepted at #ICLR2025 👏
code is available at: github.com/Sangluisme/I...
😊Huge thanks to my amazing co-authors. @dongliangcao.bsky.social @dcremers.bsky.social
👏Special thanks to @ricmarin.bsky.social
23.01.2025 17:22 — 👍 20 🔁 6 💬 0 📌 0
Indeed - everyone had a blast - thank you all for the great talks, discussions and Ski/snowboarding!
16.01.2025 17:56 — 👍 46 🔁 4 💬 1 📌 3
PhD Student @ CompVis group, LMU Munich
Working on diffusion & flow models🫶
FAIR Chemistry. Simulation-based Inference.
Pre-training lead at World Labs. Former research scientist at Google. Ph.D UWCSE.
📍 San Francisco 🔗 keunhong.com
3D Computer Vision & ML
Research Scientist @Google
Marrying classical CV and Deep Learning. I do things, which work, rather than being novel, but not working.
http://dmytro.ai
Official account for IEEE/CVF Conference on Computer Vision & Pattern Recognition. Hosted by @CSProfKGD with more to come.
📍🌎 🔗 cvpr.thecvf.com 🎂 June 19, 1983
Assistant Professor at the University of Cambridge @eng.cam.ac.uk, working on 3D computer vision and inverse graphics, previously postdoc at Stanford and PhD at Oxford @oxford-vgg.bsky.social
https://elliottwu.com/
Visual Inference Lab of @stefanroth.bsky.social at @tuda.bsky.social - Research in Computer Vision and Machine Learning.
See https://www.visinf.tu-darmstadt.de/visual_inference
Niantic Spatial, Research.
Throws machine learning at traditional computer vision pipelines to see what sticks. Differentiates the non-differentiable.
📍Europe 🔗 http://ebrach.github.io
3D vision fanatic
http://snavely.io
Associate Professor at UMD CS. YouTube: https://youtube.com/@jbhuang0604
Interested in how computers can learn and see.
Professor for Visual Computing & Artificial Intelligence @TU Munich
Co-Founder @synthesiaIO
Co-Founder @SpAItialAI
https://niessnerlab.org/publications.html
Breakthrough AI to solve the world's biggest problems.
› Join us: http://allenai.org/careers
› Get our newsletter: https://share.hsforms.com/1uJkWs5aDRHWhiky3aHooIg3ioxm
PhD Student at the Max Planck Institute for Informatics @cvml.mpi-inf.mpg.de @maxplanck.de | Explainable AI, Computer Vision, Neuroexplicit Models
Web: sukrutrao.github.io
Postdoctoral researcher at the computer vision group TUM
@tumuenchen.bsky.social
computer vision | TU Munich
working on 3D reconstruction, beyond-euclidean geometry, semantic segmentation
website: https://simonwebertum.github.io
Postdoc @ UC Berkeley. 3D Vision/Graphics/Robotics. Prev: CS PhD @ Stanford.
janehwu.github.io
PhD candidate @Jena_DH & @TU_Muenchen working on 3D Reconstruction from Historic Imagery. @TU_Muenchen graduate.
📍 Munich
PhD Candidate in the Princeton Computational Imaging Lab researching 3D generation and perception 🤖
www.ostjul.com





































