Introducing *Edit-by-Track*, a framework that enables precise video motion editing via 3D point tracks.
Our method supports a wide range of motion editing applications, including object removal, shape deformation, dynamic view synthesis, and many more!
Video explainer: youtu.be/aAj6PIgx20o
05.12.2025 03:53 — 👍 10 🔁 1 💬 0 📌 0

Wondering how DeepSeek v3.2 rivals SOTA models (e.g., GPT5/Gemini 3 pro) while being ~30x cheaper? 🤔
Let's learn how the base model works!
We'll focus on attention, the need for KV caching, and key ideas for improving attention (MQA/GQA/MLA/DSA).
youtu.be/Y-o545eYjXM
01.12.2025 18:23 — 👍 12 🔁 2 💬 0 📌 0
Sharing the slides for a talk on faculty job search
Hope it's helpful to people exploring and preparing for the process.
Feedback is welcome!
www.dropbox.com/scl/fi/p7xdt...
21.11.2025 04:42 — 👍 11 🔁 2 💬 0 📌 0
This is GOAT! I now use the BUT/THEREFORE template for all my video scripts.
30.10.2025 02:13 — 👍 1 🔁 0 💬 0 📌 0
thanks for coming to my TED Talk
29.10.2025 19:27 — 👍 6 🔁 0 💬 0 📌 0

Here's a simple fix:
Instead of just presenting information, tell a story.
A story about how you encounter a problem, solve it, introduce a new conflict, and resolve it, and so on.
Keep creating curiosity loops to engage/re-hook your audience.
29.10.2025 19:27 — 👍 12 🔁 0 💬 2 📌 0
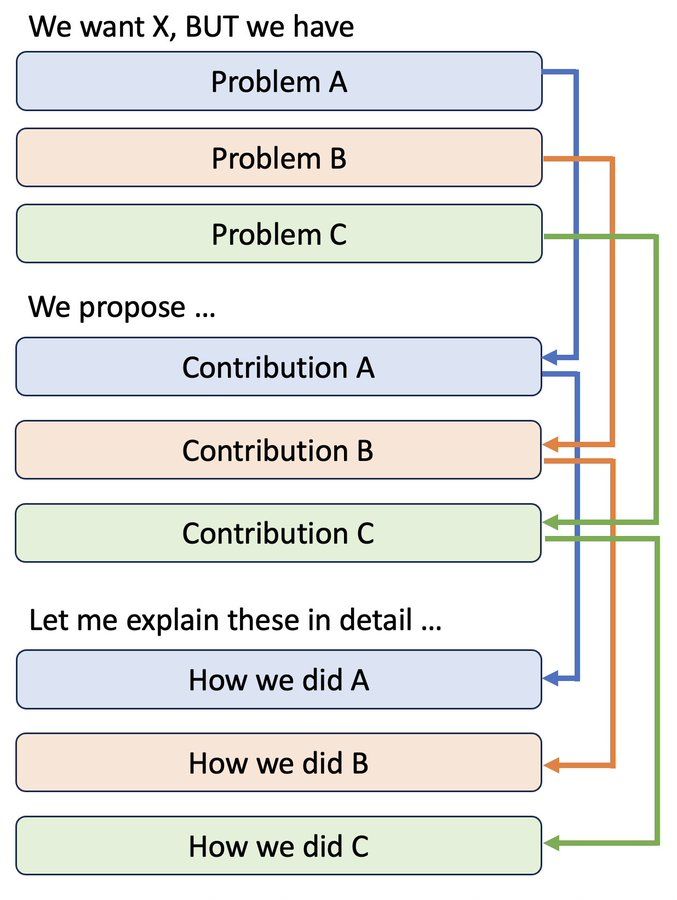
How to organize your talk?
I used to present like this, thinking that I was being "academic", "organized", and "professional".
BUT, from the audience's viewpoints, this sucks. 😱
Look how far they need to hold a long-term context to just make sense of what you're saying!
29.10.2025 19:27 — 👍 14 🔁 2 💬 1 📌 0
YouTube video by Jia-Bin Huang
This Simple Optimizer Is Revolutionizing How We Train AI [Muon]
Muon is a (relatively) new optimizer that powered large-scale training of recent foundation models, e.g., Kimi K2 and GLM 4.5.
Interested in learning how it works?
Check out the video here: youtu.be/bO5nvE289ec
24.10.2025 21:03 — 👍 38 🔁 5 💬 1 📌 0
YouTube video by Jia-Bin Huang
How AI Taught Itself to See [DINOv3]
How AI Taught Itself to See
Self-supervised learning is fascinating! How can AI learn from images only without labels?
In this video, we’ll build the method from first principles and uncover the key ideas behind CLIP, MAE, SimCLR, and DINO (v1–v3).
Video link: youtu.be/oGTasd3cliM
16.09.2025 23:13 — 👍 13 🔁 3 💬 0 📌 0
YouTube video by Jia-Bin Huang
The Weirdly Small AI That Cracks Reasoning Puzzles [HRM]
New video!
A quick dive into the recent Hierarchical Reasoning Model (HRM) through the lens of algorithm synthesis.
Check it out: youtu.be/RK7lysjz_G0
15.08.2025 21:38 — 👍 15 🔁 1 💬 0 📌 0
Diffusion LLMs are promising ways to overcome the limitations of autoregressive LLMs.
Less error propagation, easier to control, and faster to sample!
But how do Diffusion LLMs actually work? 🤔
In this video, let's explore some ideas on this fascinating topic! youtu.be/8BTOoc0yDVA
08.08.2025 02:44 — 👍 11 🔁 1 💬 0 📌 0

In an era of billion-parameter models everywhere, it's incredibly refreshing to see how a fundamental question can be formulated and solved with simple, beautiful math.
- How should we orient a solar panel ☀️🔋? -
Zero AI! If you enjoy math, you'll love this!
Video: www.youtube.com/watch?v=ZKzL...
16.07.2025 14:25 — 👍 9 🔁 2 💬 1 📌 0
*Slides without slide titles*
When I first tried presenting WITHOUT slide titles, everything flowed so much better! (totally validated ... by me)!
Give it a shot! Once you try it, you’ll never want to go back.
08.07.2025 11:26 — 👍 3 🔁 0 💬 0 📌 0
*Empty initial slides*
What’s a better starting point than that default slide layout?
A completely blank slide.
It helps you explore the design space and focus on delivering a clear, compelling story.
08.07.2025 11:26 — 👍 1 🔁 0 💬 1 📌 0
*Bullet points*
The second thing the layout prompts you to do?
("Click to add text").
Start a bullet list.
Among so many creative forms of presenting your ideas, it nudges you toward the most boring one: a list. 🔢
08.07.2025 11:26 — 👍 0 🔁 0 💬 1 📌 0
*Slide title*
The first thing this layout does is to ask you to add a slide title.
Seems reasonable, right? visuals, this encourages you to
1) lead your presentation with text instead of visuals and
2) cram in many titles in a talk, making it harder to maintain a narrative flow.
08.07.2025 11:26 — 👍 0 🔁 0 💬 1 📌 0
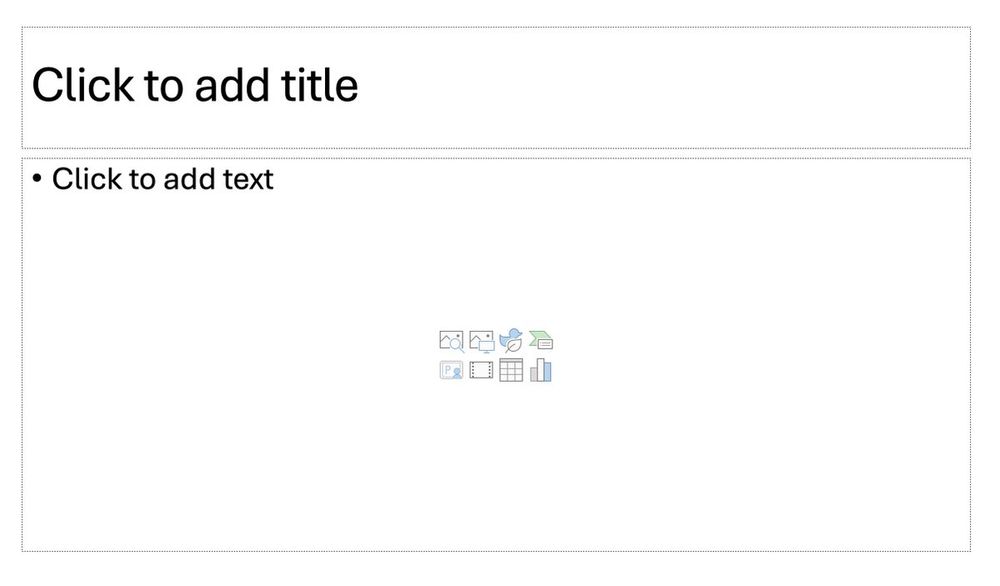
Why is the "Title and Content" slide layout BAD?
Most people prepare their presentation from this default layout. I used it for years without questioning it.
BUT, this essentially guides you toward developing poor presentation. Why? 🤔
08.07.2025 11:26 — 👍 22 🔁 2 💬 5 📌 0
Thanks! Yup, I hope to cover some fun computer vision applications. Stay tuned!
02.07.2025 07:35 — 👍 1 🔁 0 💬 0 📌 0
Kids’ summer camp just kicked off, and that means...
I finally have time to make new videos!
What topics are you most interested in right now?
01.07.2025 09:51 — 👍 5 🔁 0 💬 1 📌 0

Why More Researchers Should be Content Creators
Just trying something new! I recorded one of my recent talks, sharing what I learned from starting as a small content creator.
youtu.be/0W_7tJtGcMI
We all benefit when there are more content creators!
24.06.2025 21:58 — 👍 9 🔁 2 💬 1 📌 1

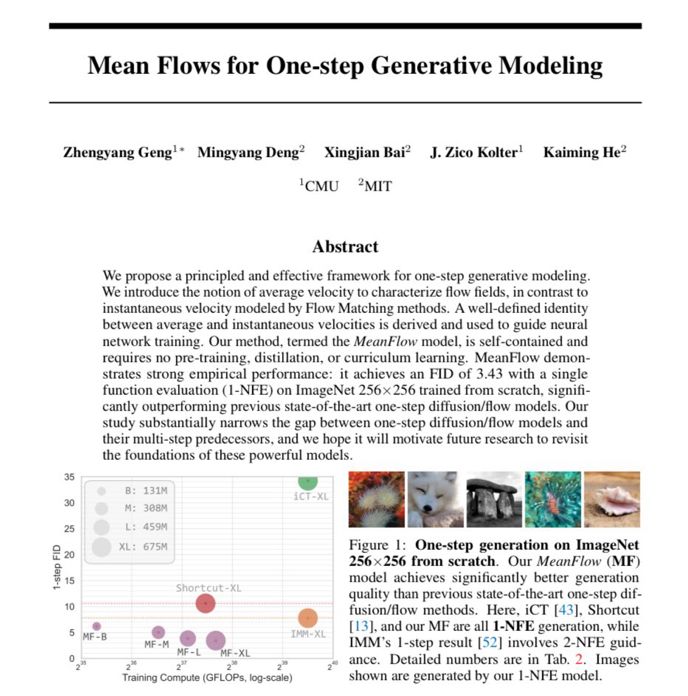
Fresh out of the oven! 🍞 @jbhuang0604.bsky.social breaks down Mean Flow from Kaiming’s group in his latest video.
Video: youtu.be/swKdn-qT47Q?...
19.06.2025 22:24 — 👍 18 🔁 2 💬 0 📌 1
YouTube video by Jia-Bin Huang
Policy Gradient in One Minute
No time? I’ve got your back!
Check out Policy Gradient in One Minute!
youtu.be/p9k9YUdnNlk
Have fun!
20.06.2025 23:08 — 👍 4 🔁 0 💬 0 📌 0

Policy gradient methods rock!
These are the core techniques for making your transformer "chat" and "reason", a robot that manipulates objects, and a drone that maneuvers in a complex environment.
BUT, how do we learn all the developments in the past 30+ years?
20.06.2025 23:08 — 👍 3 🔁 1 💬 1 📌 0
YouTube video by Jia-Bin Huang
One Step, Big Leap: The Simple Idea Transforming Generative AI
Check out the video to learn this new, elegant formulation of generative models!
youtu.be/swKdn-qT47Q
20.06.2025 16:09 — 👍 13 🔁 1 💬 0 📌 0
Awesome! 🤩
So glad to hear the authors enjoyed the video, totally made my day!
20.06.2025 16:09 — 👍 13 🔁 0 💬 1 📌 0

We had a blast at CVPR2025!
There was so much to learn! I am particularly excited to meet many new friends and reconnect with old ones.
I feel energized. Already looking forward to the next one!
17.06.2025 14:38 — 👍 6 🔁 0 💬 0 📌 0
Thanks a lot!
04.06.2025 20:01 — 👍 0 🔁 0 💬 1 📌 0

Kullback–Leibler (KL) divergence is a cornerstone of machine learning.
We use it everywhere, from training classifiers and distilling knowledge from models, to learning generative models and aligning LLMs.
BUT, what does it mean, and how do we (actually) compute it?
Video: youtu.be/tXE23653JrU
04.06.2025 14:58 — 👍 31 🔁 5 💬 2 📌 1
My X/Twitter account has been hacked... Please don't believe what they said!
Trying to get it back in the meantime. Sorry for the inconvenience!
03.06.2025 18:11 — 👍 5 🔁 0 💬 0 📌 0

How LLMs Learn to Reason with Reinforcement Learning
Full video: www.youtube.com/watch?v=mg-i...
21.05.2025 18:32 — 👍 3 🔁 0 💬 0 📌 0
Assistant Professor at UPenn. https://lingjie0206.github.io. Research interests: Neural Scene Representation, Neural Rendering, 3D Reconstruction, Human Performance Modeling and Capture.
Assistant Professor of the Generative Intelligence Lab at Carnegie Mellon University. Understanding and creating pixels. All the code and models are available at http://github.com/junyanz.
Professor at MIT CSAIL, leading the scene representation group (scenerepresentations.com). We are teaching AI to understand the world through perceiving and interacting with it.
Professor, Programmer in NYC.
Cornell, Hugging Face 🤗
Senior Research Manager at NVIDIA. Prev professor at TUM. Computer vision mostly. Views are my own.
Prof at Georgia Tech
https://faculty.cc.gatech.edu/~judy/
Machine Learning and Computer Vision Researcher
Asst. Prof. UNC Chapel Hill CS
Computer Vision & Graphics.
https://www.cs.unc.edu/~ronisen/
Distinguished Scientist at Google. Computational Imaging, Machine Learning, and Vision. Posts are personal opinions. May change or disappear over time.
http://milanfar.org
Associate professor @ Cornell Tech
Staff Research Scientist at Google - http://sniklaus.com/
Rice University, Associate Professor of Computer Science. Computer Vision, Multimodal AI, Deep Learning. Houston, Texas. Check our work at https://vislang.ai/
Professor for Visual Computing & Artificial Intelligence @TU Munich
Co-Founder @synthesiaIO
Co-Founder @SpAItialAI
https://niessnerlab.org/publications.html
Associate Professor, 3DAI Lab @ TU Munich
https://www.3dunderstanding.org/
Associate Professor of Computer Science at SLU. Computer vision and machine learning. Trying to do a bit of good in the world by looking at pixels.
Director, Max Planck Institute for Intelligent Systems; Chief Scientist Meshcapade; Speaker, Cyber Valley.
Building 3D humans.
https://ps.is.mpg.de/person/black
https://meshcapade.com/
https://scholar.google.com/citations?user=6NjbexEAAAAJ&hl=en&oi=ao
Principal research scientist at Google DeepMind. Synthesized views are my own.
📍SF Bay Area 🔗 http://jonbarron.info
This feed is a mostly-incomplete mirror of https://x.com/jon_barron, I recommend you just follow me there.
Researcher (OpenAI. Ex: DeepMind, Brain, RWTH Aachen), Gamer, Hacker, Belgian.
Anon feedback: https://admonymous.co/giffmana
📍 Zürich, Suisse 🔗 http://lucasb.eyer.be
Professor of Computer Vision, @BristolUni. Senior Research Scientist @GoogleDeepMind - passionate about the temporal stream in our lives.
http://dimadamen.github.io
Associate Professor @ Cornell, Computer vision & machine learning



![This Simple Optimizer Is Revolutionizing How We Train AI [Muon]](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:medlwnut6g2efyoas543imbq/bafkreibkxu5ya2ua3hrwwni52t3b4mwf2z2klglvj2jlqtbwsrvj7rgvlm@jpeg)
![How AI Taught Itself to See [DINOv3]](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:medlwnut6g2efyoas543imbq/bafkreibnok7drasbhlomrtgnd7erdh3yorbzf4ui7zcjvhjutufysikhmi@jpeg)
![The Weirdly Small AI That Cracks Reasoning Puzzles [HRM]](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:medlwnut6g2efyoas543imbq/bafkreihzunml5kvxf7yh55mvlawdd2b2im5io7qe4wcpjhspnoppzviyhy@jpeg)

























