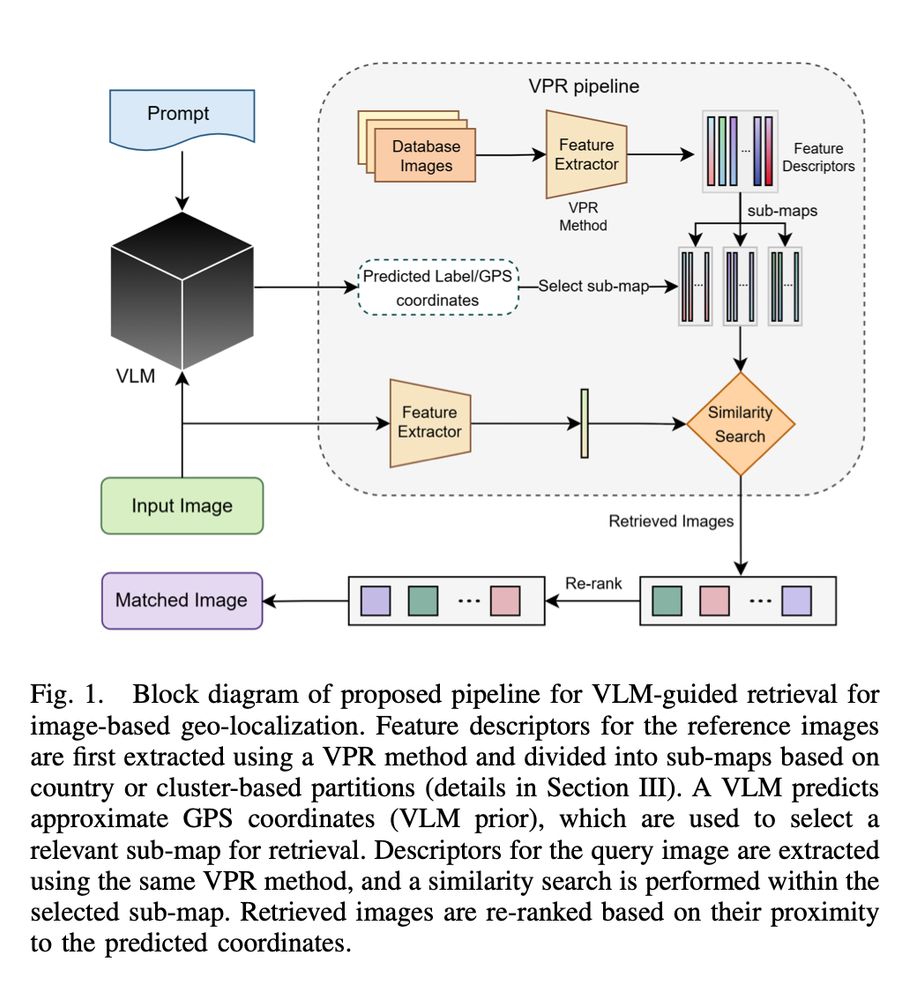
How can one reconstruct the complete 3D interior of a wood block using only photos of its surfaces? 🪵
At SIGGRAPH'25 (Thursday!), Maria Larsson will present *Mokume*: a dataset of 190 diverse wood samples and a pipeline that solves this inverse texturing challenge. 🧵👇
08.08.2025 11:53 — 👍 66 🔁 14 💬 2 📌 1

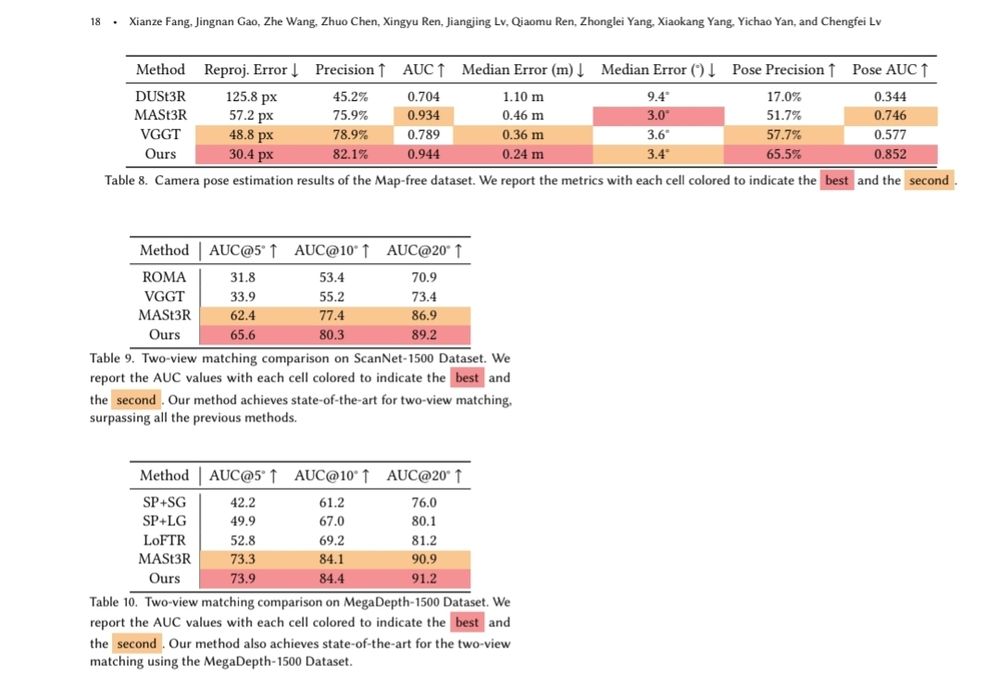
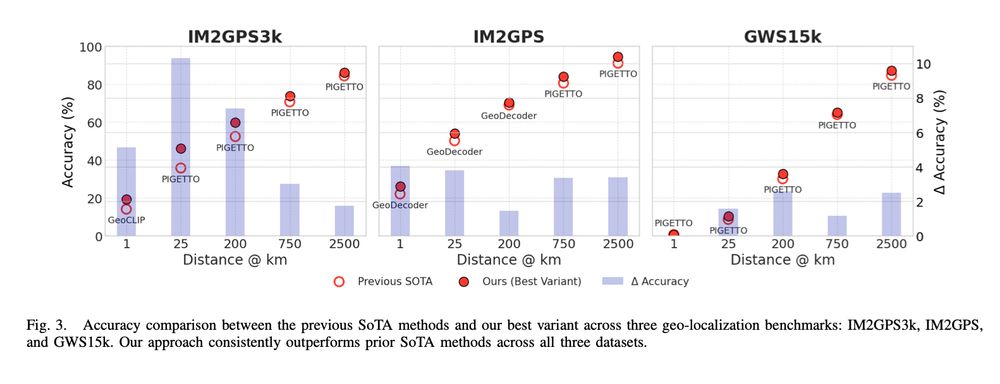
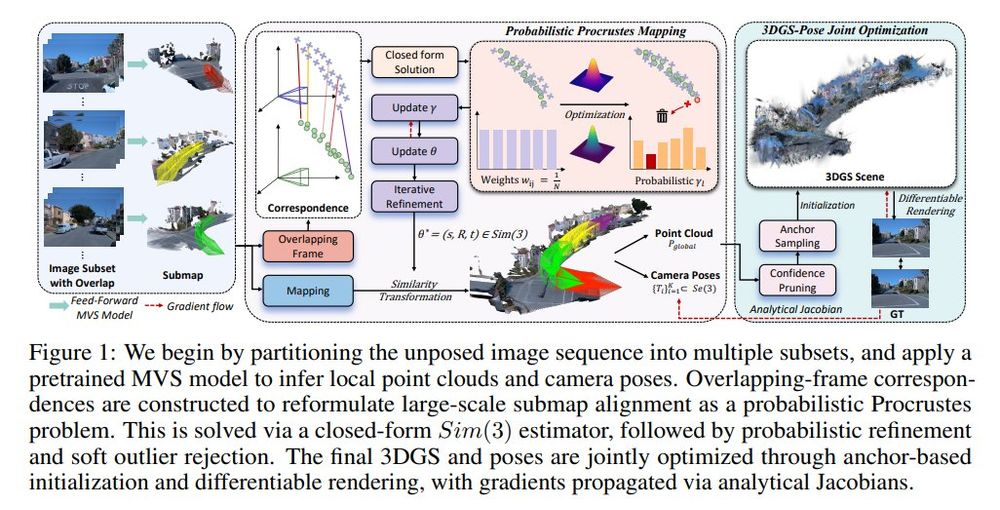
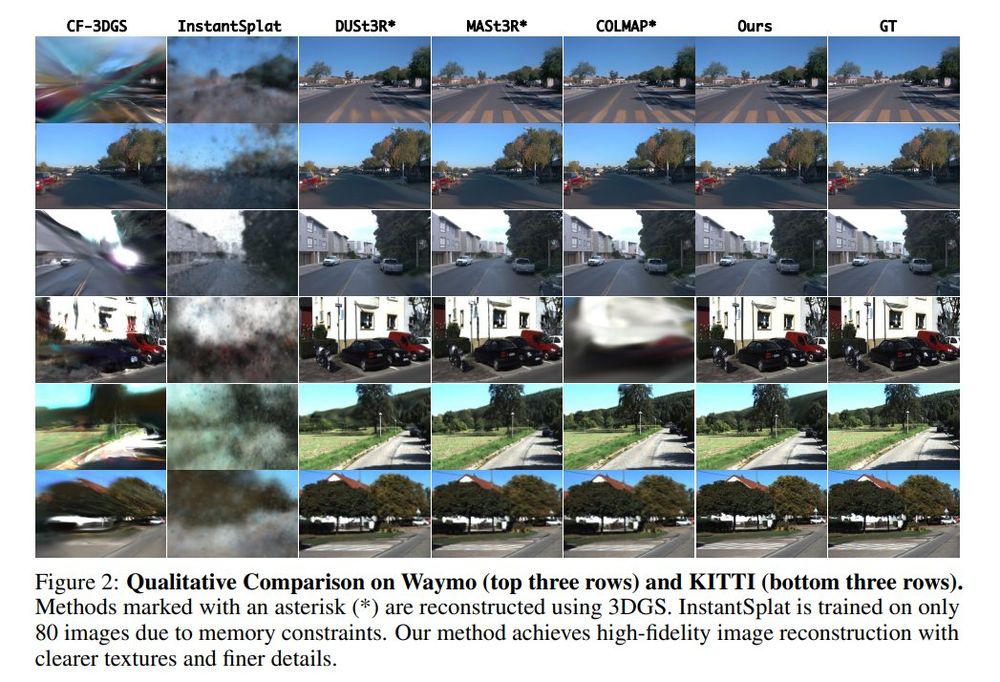
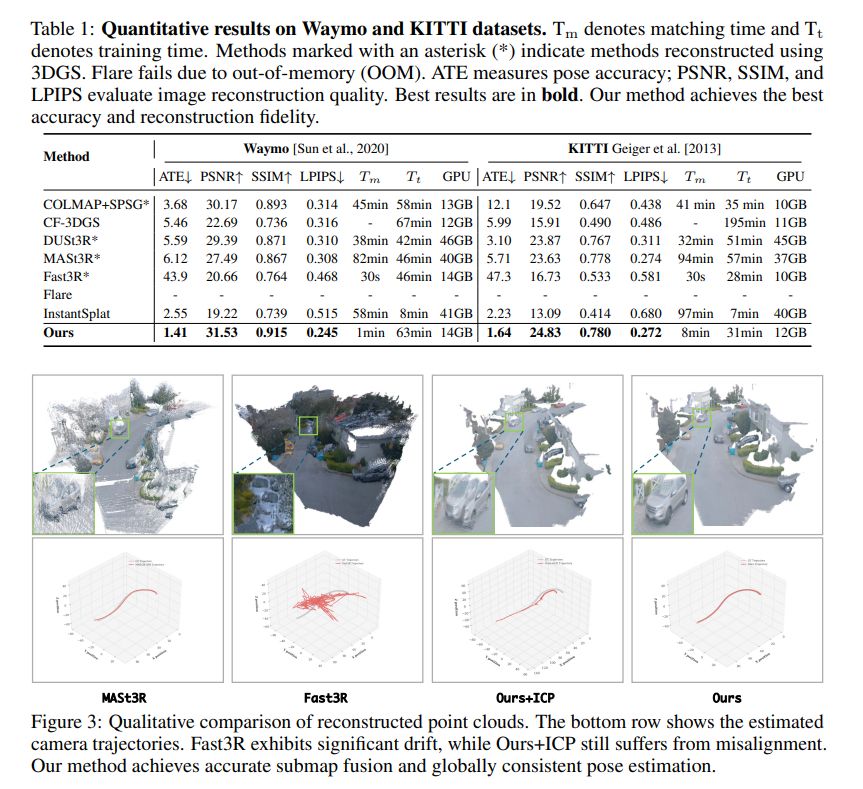
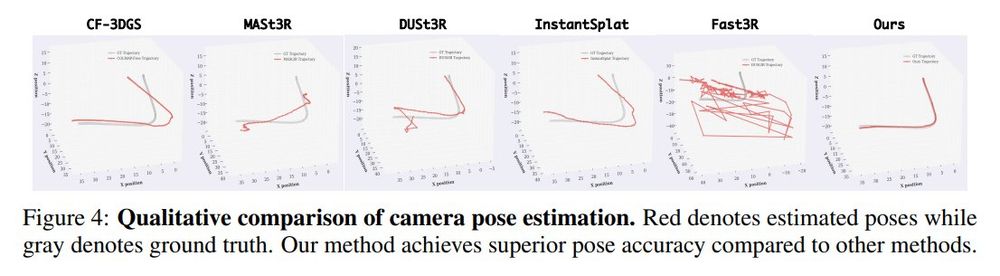
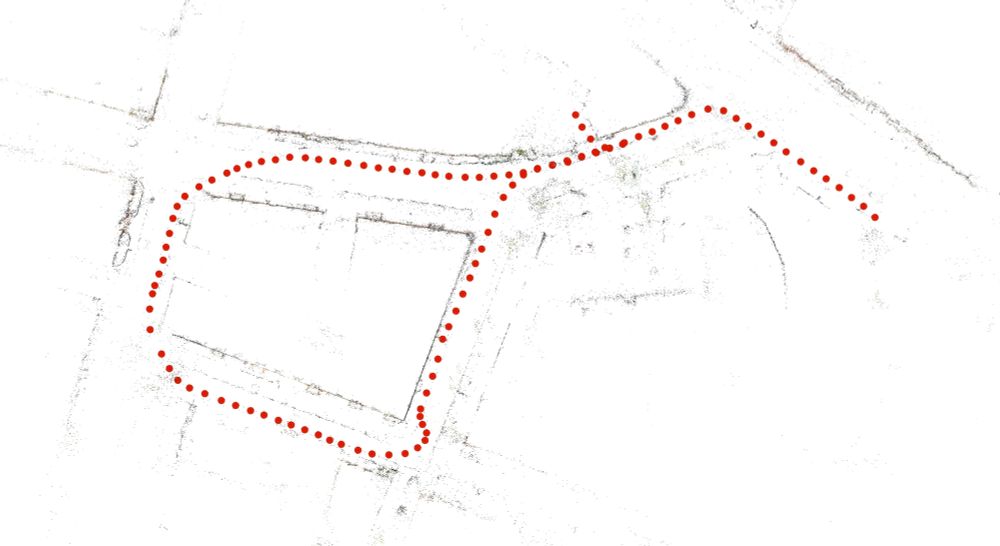
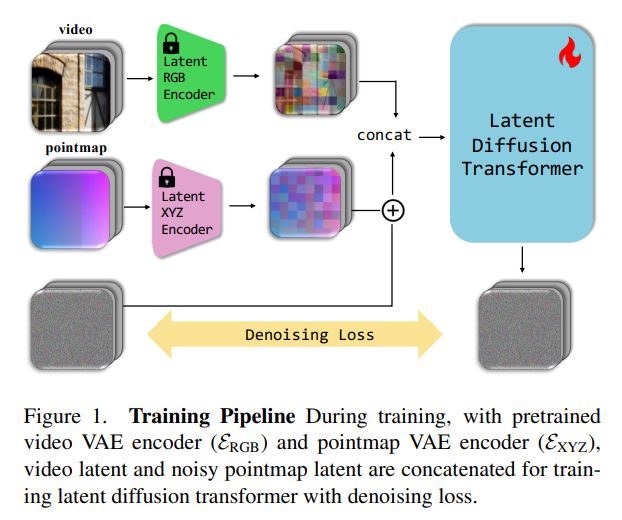
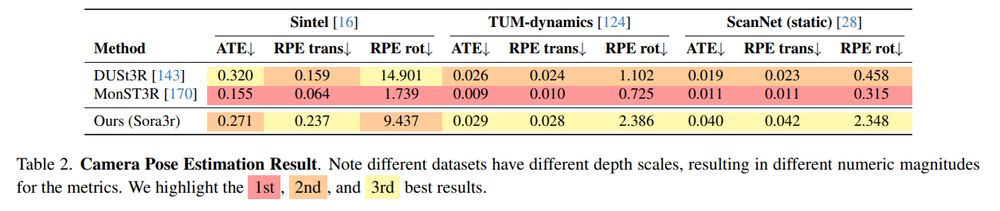
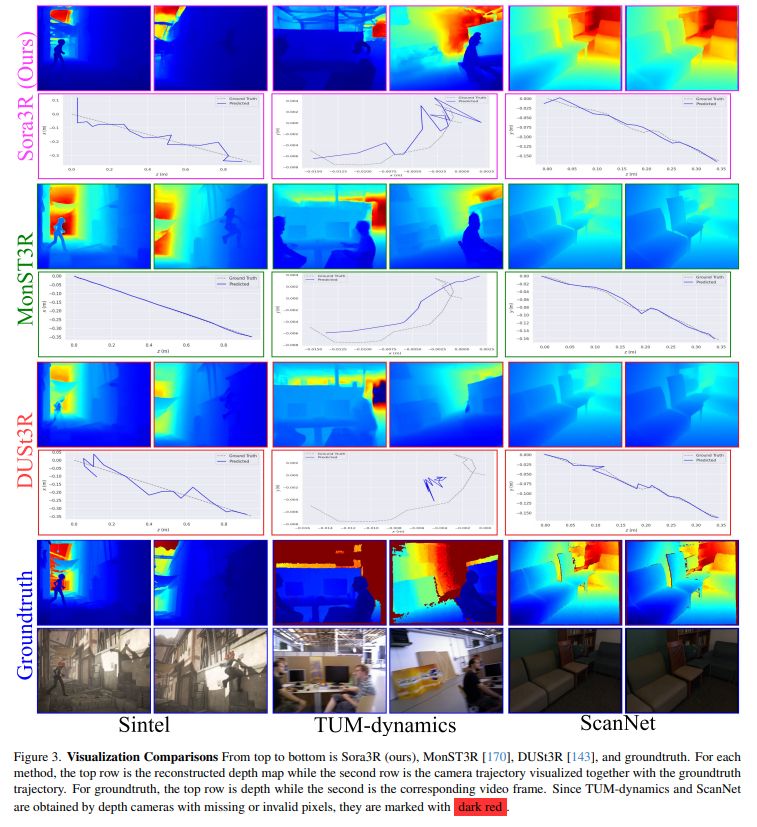
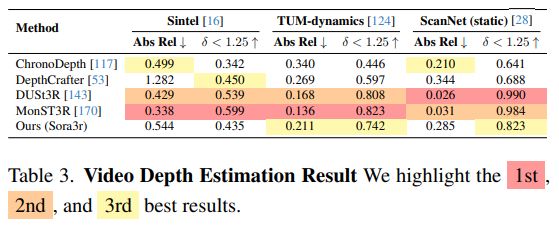
New 3D foundation model dropped.
Note: Seems they might have messed up their image matching metrics (seems like acc rather than auc), but should be at least as good as mast3r.
24.07.2025 22:50 — 👍 11 🔁 2 💬 2 📌 0
Turns out that by default huggingface models run on the CPU...
20.07.2025 12:10 — 👍 1 🔁 0 💬 0 📌 0
Awesome initiative 🎉
This leaves me wondering though: how come authors attending #EurIPS still have to register for the main #NeurIPS (in the Americas) for their paper to be considered accepted?
You stopped so short of actually allowing ML researchers to fly less!
17.07.2025 14:12 — 👍 32 🔁 5 💬 5 📌 2

A meme where Anakin and Padme discuss the logics of allowing a NeurIPS event in Europe while forcing authors to also present in the US for publication
Sofar it doesn’t look good: neurips.cc/FAQ/AuthorRe...
“At least one author of each accepted paper must register for the main conference. A ‘Virtual Only Pass’ is not sufficient.”
17.07.2025 07:32 — 👍 7 🔁 2 💬 1 📌 0
WeTransfer just changed their TOS giving themselves permission to train AI on any content you transfer and produce derivative works based on content you transfer that they are allowed to monetize and you are not allowed payment for.
Stop using WeTransfer.
14.07.2025 23:05 — 👍 7659 🔁 5358 💬 132 📌 475
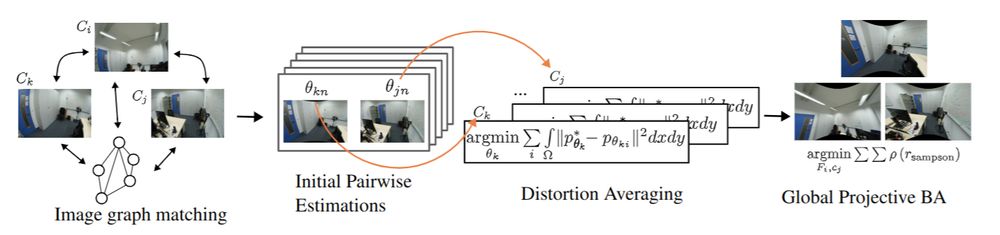
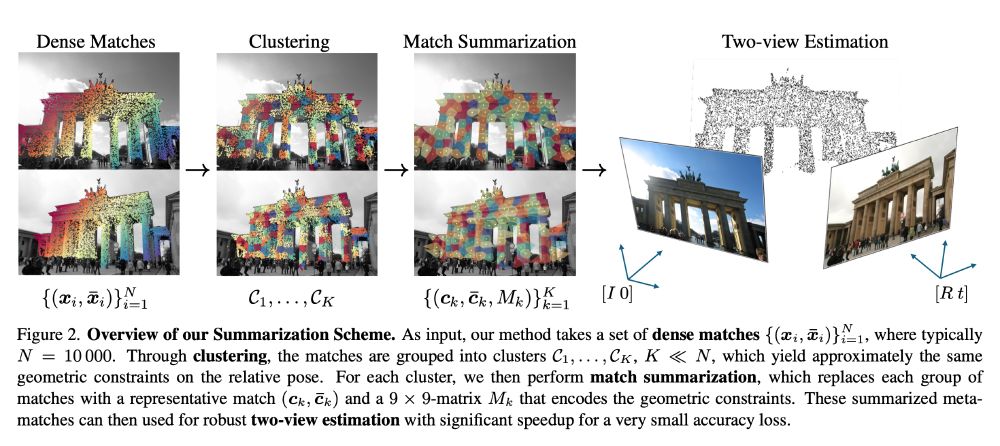
The code for our #CVPR2025 paper, PRaDA: Projective Radial Distortion Averaging, is now out!
Turns out distortion calibration from multiview 2D correspondences can be fully decoupled from 3D reconstruction, greatly simplifying the problem
arxiv.org/abs/2504.16499
github.com/DaniilSinits...
09.07.2025 13:54 — 👍 12 🔁 5 💬 1 📌 0
🦖 We present “Feed-Forward SceneDINO for Unsupervised Semantic Scene Completion”. #ICCV2025
🌍: visinf.github.io/scenedino/
📃: arxiv.org/abs/2507.06230
🤗: huggingface.co/spaces/jev-a...
@jev-aleks.bsky.social @fwimbauer.bsky.social @olvrhhn.bsky.social @stefanroth.bsky.social @dcremers.bsky.social
09.07.2025 13:17 — 👍 24 🔁 10 💬 1 📌 1
🤗 I’m excited to share our recent work: TwoSquared: 4D Reconstruction from 2D Image Pairs.
🔥 Our method produces geometry, texture-consistent, and physically plausible 4D reconstructions
📰 Check our project page sangluisme.github.io/TwoSquared/
❤️ @ricmarin.bsky.social @dcremers.bsky.social
23.04.2025 16:48 — 👍 9 🔁 3 💬 0 📌 1
Can we match vision and language representations without any supervision or paired data?
Surprisingly, yes!
Our #CVPR2025 paper with @neekans.bsky.social and @dcremers.bsky.social shows that the pairwise distances in both modalities are often enough to find correspondences.
⬇️ 1/4
03.06.2025 09:27 — 👍 27 🔁 12 💬 1 📌 0
Can you train a model for pose estimation directly on casual videos without supervision?
Turns out you can!
In our #CVPR2025 paper AnyCam, we directly train on YouTube videos and achieve SOTA results by using an uncertainty-based flow loss and monocular priors!
⬇️
13.05.2025 08:11 — 👍 25 🔁 10 💬 1 📌 1
We also found that this allows the CTM to decide to spend less time thinking on simpler images, thus saving energy. When identifying a gorilla, for example, the CTM’s attention moves from eyes to nose to mouth in a pattern remarkably similar to human visual attention.
12.05.2025 02:42 — 👍 18 🔁 2 💬 1 📌 0
📢 New paper CVPR 25!
Can meshes capture fuzzy geometry? Volumetric Surfaces uses adaptive textured shells to model hair, fur without the splatting / volume overhead. It’s fast, looks great, and runs in real time even on budget phones.
🔗 autonomousvision.github.io/volsurfs/
📄 arxiv.org/pdf/2409.02482
05.05.2025 13:00 — 👍 28 🔁 20 💬 1 📌 1

ZurichCV #9 | ZurichAI
Linus Scheibenreif (ETH Zurich) will talk about self-supervised learning for satellite imagery, and Pascal Chang (ETH Zurich/Disney Research) will present his recent work (topic to be announced).
8th ZurichCV is on the 29th of April. We have two fantastic speakers: Linus Scheibenreif (ETH Zurich) will talk about self-supervised learning for satellite imagery, and Pascal Chang (Disney Research) will give us a preview of his soon-to-be-published work.
RSVP: www.zurichai.ch/events/zuric...
20.04.2025 06:31 — 👍 17 🔁 3 💬 0 📌 0
No meal has ever sustained me for more than a few hours, a mere blip on the timeline of my life, 0.001% of my expected lifespan. So therefore I'll no longer be paying at restaurants
17.04.2025 11:53 — 👍 74 🔁 24 💬 2 📌 0

The Visual Recognition Group at CTU in Prague organizes the 49th Pattern Recognition and Computer Vision Colloquium with D. Karatzas, M. Masana, T. Tommasi, P. Mettes @pascalmettes.bsky.social , E. Brachmann @ericbrachmann.bsky.social and V. Stojnic @stojnicv.xyz
cmp.felk.cvut.cz/colloquium/#...
07.04.2025 13:57 — 👍 34 🔁 10 💬 2 📌 2
3D Gaussian splatting relies on depth-sorting of splats, which is costly and prone to artifacts (e.g., "popping"). In our latest work, "StochasticSplats", we replace sorted alpha blending by stochastic transparency, an unbiased Monte Carlo estimator from the real-time rendering literature.
07.04.2025 07:56 — 👍 52 🔁 13 💬 2 📌 2

𝗠𝗖𝗠𝗟 𝗕𝗹𝗼𝗴: Robots & self-driving cars rely on scene understanding, but AI models for understanding these scenes need costly human annotations. Daniel Cremers & his team introduce 🥤🥤 CUPS: a scene-centric unsupervised panoptic segmentation approach to reduce this dependency. 🔗 mcml.ai/news/2025-04...
03.04.2025 09:45 — 👍 6 🔁 1 💬 0 📌 1
I've been wondering the same
02.04.2025 05:31 — 👍 0 🔁 0 💬 0 📌 0

NeurIPS participation in Europe
We seek to understand if there is interest in being able to attend NeurIPS in Europe, i.e. without travelling to San Diego, US. In the following, assume that it is possible to present accepted papers ...
Would you present your next NeurIPS paper in Europe instead of traveling to San Diego (US) if this was an option? Søren Hauberg (DTU) and I would love to hear the answer through this poll: (1/6)
30.03.2025 18:04 — 👍 280 🔁 159 💬 6 📌 14
*Please repost* @sjgreenwood.bsky.social and I just launched a new personalized feed (*please pin*) that we hope will become a "must use" for #academicsky. The feed shows posts about papers filtered by *your* follower network. It's become my default Bluesky experience bsky.app/profile/pape...
10.03.2025 18:14 — 👍 506 🔁 290 💬 23 📌 76
Psychologist for Software Teams (& writing a book about it). Founder: Developer Success Lab, Catharsis Consulting. VP of Research. Defender of the mismeasured. she/her 🏳️🌈 https://www.drcathicks.com/
Host at: https://www.changetechnically.fyi/
METR is a research nonprofit that builds evaluations to empirically test AI systems for capabilities that could threaten catastrophic harm to society.
The MCML is a joint research initiative of LMU München and TU München. It is institutionally funded by the Federal Ministry of Education and Research and the Free State of Bavaria.
Ph.D. Student @ University of Freiburg | Research Scientist @ Continental AI Lab
Ph.D. student @ ETH Zürich
Researcher at Google, 3D computer vision & machine learning. Previously PhD at ETH Zurich, intern at Google, Meta Reality Labs, Microsoft, MagicLeap. Migrating from x.com/pesarlin ...
Mostly 3D+AI+voice.
Currently building https://playmixworld.com and https://mixreel.ai
Also:
https://github.com/nmfisher/thermion
https://bit.ly/3RkzFfH
Flutter/Dart/C++/PyTorch/Blender
Postdoc at IBME in Oxford. Machine learning for healthcare.
https://www.fregu856.com/
@ellis.eu Ph.D. Student @CVG (@dcremers.bsky.social), @visinf.bsky.social & @oxford-vgg.bsky.social | Ph.D. Scholar @zuseschooleliza.bsky.social | M.Sc. & B.Sc. @tuda.bsky.social | Prev. @neclabsamerica.bsky.social
https://christophreich1996.github.io
Nerfstudio contributor, fan of fast software 😎
I make games - co-op games - Left 4 Dead, portal, etc - now The Anacrusis.
🇭🇺/🇰🇿 | CS & ECON | Copenhagen/Aarhus | @au.dk @aalto.fi & @dtu.dk
Blog: kocsisbalazs.github.io
About: balazskocsis.eu
Making robots part of our everyday lives. #AI research for #robotics. #computervision #machinelearning #deeplearning #NLProc #HRI Based in Grenoble, France. NAVER LABS R&D
europe.naverlabs.com
AI/ML engineer. Previously at Google: Product Manager for Keras and TensorFlow and developer advocate on TPUs. Passionate about democratizing Machine Learning.
Technical facilitator of the Single European Railway Area. Got a question? Contact us: http://bit.ly/2FmebgM
AI Engineer
savelife.in.ua/en/donate-en 🇺🇦
Director of the EPFL College of Humanities, Digital Humanities Institute and Digital Humanities Laboratory, President of Time Machine Organisation
I'm a French R&D engineer and technical artist specialized in 3D, AI and XR technologies. My PhD thesis dealt about how AR & VR could be invested to elicit a specific, transcendental relationship to cultural heritage : a numinous experience.