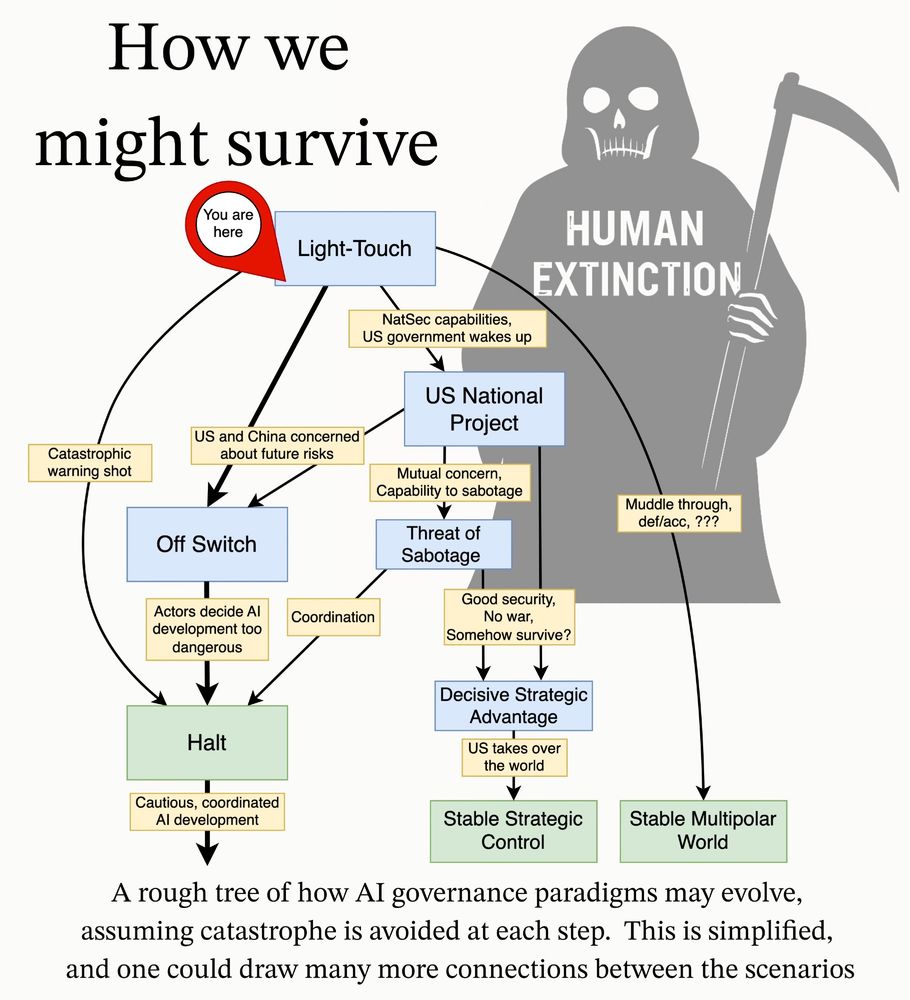
New AI governance research agenda from MIRI’s TechGov Team. We lay out our view of the strategic landscape and actionable research questions that, if answered, would provide important insight on how to reduce catastrophic and extinction risks from AI. 🧵1/10
techgov.intelligence.org/research/ai-...
01.05.2025 22:28 — 👍 13 🔁 5 💬 2 📌 0

MIRI's (@intelligence.org) Technical Governance Team submitted a comment on the AI Action Plan.
Great work by David Abecassis, @pbarnett.bsky.social, and @aaronscher.bsky.social
Check it out here: techgov.intelligence.org/research/res...
18.03.2025 22:38 — 👍 5 🔁 2 💬 0 📌 0
- Reflection on how this is hard but we should try: bsky.app/profile/aaro...
- Mechanism highlight: FlexHEGs: bsky.app/profile/aaro...
05.12.2024 20:02 — 👍 0 🔁 0 💬 0 📌 0
Some versions of FlexHEGs could be designed + implemented in only a couple years and retrofitted to existing chips! Designing more secure chips like this could unlock many AI governance options that aren’t currently available! (3/3)
05.12.2024 20:01 — 👍 1 🔁 0 💬 0 📌 0
These have been discussed previously, yoshuabengio.org/wp-content/u..., @yoshuabengio.bsky.social, so we don’t explain them too much in the report, but they are widely useful! (2/3)
05.12.2024 20:01 — 👍 2 🔁 0 💬 1 📌 0
One mechanism that seems promising is Flexible Hardware-Enabled Guarantees (FlexHEGs) and on-chip approaches. These could potentially be used to securely carry out a wide range of governance operations on AI chips, without leaking sensitive information. (1/3)
05.12.2024 20:01 — 👍 2 🔁 0 💬 1 📌 1
Reflection: The more I got into the weeds on this project, the harder verification seemed. Some difficulties are distributed training, algorithmic progress, and the need to be robust against state-level adversaries. It’s hard, but we have to do it! (1/1)
05.12.2024 19:59 — 👍 0 🔁 0 💬 0 📌 0
- Inspectors could be viable: bsky.app/profile/aaro...
- Reflection on US/China conflict: bsky.app/profile/aaro...
- Mechanism highlight: Signatures of High-Level Chip Measures: bsky.app/profile/aaro...
04.12.2024 20:03 — 👍 0 🔁 0 💬 0 📌 0
- Substituting high-tech low-access with low-tech high-access: bsky.app/profile/aaro...
- Distributed training causes problems: bsky.app/profile/aaro...
- Mechanism highlight: Networking Equipment Interconnect Limits: bsky.app/profile/aaro...
04.12.2024 20:02 — 👍 0 🔁 0 💬 0 📌 0
Conceptually, this could be thought of as having a ‘signature’ of approved activity (e.g., inference, or finetuning on models you’re allowed to finetune) which other chips have to stay sufficiently close to. (6/6)
04.12.2024 19:57 — 👍 0 🔁 0 💬 0 📌 0
But it’s probably much easier because you no longer have a huge distribution shift (e.g., new algorithms, maybe different types of chips) because you included labeled data from the monitored country in your classifier training set. (5/6)
04.12.2024 19:57 — 👍 0 🔁 0 💬 1 📌 0
So when deployed, this mechanism looks like similar classification systems: you’re measuring e.g., the power draw or inter-chip network activity of a bunch of chips and trying to detect any prohibited activity. (4/6)
04.12.2024 19:57 — 👍 0 🔁 0 💬 1 📌 0
But this classification problem gets much easier if you have access to labeled data for chip activities that are approved by the treaty. You could get this by giving inspectors temporary code access. (3/6)
04.12.2024 19:57 — 👍 0 🔁 0 💬 1 📌 0
Classifying chip activity has been researched previously, but it’s not clear it will be robust enough in the international verification context: highly-competent adversaries who can afford to waste some compute could potentially spoof this. (2/6)
04.12.2024 19:57 — 👍 0 🔁 0 💬 1 📌 0
One mechanism that seems promising: Signatures of High-Level Chip Measures. Classify workloads (e.g., is it training or inference) based on high-level chip measures like power-draw, but using ‘signatures’ of these measures based on temporary code access. (1/6)
04.12.2024 19:57 — 👍 0 🔁 0 💬 1 📌 1
Mechanisms to Verify International Agreements About AI Development — MIRI Technical Governance Team
In this research report we provide an in-depth overview of the mechanisms that could be used to verify adherence to international agreements about AI development.
In the report we give example calculations for inter-pod bandwidth limits, discuss distributed training, note various issues, and generally flesh out this idea. Kulp et al. discuss this idea for manufacturing new chips, but in our case that’s not strictly necessary. (8/8)
04.12.2024 19:55 — 👍 0 🔁 0 💬 0 📌 0
This mechanism is promising because it can be implemented with physical networking equipment and security cameras but no code access. This means it poses minimal security risk and could be implemented quickly. (7/8)
04.12.2024 19:55 — 👍 0 🔁 0 💬 1 📌 0
This gap is critical to interconnect bandwidth limits: with enough inter-pod bandwidth for inference but not training, a data center can verifiably claim that these AI chips are not participating in a large training run. (6/8)
04.12.2024 19:55 — 👍 0 🔁 0 💬 1 📌 0
Back-of-the-envelope calculations indicate a bandwidth difference of ~1.5 million times from data parallelism to inference! Distributed training methods close this gap substantially, but there is likely still a gap after such adjustments. (5/8)
04.12.2024 19:55 — 👍 0 🔁 0 💬 1 📌 0
Inference only requires tokens to move in and out of a pod — very little information for text data, order 100 KB/s. For training, communication is typically much larger: activations (tensor parallelism) or gradients (data parallelism). (4/8)
04.12.2024 19:55 — 👍 0 🔁 0 💬 1 📌 0
If between-pod bandwidth is set correctly, a pod could conduct inference but couldn’t efficiently participate in a larger training run. This is because training has higher between-pod communication requirements than inference. (3/8)
04.12.2024 19:55 — 👍 0 🔁 0 💬 1 📌 0
AI chips can be physically arranged to have high bandwidth communication with only a small number, e.g., 128, of other chips (a “pod”) and very low bandwidth communication to chips outside this pod. (2/8)
04.12.2024 19:55 — 👍 0 🔁 0 💬 1 📌 0
One mechanism that seems especially promising: Networking Equipment Interconnect Limits, like “Fixed Sets” discussed by www.rand.org/pubs/working... but can be implemented with custom networking equipment quickly. (1/8)
04.12.2024 19:55 — 👍 0 🔁 0 💬 1 📌 0
Whistleblowers and interviews could be relatively straightforward to implement, not requiring vastly novel tech, and they could make it very difficult to keep violations hidden given the ~hundreds of people involved. (12/12)
04.12.2024 19:51 — 👍 0 🔁 0 💬 0 📌 0
Interviews could also be key. E.g., people working on AI projects could be made available for interviews by international regulators. These could be structured specifically around detecting violations of international agreements. (11/12)
04.12.2024 19:51 — 👍 0 🔁 0 💬 1 📌 0
Whistleblower programs can provide a form of verification by increasing the chances that treaty violations are detected. They’re low-tech and have precedent! Actually protecting whistleblowers may be difficult, of course. (10/12)
04.12.2024 19:51 — 👍 0 🔁 0 💬 1 📌 0
Third, we’ll look at a couple mechanisms that work across most of the policy goals the international community might want to verify. (9/12)
04.12.2024 19:51 — 👍 0 🔁 0 💬 1 📌 0
On the other hand, international inspectors could be granted broad code access, allowing them to review workloads and confirm that prohibited activities aren’t happening. There are obviously security concerns, but this could basically be done tomorrow. (8/12)
04.12.2024 19:51 — 👍 0 🔁 0 💬 1 📌 0
These mechanisms would involve outfitting AI chips to do governance operations, either on the AI chip itself or an adjacent processor. These ideas are great, but they’re not ready yet, more work is needed! (7/12)
04.12.2024 19:51 — 👍 0 🔁 0 💬 1 📌 0
Second, let’s consider verifying some property about what chips are doing (e.g., not doing training). FlexHEG, Flexible Hardware-Enabled Guarantee, Mechanisms, “on-chip” and “hardware-enabled” approaches have been suggested previously. (6/12)
04.12.2024 19:51 — 👍 0 🔁 0 💬 1 📌 0
AI Governance, RAI, Data Privacy, Brighton, Germany and Ireland. AIGP. Financial Services.
AI safety, cybersecurity
https://tchauvin.com
https://x.com/timotheechauvin
https://infosec.exchange/@timotheechauvin
I study the potential for artificial intelligence to trigger a world war and how to prevent that from happening. Currently I'm finishing my DPhil at Oxford and working with @aigioxfordmartin.bsky.social.
benharack.com
he/him
For over two decades, the Machine Intelligence Research Institute (MIRI) has worked to understand and prepare for the critical challenges that humanity will face as it transitions to a world with artificial superintelligence.
i believe the propaganda i read
u believe the propaganda u read
x.com/ronax69
Canadian in Taiwan. Emerging tech writer, and analyst with a flagship Newsletter called A.I. Supremacy reaching 115k readers
Also watching Semis, China, robotics, Quantum, BigTech, open-source AI and Gen AI tools.
https://www.ai-supremacy.com/archive
Research Fellow @ Stanford Intelligent Systems Laboratory and Hoover Institution at Stanford University | Focusing on interpretable, safe, and ethical AI/LLM decision-making. Ph.D. from TUM.
PhD student at Northeastern, previously at EpochAI. Doing AI interpretability.
diatkinson.github.io
I work on AI safety and AI in cybersecurity
CS undergrad at UT Dallas. Into software engineering, Effective Altruism, machine learning, weightlifting, personal knowledge management, and analytic philosophy.
https://roman.technology
Stats Postdoc at Columbia, @bleilab.bsky.social
Statistical ML, Generalization, Uncertainty, Empirical Bayes
https://yulisl.github.io/
machine learning, causal inference, science of llm, ai safety, phd student @bleilab, keen bean
https://www.claudiashi.com/
Trying to ensure the future is bright. Technical governance research at MIRI
PhD supervised by Tim Rocktäschel and Ed Grefenstette, part time at Cohere. Language and LLMs. Spent time at FAIR, Google, and NYU (with Brenden Lake). She/her.
Host of the all-AI Cognitive Revolution podcast – cognitiverevolution.ai
Advancing AI safety through convenings, coordination, software
https://orpheuslummis.info, based in Montréal
computer science, politics, a few opinions here and there. i don't always think them through
AI safety for children | Founder, The Safe AI for Children Alliance | Exploring AI’s potential for both harm and good!
(Please note that my BlueSky direct messages are not always checked regularly)




















