Call for Papers | SciForDL
📣 Excited to co-organize the 2nd Workshop on Scientific Methods for Understanding Deep Learning at ICLR in Rio de Janeiro, Brazil (April 26 or 27, 2026)!! 🔎🤖 🇧🇷
If you work on the why/how of deep learning, we are looking forward to reading your submission! 👇
#ICLR2026 #Sci4DL
21.01.2026 12:01 — 👍 4 🔁 2 💬 1 📌 0
Conversation topics:
• science of deep learning: what experiments/theory do we need to figure what deep nets are doing?
• anything at the intersection of high-dimensional probability and geometry
• what we can do to replace these huge conferences (now more pressing than ever!)
02.12.2025 06:49 — 👍 2 🔁 0 💬 0 📌 0
I'll be in #NeurIPS2025 Dec 3-7, do reach out (atconf/email) if you want to chat (see below)! I'm on the faculty job market 👀
Come say hi to @zahra-kadkhodaie.bsky.social @eerosim.bsky.social and I at our poster on energy-based models Fri 11am #3700 (thread in quoted post)
bsky.app/profile/flor...
02.12.2025 06:49 — 👍 2 🔁 0 💬 1 📌 0

When AI Learns What Makes an Image Probable, Simple Beats Complex by 10¹⁴⁰⁰⁰
Natural images vary in probability by up to 10¹⁴⁰⁰⁰, CDS researchers find, challenging assumptions about how images are structured.
CDS Faculty Fellow @florentinguth.bsky.social, CDS PhD alum
Zahra Kadkhodaie, & CDS Professor @eerosim.bsky.social, in a NeurIPS 2025 paper, estimate image probability directly & discover natural images differ in probability by factors of up to 10^14,000.
nyudatascience.medium.com/when-ai-lear...
17.10.2025 16:05 — 👍 3 🔁 1 💬 0 📌 1

🔥 Mark your calendars for the next session of the @ellis.eu x UniReps Speaker Series!
🗓️ When: 31th July – 16:00 CEST
📍 Where: ethz.zoom.us/j/66426188160
🎙️ Speakers: Keynote by
@pseudomanifold.topology.rocks & Flash Talk by @florentinguth.bsky.social
23.07.2025 08:37 — 👍 16 🔁 5 💬 1 📌 2
Next appointment: 31st July 2025 – 16:00 CEST on Zoom with 🔵Keynote: @pseudomanifold.topology.rocks (University of Fribourg) 🔴 @florentinguth.bsky.social (NYU & Flatiron)
10.07.2025 08:47 — 👍 2 🔁 2 💬 0 📌 0
What I meant is that there are generalizations of the CLT to infinite variance. The limit is then an alpha stable distribution (includes Gaussian, Cauchy, but not Gumbel). Also, even if x is heavy tailed then log p(x) is typically not. So a product of Cauchy distributions has a Gaussian log p(x)!
08.06.2025 18:39 — 👍 1 🔁 0 💬 1 📌 0
At the same time, there are simple distributions that have Gumbel-distributed log probabilities. The simplest example I could find is a Gaussian scale mixture where the variance is distributed like an exponential variable. So it is not clear if we will be able to say something more about this! 2/2
08.06.2025 17:00 — 👍 1 🔁 0 💬 0 📌 0
If you have independent components, even if heavy-tailed, then log p(x) is a sum of iid variables and is thus distributed according to a (sum) stable law. A conjecture is that the minimum comes from a logsumexp, so a mixture distribution (sum of p) rather than a product (sum of log p). 1/2
08.06.2025 17:00 — 👍 1 🔁 0 💬 2 📌 0
For a more in-depth discussion of the approach and results (and more!): arxiv.org/pdf/2506.05310
06.06.2025 22:11 — 👍 6 🔁 0 💬 0 📌 0

Finally, we test the manifold hypothesis: what is the local dimensionality around an image? We find that this depends both on the image and the size of the local neighborhood, and there exists images with both large full-dimensional and small low-dimensional neighborhoods.
06.06.2025 22:11 — 👍 5 🔁 0 💬 1 📌 0
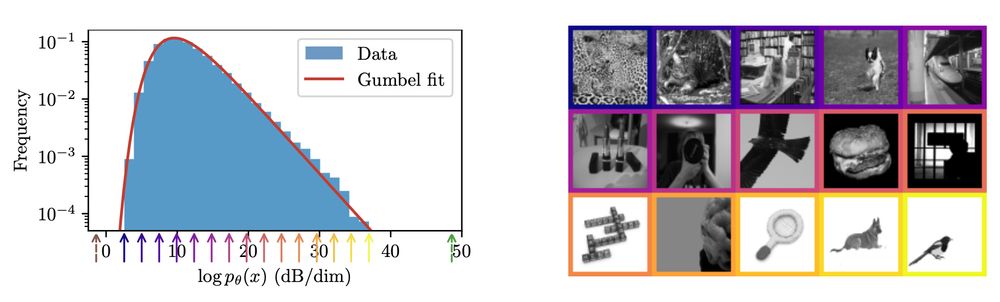
High probability ≠ typicality: very high-probability images are rare. This is not a contradiction: frequency = probability density *multiplied by volume*, and volume is weird in high dimensions! Also, the log probabilities are Gumbel-distributed, and we don't know why!
06.06.2025 22:11 — 👍 6 🔁 1 💬 2 📌 0

These are the highest and lowest probability images in ImageNet64. An interpretation is that -log2 p(x) is the size in bits of the optimal compression of x: higher probability images are more compressible. Also, the probability ratio between these is 10^14,000! 🤯
06.06.2025 22:11 — 👍 6 🔁 0 💬 1 📌 0

But how do we know our probability model is accurate on real data?
In addition to computing cross-entropy/NLL, we show *strong* generalization: models trained on *disjoint* subsets of the data predict the *same* probabilities if the training set is large enough!
06.06.2025 22:11 — 👍 3 🔁 0 💬 1 📌 0

We call this approach "dual score matching". The time derivative constrains the learned energy to satisfy the diffusion equation, which enables recovery of accurate and *normalized* log probability values, even in high-dimensional multimodal distributions.
06.06.2025 22:11 — 👍 4 🔁 0 💬 1 📌 0

We also propose a simple procedure to obtain good network architectures for the energy U: choose any pre-existing score network s and simply take the inner product with the input image y! We show that this preserves the inductive biases of the base score network: grad_y U ≈ s.
06.06.2025 22:11 — 👍 3 🔁 0 💬 1 📌 0

How do we train an energy model?
Inspired by diffusion models, we learn the energy of both clean and noisy images along a diffusion. It is optimized via a sum of two score matching objectives, which constrain its derivatives with both the image (space) and the noise level (time).
06.06.2025 22:11 — 👍 3 🔁 0 💬 1 📌 0

What is the probability of an image? What do the highest and lowest probability images look like? Do natural images lie on a low-dimensional manifold?
In a new preprint with Zahra Kadkhodaie and @eerosim.bsky.social, we develop a novel energy-based model in order to answer these questions: 🧵
06.06.2025 22:11 — 👍 72 🔁 23 💬 1 📌 2
🌈 I'll be presenting our JMLR paper "A rainbow in deep network black boxes" today at 3pm at @iclr-conf.bsky.social!
Come to poster #334 if you're interested, I'll be happy to chat
More details in the threads on the other website: x.com/FlorentinGut...
25.04.2025 00:35 — 👍 5 🔁 1 💬 0 📌 0
This also manifests in what operator space and norm you're considering. Here you have bounded operators with operator norm or trace-class operators with nuclear norm. This matters a lot in infinite dimensions but also in finite but large dimensions!
10.04.2025 21:32 — 👍 2 🔁 0 💬 0 📌 0
A loose thought that's been bubbling around for me recently: when you think of a 'generic' big matrix, you might think of it as being close to low-rank (e.g. kernel matrices), or very far from low-rank (e.g. the typical scope of random matrix theory). Intuition ought to be quite different in each.
10.04.2025 21:23 — 👍 13 🔁 1 💬 1 📌 0
Absolutely! Their behavior is quite different (e.g., consistency of eigenvalues and eigenvectors in the proportional asymptotic regime). You also want to use different objects to describe them: eigenvalues should be thought either as a non-increasing sequence or as samples from a distribution.
10.04.2025 21:29 — 👍 2 🔁 0 💬 1 📌 0
SciForDL'24
Speaking at this #NeurIPS2024 workshop on a new analytic theory of creativity in diffusion models that predicts what new images they will create and explains how these images are constructed as patch mosaics of the training data. Great work by @masonkamb.bsky.social
scienceofdlworkshop.github.io
14.12.2024 17:01 — 👍 43 🔁 3 💬 0 📌 2

Excited to present work with @jfeather.bsky.social @eerosim.bsky.social and @sueyeonchung.bsky.social today at Neurips!
May do a proper thread later on, but come by or shoot me a message if you are in Vancouver and want to chat :)
Brief details in post below
12.12.2024 16:08 — 👍 16 🔁 4 💬 1 📌 1
Some more random conversation topics:
- what we should do to improve/replace these huge conferences
- replica method and other statphys-inspired high-dim probability (finally trying to understand what the fuss is about)
- textbooks that have been foundational/transformative for your work
09.12.2024 01:02 — 👍 2 🔁 0 💬 0 📌 0
I'll be at @neuripsconf.bsky.social from Tuesday to Sunday!
Feel free to reach out (Whova, email, DM) if you want to chat about scientific/theoretical understanding of deep learning, diffusion models, or more! (see below)
And check out our Sci4DL workshop on Sunday: scienceofdlworkshop.github.io
09.12.2024 01:02 — 👍 4 🔁 0 💬 1 📌 0
The second edition of SciforDL workshop takes place in #ICLR2026 at Brazil.
Using controlled experiments to test hypotheses about the inner workings of deep networks.
Cognitive Science PhD student @ JHU
Assistant Professor of Cognitive Science at Johns Hopkins. My lab studies human vision using cognitive neuroscience and machine learning. bonnerlab.org
Postdoc at Inria Grenoble with Julien Mairal.
scottpesme.github.io
Explainability, Computer Vision, Neuro-AI.🪴 Kempner Fellow @Harvard.
Prev. PhD @Brown, @Google, @GoPro. Crêpe lover.
📍 Boston | 🔗 thomasfel.me
Reporter at Bloomberg | co-host of Triple Click | New York Times bestselling author of Play Nice + Press Reset + Blood, Sweat, and Pixels | jschreier@gmail.com
Professor of Computer Science, Data Science and Mathematics (aff), Courant Institute of Mathematical Sciences and Center for Data Science, New York University. Visiting Scholar at Flatiron Institute.
Flatiron Research Fellow at @CCN and CCM
Research in science of {deep learning, AI security, safety}. PhD student at UPenn
davisrbrown.com
AI & Brain Postdoctoral Researcher @MIT
Researching at the intersection of machine and primate vision.
https://ggaziv.github.io
Rogue mathematician
https://davidbessis.substack.com/
Research Director, Founding Faculty, Canada CIFAR AI Chair @VectorInst.
Full Prof @UofT - Statistics and Computer Sci. (x-appt) danroy.org
I study assumption-free prediction and decision making under uncertainty, with inference emerging from optimality.
What's going on?
- programming: github.com/TheLortex
- pictures: instagram.com/elpluvina
- weblog: lortex.org
Formerly known as twitter.com/TheLortex
Deep Learning x {Symmetries, Structures, Randomness} 🦄
Researcher at Flatiron Computational Maths in NYC. PhD from EPFL. https://www.bsimsek.com/
Political scientist at Harvard. www.mashailmalik.com
Theory of neural networks at SISSA in Trieste, Italy




















