alternative view
18.03.2025 13:59 — 👍 2 🔁 0 💬 0 📌 0
mean pooling
18.03.2025 13:59 — 👍 1 🔁 0 💬 1 📌 0
I'm interested in chatting about some data vis work!
03.02.2025 13:52 — 👍 5 🔁 0 💬 0 📌 0

implemented a new rendering component for latent scope's scatter plot. had to replace regl-scatterplot with d3-zoom + regl shaders so we could support mobile
23.01.2025 00:37 — 👍 7 🔁 1 💬 0 📌 0
She is interested in policy, and it sounds like the potential for adopting tech is both exciting and overwhelming. perhaps good examples where tech intervention has had clear benefits. I think plant health would be a great place to start!
18.01.2025 13:00 — 👍 2 🔁 0 💬 0 📌 0
hi Gabriel, do you have any resources/reading to recommend? I have a friend working in Taiwan to improve local agriculture who's interested in learning about tech potential to help
09.01.2025 16:19 — 👍 0 🔁 0 💬 1 📌 0
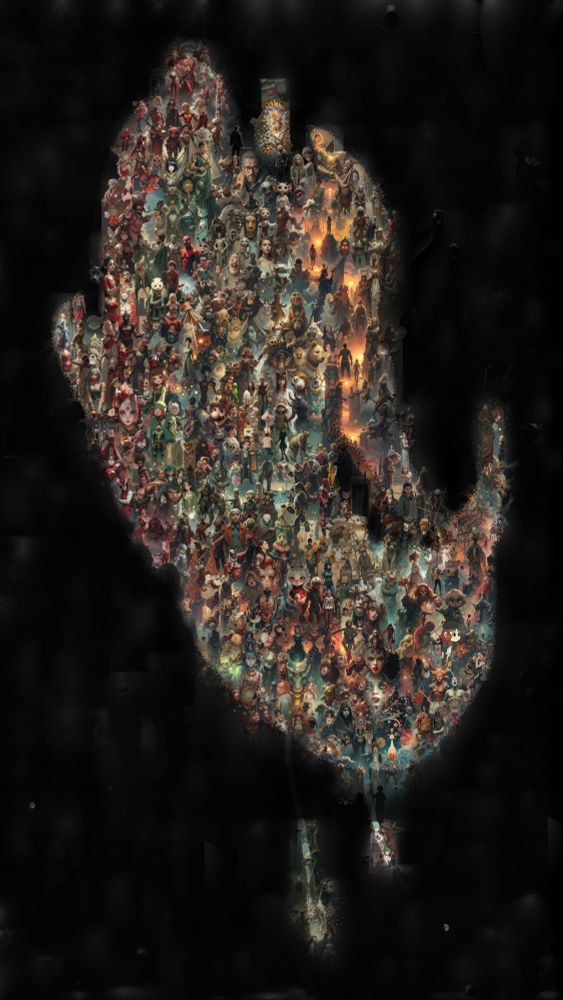
I'll be at @unireps.bsky.social this Saturday presenting a new experimental pipeline to visually explore structured neural network representations. The core idea is to take thousands of prompts that activate a concept, and then cluster and draw them using MultiDiffusion. 🧵👇
11.12.2024 23:18 — 👍 31 🔁 8 💬 2 📌 0
is it the overhead of running / opening / managing notebook files via browser?
I found using notebooks in vscode (and cursor) got me over the hump of "just getting started" since I'm already in the ide so much
07.01.2025 02:12 — 👍 1 🔁 0 💬 1 📌 0
cool! what are you mapping exactly?
30.12.2024 06:44 — 👍 1 🔁 0 💬 1 📌 0
yes, i want to use it for storage but in order to do so i need to do this inefficient conversion. i'm wondering if there is a better choice to store with
10.12.2024 20:27 — 👍 0 🔁 0 💬 1 📌 0
I've been operating under assumption parquet is best way to store intermediate data, but now that I'm trying to handle incoming image data it feels a bit wasteful. especially since converting to bytes is only like 40 it/s
10.12.2024 19:51 — 👍 0 🔁 0 💬 1 📌 0

am i missing something for handling image data in parquet files?
I can load a dataset from HF like:
dataset = load_dataset("Marqo/marqo-ge-sample", split='google_shopping')
df = pd.DataFrame(dataset)
but i need to convert the images to bytes if I want to do:
df.to_parquet("sample.parquet")
10.12.2024 19:51 — 👍 2 🔁 0 💬 1 📌 0
“They said it could not be done”. We’re releasing Pleias 1.0, the first suite of models trained on open data (either permissibly licensed or uncopyrighted): Pleias-3b, Pleias-1b and Pleias-350m, all based on the two trillion tokens set from Common Corpus.
05.12.2024 16:39 — 👍 248 🔁 85 💬 11 📌 19

the algorithm is not some deity but a landscape, the feed is an uber ride across the manifold, only the windows are blacked out. what if you had a map of the algorithm? what if the UX of the feed let you look out of the window?
musing with @infowetrust.com
image from distill.pub/2017/aia/
05.12.2024 01:33 — 👍 6 🔁 3 💬 0 📌 0
Latent Scope
Spent the day playing with this. I'm absolutely blown away @enjalot.bsky.social!
- Chose any embedding from HF
- Project with UMAP, cluster with HDBSCAN
- Use Ollama to label the clusters (Works incredibly well!)
03.12.2024 16:03 — 👍 8 🔁 2 💬 0 📌 0
😙👌📊📈📚
03.12.2024 02:22 — 👍 2 🔁 0 💬 0 📌 0
what's crazy to me is that so many of these can be run very efficiently on an M1 MacBook pro, and just fine on a VM with only CPU.
crazy how much value you can pull out of text without billions of parameters
29.11.2024 17:08 — 👍 6 🔁 0 💬 0 📌 0

If you're interested in embedding models for retrieval (search), clustering, classification, paraphrase mining, etc., then there's now 10,000 fully free and open source options on @hf.co via Sentence Transformers.
Check out the most popular ones here: huggingface.co/models?libra...
29.11.2024 16:40 — 👍 32 🔁 7 💬 2 📌 1

I've organized and participated in many unconferences in the past, and they are always the most intense exchange of ideas and information that I've experienced. Given the energy we're seeing in the registration this one is poised to be no different!
register today!
hiddenstates.org
26.11.2024 18:23 — 👍 1 🔁 1 💬 0 📌 0
After the morning keynotes we will have a short voting session where topics get put on the board and everyone gets a few votes. Then the most popular topics get assigned to different session times. We will have parallel tracks and breakout rooms for the niche topics with dedicated interest too.
26.11.2024 18:23 — 👍 0 🔁 0 💬 1 📌 0
There is lots of interest in steering and alignment by leveraging latest interpretability techniques like SAEs. Many people also brought up dimensionality reduction and visualization as well as better ways to extract structure from models.
So how will everyone get to talk about these topics?
26.11.2024 18:23 — 👍 0 🔁 0 💬 1 📌 0
The beauty of the unconf format is the self-organizing nature, people find each other based on common curiosities. We have noticed some themes in the topics shared during registration:
Lot's of people want to go beyond the chat interface, and there appear to be lots of ideas for how to do that.
26.11.2024 18:23 — 👍 0 🔁 0 💬 1 📌 0
First we've got 2 amazing keynote speakers to kick off the day: @lelandmcinnes.bsky.social and @thesephist.com
Leland has built indispensable tools for working with model internals, namely UMAP, HDBSCAN and DataMapPlot.
Linus has published inspiring design research interfacing with hidden states.
26.11.2024 18:23 — 👍 1 🔁 0 💬 1 📌 0
We've hit a critical mass of registrations! The caliber of attendees is exciting, we've got researchers from companies big and small, academic and indie. We've got prototypers and UXers who have worked on bleeding-edge interfaces as well as house-hold names.
let's talk about the unconf experience:
26.11.2024 18:23 — 👍 2 🔁 1 💬 1 📌 0

Hidden States is happening next week in SF!
It's a one-day unconference gathering researchers, designers, prototypers and engineers interested in pushing the boundaries of AI interfaces, going below the API and working with the hidden states.
hiddenstates.org
26.11.2024 18:23 — 👍 12 🔁 2 💬 1 📌 2
enjalot's tweets | Latent Scope
I've also made another tool for exploring unstructured text data (i.e. tweets) via a map of sorts:
enjalot.github.io/latent-scope...
26.11.2024 00:57 — 👍 3 🔁 0 💬 1 📌 0


If you do this with enough data you start to get a map of the patterns found in your dataset.
When you embed new data, like the question for a RAG query, you can see where on the map it lands.
21.11.2024 19:29 — 👍 2 🔁 0 💬 1 📌 0


You can map more and more points, a less similar point will show up a little further away.
As you add more points a map starts to form, with clusters of similar data spread out before you
21.11.2024 19:29 — 👍 3 🔁 0 💬 1 📌 0
Climate graphics reporter and columnist at the Washington post. www.sadbumblebee.buzz
Empowering humans, one pixel at a time. #ux #dataviz
https://github.com/vasturiano
https://observablehq.com/@vasturiano
Computer vision and digital modeling of the built environment. Foraging for productive patterns.
Director of Data Science and Research at Common App, focused on higher ed access and success with policy, data, data viz, NLP, and R // PhD @ UVA Edu / MPP @ UVA Batten // www.brhkim.com // commonapp.org/research
🎏 Visual Artist https://onecm.com
✂️ Making https://cuttle.xyz
🆗 Founder https://oknk.studio
🦑 Creator https://seaquence.app
🦇 Drone Pilot https://youtube.com/@lioku
Socials
🐘 Mastodon https://vis.social/@notlion
🤳 IG https://instagram.com/lioku
:-)
https://folk.computer/
https://cwervo.com
Likes to draw ✍🏻
Strong with the Force ✨
I make stuff sometimes!
when i’m not blacksmithing, i shepard a research engineering team at apple
creations with code and networks
https://ollieliu.com/; oliver irl
phd'ing in ml@usc; prev. ml@cmu, msr
multimodal foundation models, ai4sci, decision making
Google Chief Scientist, Gemini Lead. Opinions stated here are my own, not those of Google. Gemini, TensorFlow, MapReduce, Bigtable, Spanner, ML things, ...
software imagineering™ riichi mahjong 🀅 kidney donor
seattle ∞ https://tarng.com
Engineering Leader & Architect @hoppr.ai
#radsky #medsky
former 🥑 dev advocate @rstudio, 🏀 hoop head, data-viz lover, gnashgab, blatherskite, #rstats, doggos, and horses
Designer working with data visualization and machine learning.
Physics, Visualization and AI PhD @ Harvard | Embedding visualization and LLM interpretability | Love pretty visuals, math, physics and pets | Currently into manifolds
Wanna meet and chat? Book a meeting here: https://zcal.co/shivam-raval
Scientist III @ Allen Institute
🛠️ https://rhngla.github.io/
Assoc Prof Computer Science at WPI— we study data visualization
Data insights and creator of mplsoccer, a Python library for football viz.
























