We're excited about the upcoming Computational Psychology preconference at @spspnews.bsky.social this Thursday. See our action-packed full day agenda below! Featuring 3 keynote talk themes with related early-career speakers, data blitz session, panel discussion. Don't miss it! #SPSP
24.02.2026 18:08 —
👍 21
🔁 9
💬 1
📌 1
If you made it this far, I encourage you to check out the paper for the full story!
Big props to @aakriti1kumar.bsky.social who led this paper and our wonderful team of interdisciplinary collaborators Fai Poungpeth, Diyi Yang, Erina Farrell, Bruce Lambert
Stay tuned for more!
11.02.2026 15:11 —
👍 2
🔁 0
💬 0
📌 0
Open questions: What is the right evaluation framework for a given conversational context? And, when are LLMs less likely to be good judges? My suspicion to this last question is when there's high context between two people like two close friends, the judgment is likely to hold less water.
11.02.2026 15:11 —
👍 2
🔁 0
💬 1
📌 0
🔵 LLMs could power coaching advice to everyday people on how to be better active listeners and make others feel more heard
🔵 LLMs could power scalable professional development offering nuanced evaluation to customer service reps, medical students, and therapists-in-training
11.02.2026 15:11 —
👍 3
🔁 0
💬 1
📌 0
With evidence that LLMs can judge empathic communication in these contexts, here are some future possibilities that I can imagine:
🔵 LLMs-as-judge can create transparency and accountability into when LLMs-as-companions might be going off the rails
11.02.2026 15:11 —
👍 2
🔁 0
💬 1
📌 0

Beyond the fact that objective ground truth is elusive, the problem w/ classification:
(a) imbalanced classes and off-by-one errors obscure performance
(b) variations in rating scales leads to incommensurability between scales
(c) binarization offers research degrees of freedom to juke the stats
11.02.2026 15:11 —
👍 2
🔁 0
💬 1
📌 0
Key finding: Across the same high-level task measured via four different frameworks in four different settings, we find that appropriately prompted LLMs judge the nuances of empathic communication nearly as reliably as experts
So, why not report simple AUC or accuracy?
11.02.2026 15:11 —
👍 2
🔁 0
💬 1
📌 0

Example conversations show how annotations converge and align across these three groups
Crowd judgments are generally more positive and more variable, which we suspect is due to a combo of acquiescence bias and variability of their effort and experience (see more in the SI)
11.02.2026 15:11 —
👍 2
🔁 0
💬 1
📌 0


Experts' agreement with each other varies considerably across the 4 frameworks and their 21 sub-dimensions
👉 But, objective ground truth is elusive for this task
For each dimension, we find relatively high IRR between experts and LLMs but much less between experts and crowds
11.02.2026 15:11 —
👍 2
🔁 0
💬 1
📌 0

🚨 New in @natmachintell.nature.com 🚨 We collected 9000+ annotations of empathic communication in convos from experts, crowds & LLMs across 4 NLP/comms/psych frameworks
LLM judgment exceeds crowds' reliability & nearly matches experts
Soft skills can now be reliably measured by LLMs 🧵
11.02.2026 15:11 —
👍 14
🔁 4
💬 2
📌 0


Happy 2026!!! In the spirit of reflecting on the past year as we begin a new one, I am sharing what our lab has been up to. Read on to learn about the q's we’re asking, find links to papers and media appearances, and see a pic of the lab at a Cubs game!
01.01.2026 17:36 —
👍 4
🔁 2
💬 0
📌 0
Looking forward to @maxkreminski.bsky.social speaking @nicoatnu.bsky.social tomorrow!
21.10.2025 21:16 —
👍 3
🔁 0
💬 0
📌 0
Happening today!
08.10.2025 13:49 —
👍 2
🔁 0
💬 0
📌 0

On my way to @ic2s2.bsky.social in Norrköping!! Super excited to share this year’s projects in the HAIC lab revealing how (M)LLMs can offer insights into human behavior & cognition
More at human-ai-collaboration-lab.kellogg.northwestern.edu/ic2s2
See you there!
#IC2S2
21.07.2025 08:25 —
👍 6
🔁 0
💬 0
📌 0
Thanks! I imagine we'd see similar results in the Novelty Challenge that when experts are reliable we can fine-tune LLMs to be reliable but experts may only be reliable in some disciplines/settings and less reliable in others.
Very cool challenge!!
18.06.2025 13:33 —
👍 0
🔁 0
💬 0
📌 0
When are LLMs-as-judge reliable?
That's a big question for frontier labs and it's a big question for computational social science.
Excited to share our findings (led by @aakriti1kumar.bsky.social!) on how to address this question for any subjective task & specifically for empathic communications
17.06.2025 15:23 —
👍 7
🔁 1
💬 1
📌 0
Thank you for sharing your brilliance, quirks, and wisdom. I started reading your work after coming across your Aeon article on Awe many years ago, and I feel inspired everytime I read what you write.
29.05.2025 14:17 —
👍 5
🔁 0
💬 0
📌 0
negrain.bsky.social
And follow negrain.bsky.social who just joined Blue Sky today!
25.04.2025 15:18 —
👍 1
🔁 0
💬 1
📌 0
YouTube video by Negar Kamali
CHI 2025 - Characterizing Photorealism and Artifacts in Diffusion Model-Generated Images
If you're curious about learning more, say hi to
Negar Kamali at #CHI2025 and see video
Awesome collaboration with
Karyn, @aakriti1kumar.bsky.social, Angelos, @jessicahullman.bsky.social
Video: youtu.be/PL_ggNzMd-o?...
Preprint: arxiv.org/pdf/2502.11989
CHI: dl.acm.org/doi/10.1145/...
25.04.2025 15:15 —
👍 3
🔁 1
💬 1
📌 0
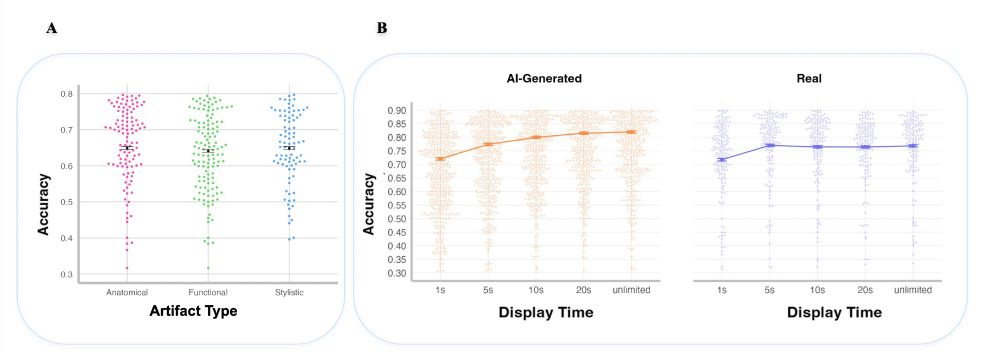
This taxonomy offers a shared language (and see our how to guide on arXiv for many examples) to help people better communicate what looks or feels off.
It's also a framework that can generalize to multimedia.
Consider this, what do you notice at the 16s mark about her legs?
25.04.2025 15:15 —
👍 2
🔁 0
💬 1
📌 0

Based on generating thousands of images, reading the AI-generated images and digital forensics literatures (and social media and journalistic commentary), analyzing 30k+ participant comments, we propose a taxonomy for characterizing diffusion model artifacts in images
25.04.2025 15:15 —
👍 1
🔁 0
💬 1
📌 0
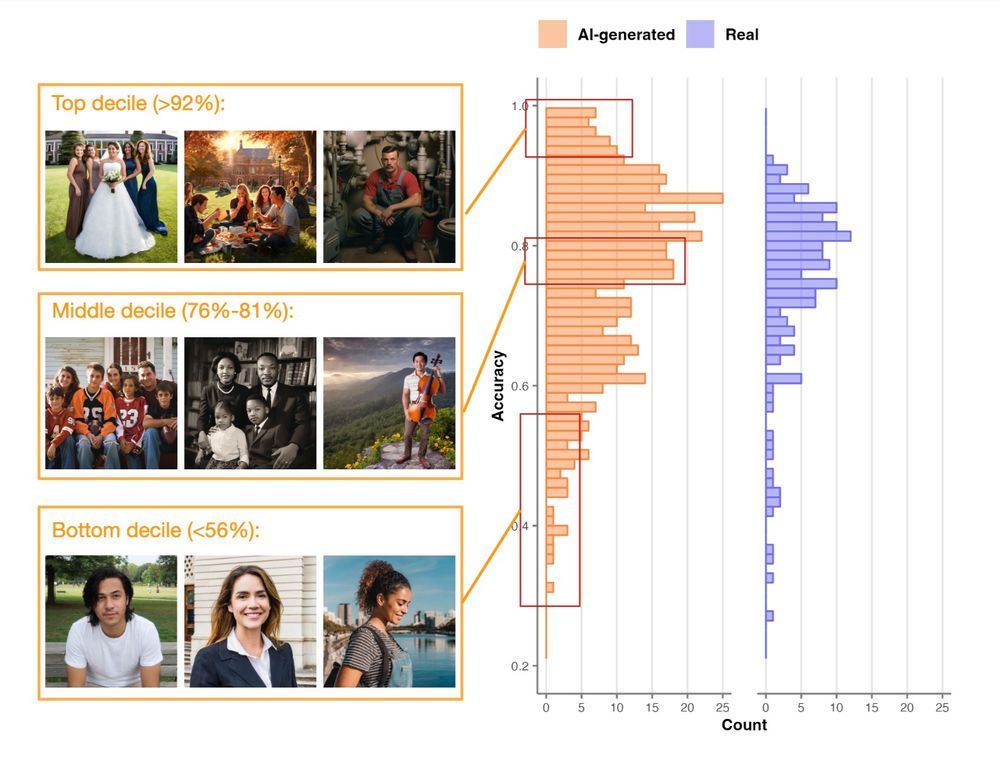
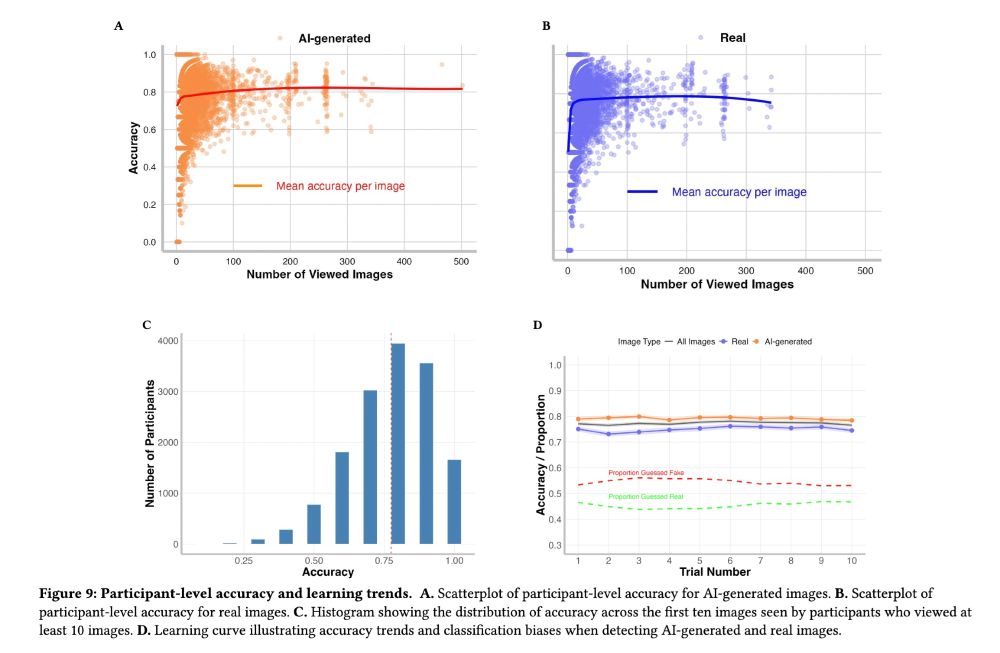
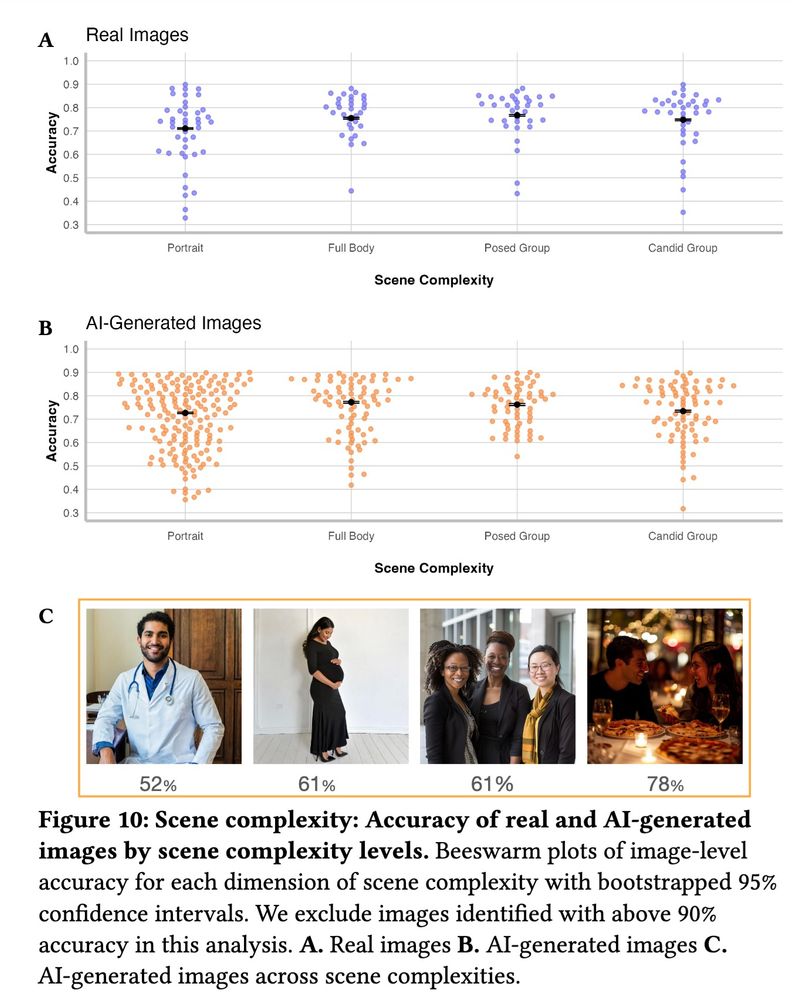
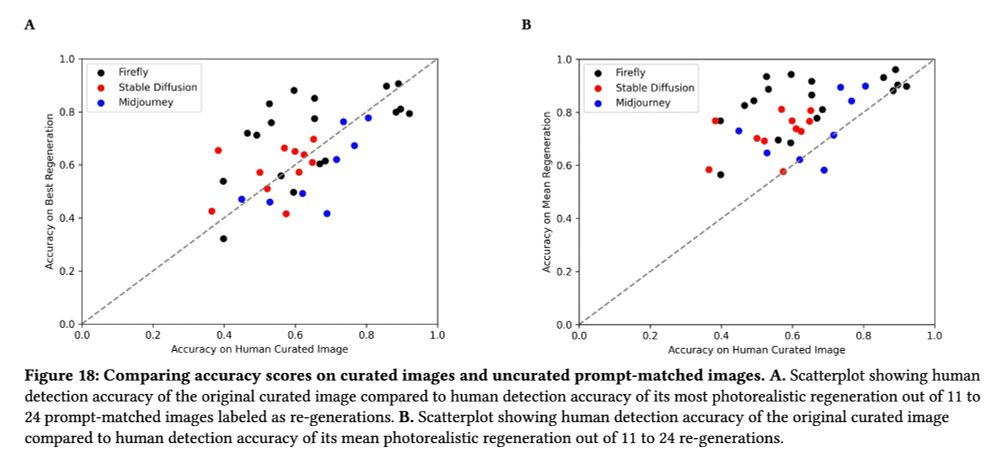
We examine photorealism in generative AI by measuring people's accuracy at distinguishing 450 AI-generated and 150 real images
Photorealism varies from image to image and person to person
83% of AI-generated images are identified as AI better than random chance would predict
25.04.2025 15:15 —
👍 1
🔁 0
💬 1
📌 0
💡New paper at #CHI2025 💡
Large scale experiment with 750k obs addressing
(1) How photorealistic are today's AI-generated images?
(2) What features of images influence people's ability to distinguish real/fake?
(3) How should we categorize artifacts?
25.04.2025 15:15 —
👍 16
🔁 4
💬 2
📌 0
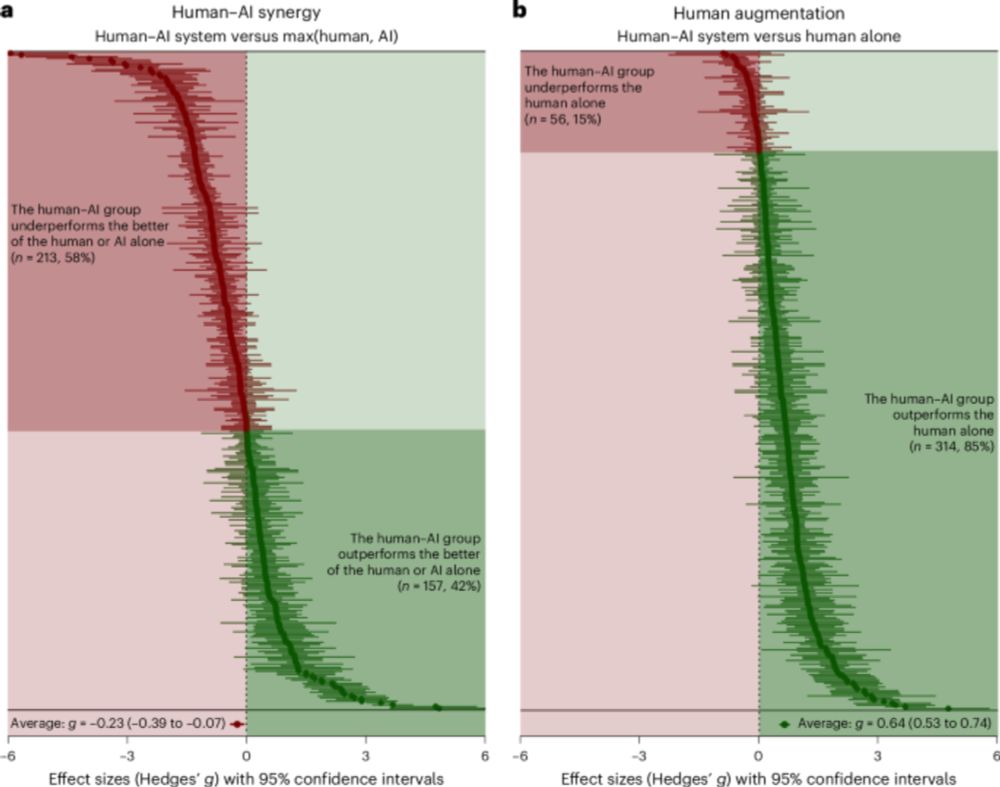
At a high level, it depends on:
- human expertise
- human understanding for what the AI system is capable of
- quality of AI explanations
- task-specific potential for cognitive biases and satisficing constraints to influence humans
- instance-specific potential for OOD data to influence AI
03.04.2025 14:18 —
👍 4
🔁 0
💬 1
📌 0