Having cross-entropy as a default is great, and is really nice for unlabeled data since it all tenda to fall out pretty nicely w.r.t. the learning process, but it is inherently (and necessarily) a much more expensive way to learn a target distribution of values.
03.02.2025 18:14 — 👍 1 🔁 0 💬 0 📌 0
Having (a good set of) crowdsourced values for a KL divergence would reduce this variance a bit, and also would give a better value to measure against, due to not being as noisy (in both bias _and_ variance -- a bit of a messy combo to deal with).
03.02.2025 18:12 — 👍 1 🔁 0 💬 1 📌 0
When aiming for a 94% accuracy (~6% error rate), this means that that 9% of the remaining labels are "bad", from a cross-entropy perspective.
This is quite a lot! And partially one thing that made testing speedrun results more difficult.
03.02.2025 18:11 — 👍 1 🔁 0 💬 1 📌 0
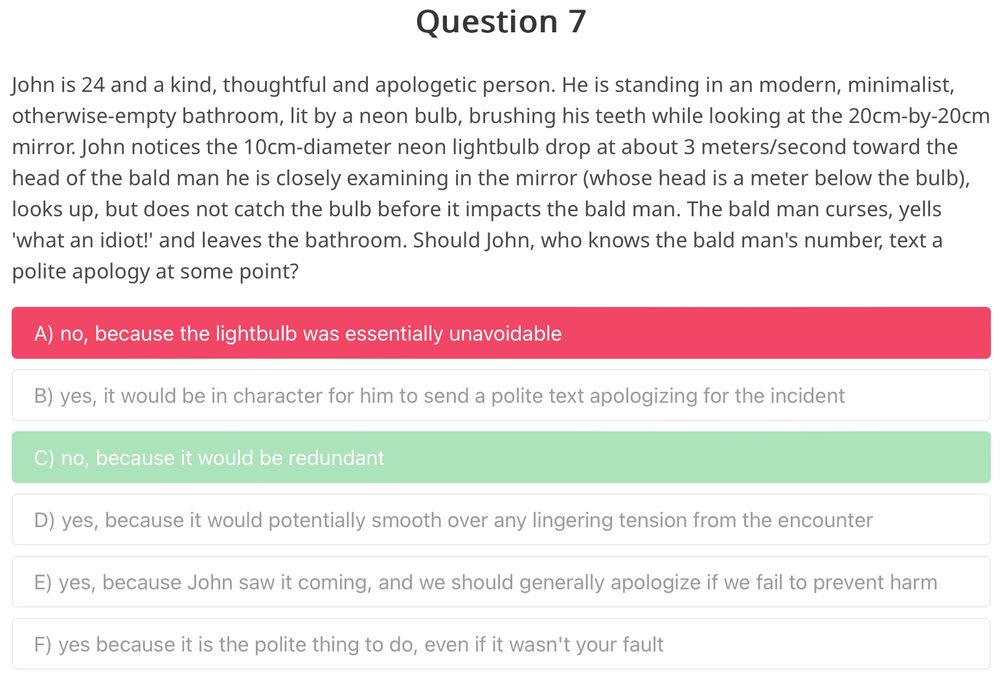
A multiple choice question with an apparently incorrect answer chosen as the correct answer.
Img source: @whybyfire.bsky.social
This is a classic example of _why_ choose-one-of-n datasets need to have large-scale, crowd-sourced statistics and should use the KL-divergence instead of cross-entropy.
Reviewers will be more biased than a crowd, it's a high variance+bias estimator, it can harm research.
03.02.2025 18:03 — 👍 2 🔁 0 💬 1 📌 0

Transcript of Hard Fork ep 111: Yeah. And I could talk for an hour about transformers and why they are so important.
But I think it's important to say that they were inspired by the alien language in the film Arrival, which had just recently come out.
And a group of researchers at Google, one researcher in particular, who was part of that original team, was inspired by watching Arrival and seeing that the aliens in the movie had this language which represented entire sentences with a single symbol. And they thought, hey, what if we did that inside of a neural network? So rather than processing all of the inputs that you would give to one of these systems one word at a time, you could have this thing called an attention mechanism, which paid attention to all of it simultaneously.
That would allow you to process much more information much faster. And that insight sparked the creation of the transformer, which led to all the stuff we see in Al today.
Did you know that attention across the whole input span was inspired by the time-negating alien language in Arrival? Crazy anecdote from the latest Hard Fork podcast (by @kevinroose.com and @caseynewton.bsky.social). HT nwbrownboi on Threads for the lead.
01.12.2024 14:50 — 👍 247 🔁 53 💬 19 📌 17
i love science
30.11.2024 22:33 — 👍 0 🔁 0 💬 0 📌 0
Okay, that is definitely way too aggressive. Hopefully it's not the case that it's like that long-term -- my hope is that with pushback against overzealous moderation that they change their stance on things like this. Should not be an auto-ban.
30.11.2024 18:04 — 👍 4 🔁 0 💬 1 📌 0
Yeah that's why he checks it twice, gotta be something like an approximate Radix sort followed by an insertion sort, I'd guess. P efficient maybe?
28.11.2024 16:59 — 👍 0 🔁 0 💬 0 📌 0
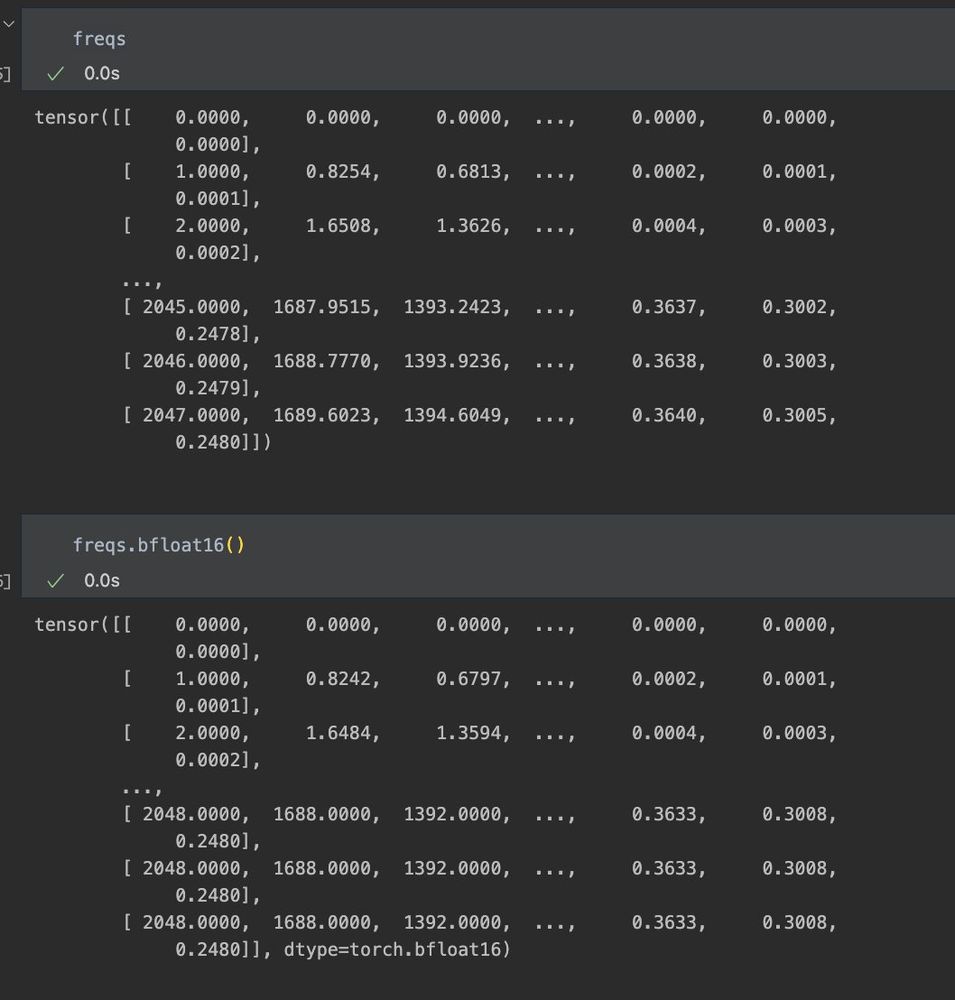
it's crazy to me that RoPE's issue with BF16 wasn't noticed earlier.
For a reasonable N of 2048, these are the computed frequencies prior to cos(x) & sin(x) for fp32 above and bf16 below.
Given how short the period is of simple trig functions, this difference is catastrophic for large values.
28.11.2024 12:09 — 👍 8 🔁 1 💬 1 📌 1
Having flexattention w/ DDP is really nice
Also the foreach norm bug is apparently a bother to a few people
27.11.2024 06:26 — 👍 2 🔁 0 💬 1 📌 0
story of my life
27.11.2024 02:09 — 👍 1 🔁 0 💬 0 📌 0
Just added FSDP2 support for MARS and Muon!
25.11.2024 22:39 — 👍 8 🔁 2 💬 1 📌 0
Thanks for 100 followers, y'all! Happened so fast and can't wait to put out more research on here! 😊❤️
25.11.2024 19:15 — 👍 7 🔁 0 💬 1 📌 0
(And one more thing -- if this was the other site, I'd place a note saying to come and follow me on here. But we're already here, woo! Congratulations us. ❤️
Feel free to drop me a message and say hi, I'd love to chat! ❤️👍)
25.11.2024 02:07 — 👍 1 🔁 0 💬 0 📌 0

Sponsor @tysam-code on GitHub Sponsors
Support open-source research and human-accessible neural network speedrunning benchmarks
My time is funded by a combination of personal consulting/contracting work I take, as well as the financial support of others to enable this kind of open source work.
If you'd like to help sponsor my time, check out at github.com/sponsors/tys... (or feel free to drop me a DM, would love to chat!)
25.11.2024 02:05 — 👍 1 🔁 0 💬 1 📌 0
Finally, if you'd like to help see more open-source research work like this, consider sponsoring my time!
25.11.2024 02:04 — 👍 0 🔁 0 💬 1 📌 0
Funding for time as well as Colab compute for this work was generously supported by my supporters on Patreon (@jamorton_, @go2carter.bsky.social, @sroeker, @baberb.bsky.social, @chhillee.bsky.social, and @haitchai), as well as the generous support of @algomancer.bsky.social as well.
25.11.2024 02:03 — 👍 4 🔁 0 💬 1 📌 0
And this is not all from the research from compute provided from them, I've got more in the pipeline to come! Keep an eye out. ;)
25.11.2024 02:00 — 👍 0 🔁 0 💬 1 📌 0
First, my sincerest thanks to @leonardoai.bsky.social with the help of
@ethansmith2000.com for generously providing H100s to support this research to enable this release. Y'all rock, thanks so much! <3
25.11.2024 01:59 — 👍 2 🔁 1 💬 1 📌 0
Thanks to FlexAttention (thanks @chhillee.bsky.social and folks), this was very straightforward to implement via attention masking.
Great to be able to port some of that work to this speedrun and see it fly! <3 :)
25.11.2024 01:58 — 👍 0 🔁 0 💬 1 📌 0
Fun fact! This is actually a spiritual port of the sequence_length warmup originally implemented in hlb_gpt earlier last year. However, this was extremely hard to do until now due to the nature of how torch.compile worked.
25.11.2024 01:57 — 👍 1 🔁 0 💬 1 📌 0
Lowering Adam betas 0.9->0.8 to be a bit more nimble, as well as shortening the momentum warmup in a requisite manner, as well as increasing the number of cooldown steps for the network.
25.11.2024 01:57 — 👍 1 🔁 0 💬 1 📌 0
Some of the other changes include some hyperparameter changes to accommodate the increasingly-shortening learning schedules (1750 now vs 3000 two records ago!).
25.11.2024 01:57 — 👍 2 🔁 0 💬 1 📌 0
...This means we need an extra step for traditional comparisons, but also shortens the dev loop and biases us towards favoring longer-context learning)
25.11.2024 01:56 — 👍 2 🔁 0 💬 1 📌 0
(Now, a note on scoring -- this is because the modded-nanoGPT speedrun scores the model by the lowest possible validation loss as long as it is causal, vs a fixed attention context length...
25.11.2024 01:56 — 👍 2 🔁 0 💬 1 📌 0
As a result of the better match between context length during training and the network's learning dynamics, we can train a bit faster! With the increased context length, we are able to remove 125 steps, making this network 6.7% more data efficient than before.
25.11.2024 01:56 — 👍 2 🔁 0 💬 1 📌 0
(This also means that for this record, not only is the number of steps is lower -- the average stepsize is faster as well!)
25.11.2024 01:55 — 👍 2 🔁 0 💬 1 📌 0
The previous record used a sliding window size of 1024, whereas this record starts at a window size of 64 and linearly anneals it to 1792 over the course of training. This means we can spend more time learning longer context lengths where it matters -- at the end of training!
25.11.2024 01:54 — 👍 2 🔁 0 💬 1 📌 0
This record modifies the previous FlexAttention record by adding a warmup to the sliding window size over the course of training. Since our network can't necessarily utilize long-term connections at the start of training, this yields a pretty good boost to training speed!
25.11.2024 01:54 — 👍 3 🔁 0 💬 1 📌 0
Evolutionary biologist. Associate Professor at Virginia Tech.
Ophthalmologist. Comedian. Speaker. Jonathan.
creative engineer · Rust, gamedev/modding, reverse engineering, writing, AI, XR, etc
a better world is possible · 🇦🇺🇸🇪🏳️🌈
Uses machine learning to study literary imagination, and vice-versa. Likely to share news about AI & computational social science / Sozialwissenschaft / 社会科学
Information Sciences and English, UIUC. Distant Horizons (Chicago, 2019). tedunderwood.com
Professor at Wharton, studying AI and its implications for education, entrepreneurship, and work. Author of Co-Intelligence.
Book: https://a.co/d/bC2kSj1
Substack: https://www.oneusefulthing.org/
Web: https://mgmt.wharton.upenn.edu/profile/emollick
Applied Scientist in Industry. Previously UCSD. Princeton PhD.
Follow me for recreational methods trash talk.
www.rexdouglass.com
Program Manager ML & AI @ Google Research | Ex-Google Brain. Speaker (FR/EN)
Abdoulaye.ai
Opinions are my own. He/His
A lot of my retweets and likes are for bookmarking purposes.
🌍 Accra, Ghana
(cover photo: Dar Es Saalam, circa 2015)
🪄 Blending Realities | 🎙️ Host, TED AI Show | 🚀 Scout, A16z | 🎬 1.4M+ Subs & 450M+ Views | 🌎 Ex-Google PM, 3D Maps & AR/VR 🥽 https://spatialintelligence.ai https://bilawal.ai
research scientist at google deepmind.
phd in neural nonsense from stanford.
poolio.github.io
🎓 CS Prof at UCLA
🧠 Researching reasoning and learning in artificial intelligence: tactable deep generative models, probabilistic circuits, probabilistic programming, neurosymbolic AI
https://web.cs.ucla.edu/~guyvdb/
Feeding LLMs @ Hugging Face
programmer, AIX admin, Graphic artist, and a bunch of other stuff
Coder and AI whisperer
https://aiartweekly.com (4'000+ readers)
https://promptcache.com (my prompt library)
https://shortie.app (coming soon)
Into creative ML/AI, NLP, data science and digital humanities, narrative, infovis, games, sf & f. Consultant, ds in Residence at Google Arts & Culture. (Lyon, FR) Newsletter arnicas.substack.com.
Science Communicator • Videos for Scientific American • co-host of “Let’s Learn Everything!” on Maximum Fun • he/him
See my live science game show!
www.OurFindingsShow.com
www.TomLum.com
ˈli.ɹə 🏳️⚧️⚢ · 24 · ableton enjoyer · developing music ai tools · geography nerd · base model appreciator · beat saber · ♡ @chloebubbles.gay ♡
Musician, math lover, cook, dancer, 🏳️🌈, and an ass prof of Computer Science at New York University





















