
Thoughtful essay on power concentration from AI
freesystems.substack.com/p/the-enligh...

@tom4everitt.bsky.social
AGI safety researcher at Google DeepMind, leading causalincentives.com Personal website: tomeveritt.se
Thoughtful essay on power concentration from AI
freesystems.substack.com/p/the-enligh...
Keeping chains-of-thought traces reflective of the models true reasoning would be very helpful for safety. Important work to explore the ways it may fail
21.11.2025 20:47 — 👍 1 🔁 0 💬 0 📌 0
Could be. But also found this interesting about the link to universal child care
www.economist.com/finance-and-...

The abstract of the consistency training paper.
New Google DeepMind paper: "Consistency Training Helps Stop Sycophancy and Jailbreaks" by @alexirpan.bsky.social, me, Mark Kurzeja, David Elson, and Rohin Shah. (thread)
04.11.2025 00:18 — 👍 18 🔁 5 💬 1 📌 1[1/9] Excited to share our new paper "A Pragmatic View of AI Personhood" published today. We feel this topic is timely, and rapidly growing in importance as AI becomes agentic, as AI agents integrate further into the economy, and as more and more users encounter AI.
31.10.2025 12:32 — 👍 55 🔁 15 💬 3 📌 7"We think that Mars could be green in our lifetime
This is not an Earth clone, but rather a thin, life-supporting envelope that still exhibits large day-to-night temperature swings but blocks most radiation. Such a state would allow people to live outside on the planet’s surface"
Very cool!
I was initially confused how they managed to do a randomized control trial on this. Seems they in each workflow randomly turned on the tool for a subset of the customers
15.10.2025 20:11 — 👍 1 🔁 0 💬 0 📌 0the focus on practical capacities is very sensible! though on basis on that, I thought you would focus on what LLMs do to humans' practical capacity to feel empathy with other beings, rather than whether LLMs satisfy humans' need to be emphasized with
09.10.2025 20:15 — 👍 0 🔁 0 💬 0 📌 0Interesting. Could the measure also be applied to the human, assessing changes to their empowerment over time?
02.10.2025 19:57 — 👍 2 🔁 0 💬 1 📌 0Interesting, does the method rely on being able to set different goals for the LLM?
02.10.2025 17:11 — 👍 0 🔁 0 💬 1 📌 0
Evaluating the Infinite
🧵
My latest paper tries to solve a longstanding problem afflicting fields such as decision theory, economics, and ethics — the problem of infinities.
Let me explain a bit about what causes the problem and how my solution avoids it.
1/N
arxiv.org/abs/2509.19389
Interesting. I recall Rich Sutton made a similar suggestion in the 3rd edition of his RL book, arguing we should optimize average reward rather than discount
25.09.2025 20:22 — 👍 1 🔁 0 💬 0 📌 0Do you have a PhD (or equivalent) or will have one in the coming months (i.e. 2-3 months away from graduating)? Do you want to help build open-ended agents that help humans do humans things better, rather than replace them? We're hiring 1-2 Research Scientists! Check the 🧵👇
21.07.2025 14:21 — 👍 19 🔁 6 💬 3 📌 0digital-strategy.ec.europa.eu/en/policies/... The Code also has two other, separate Chapters (Copyright, Transparency). The Chapter I co-chaired (Safety & Security) is a compliance tool for the small number of frontier AI companies to whom the “Systemic Risk” obligations of the AI Act apply.
2/3
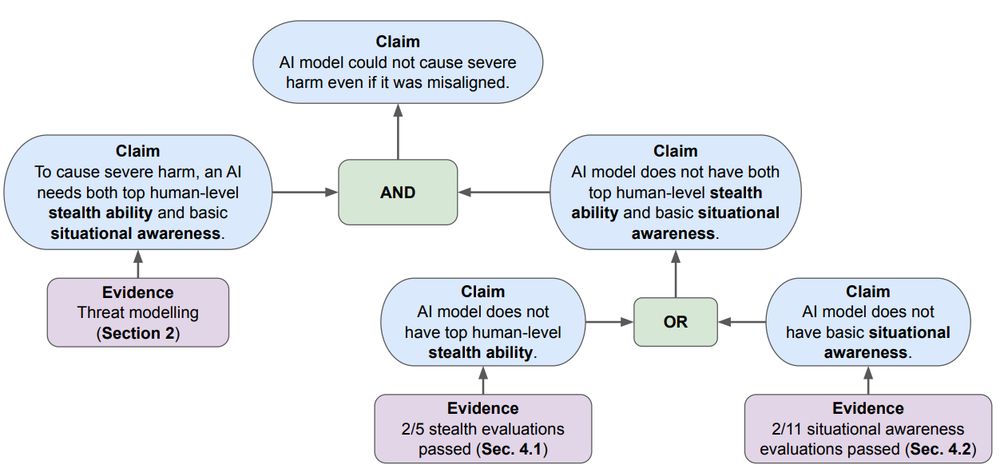
As models advance, a key AI safety concern is deceptive alignment / "scheming" – where AI might covertly pursue unintended goals. Our paper "Evaluating Frontier Models for Stealth and Situational Awareness" assesses whether current models can scheme. arxiv.org/abs/2505.01420
08.07.2025 12:10 — 👍 6 🔁 1 💬 1 📌 1
First position paper I ever wrote. "Beyond Statistical Learning: Exact Learning Is Essential for General Intelligence" arxiv.org/abs/2506.23908 Background: I'd like LLMs to help me do math, but statistical learning seems inadequate to make this happen. What do you all think?
08.07.2025 02:21 — 👍 52 🔁 9 💬 4 📌 1
Can frontier models hide secret information and reasoning in their outputs?
We find early signs of steganographic capabilities in current frontier models, including Claude, GPT, and Gemini. 🧵
This is an interesting explanation. But surely boys falling behind is nevertheless an important and underrated problem?
27.06.2025 21:07 — 👍 2 🔁 0 💬 0 📌 0Interesting. But is case 2 *real* introspection? It infers its internal temperature based on its external output, which feels more like inference based on exospection rather than proper introspection. (I know human "intro"spection often works like this too, but still)
10.06.2025 19:50 — 👍 0 🔁 0 💬 1 📌 0Thought provoking
07.06.2025 18:22 — 👍 7 🔁 1 💬 0 📌 0… and many more! Check out our paper arxiv.org/pdf/2506.01622, or come chat to @jonrichens.bsky.social, @dabelcs.bsky.social or Alexis Bellot at #ICML2025
04.06.2025 15:54 — 👍 0 🔁 0 💬 0 📌 0
Causality. In previous work we showed a causal world model is needed for robustness. It turns out you don’t need as much causal knowledge of the environment for task generalization. There is a causal hierarchy, but for agency and agent capabilities, rather than inference!
04.06.2025 15:51 — 👍 2 🔁 0 💬 1 📌 0
Emergent capabilities. To minimize training loss across many goals, agents must learn a world model, which can solve tasks the agent was not explicitly trained on. Simple goal-directedness gives rise to many capabilities (social cognition, reasoning about uncertainty, intent…).
04.06.2025 15:51 — 👍 1 🔁 0 💬 1 📌 0Safety. Several approaches to AI safety require accurate world models, but agent capabilities could outpace our ability to build them. Our work gives a theoretical guarantee: we can extract world models from agents, and the model fidelity increases with the agent's capabilities.
04.06.2025 15:51 — 👍 1 🔁 0 💬 1 📌 0
Extracting world knowledge from agents. We derive algorithms that recover a world model given the agent’s policy and goal (policy + goal -> world model). These algorithms complete the triptych of planning (world model + goal -> policy) and IRL (world model + policy -> goal).
04.06.2025 15:50 — 👍 0 🔁 0 💬 1 📌 0Fundamental limitations on agency. In environments where the dynamics are provably hard to learn, or where long-horizon prediction is infeasible, the capabilities of agents are fundamentally bounded.
04.06.2025 15:50 — 👍 1 🔁 0 💬 1 📌 0No model-free path. If you want to train an agent capable of a wide range of goal-directed tasks, you can’t avoid the challenge of learning a world model. And to improve performance or generality, agents need to learn increasingly accurate and detailed world models.
04.06.2025 15:49 — 👍 1 🔁 0 💬 1 📌 0These results have several interesting consequences, from emergent capabilities to AI safety… 👇
04.06.2025 15:49 — 👍 3 🔁 0 💬 1 📌 0And to achieve lower regret, or more complex goals, agents must learn increasingly accurate world models. Goal-conditioned policies are informationally equivalent to world models! But only for goals over mutli-step horizons, myopic agents do not need to learn world models.
04.06.2025 15:49 — 👍 1 🔁 0 💬 1 📌 0
Specifically, we show it’s possible to recover a bounded error approximation of the environment transition function from any goal-conditional policy that satisfies a regret bound across a wide enough set of simple goals, like steering the environment into a desired state.
04.06.2025 15:49 — 👍 2 🔁 0 💬 1 📌 0


















