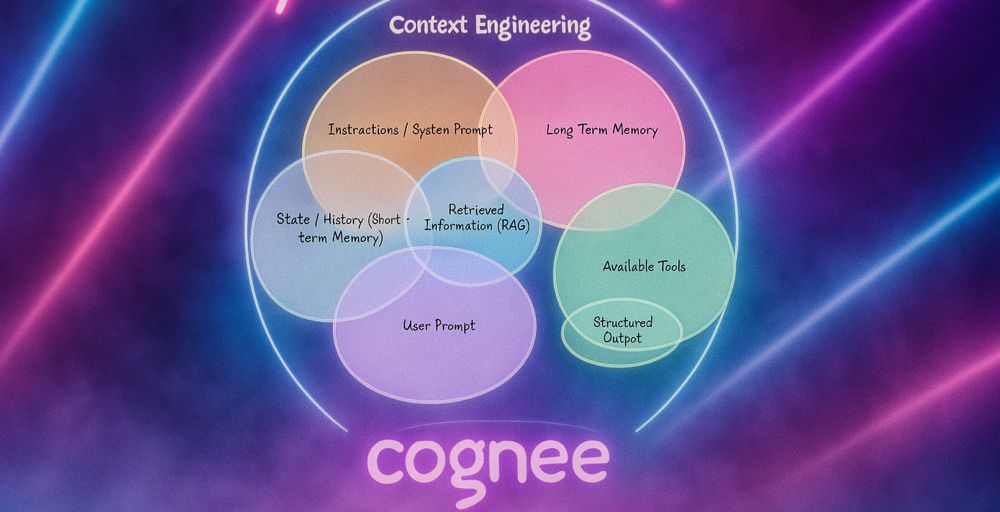
Here’s the distilled version of what everyone has been talking about “context engineering”.
Straight talk on memory layers, GraphRAG and why prompt hacks alone won’t cut it.
Give it a read 👉🏼 dub.sh/context_engi...

@vasilijee.bsky.social
Founder @cognee.bsky.social | cognee.ai OSS: github.com/topoteretes/... Community: discord.gg/m63hxKsp4p
Here’s the distilled version of what everyone has been talking about “context engineering”.
Straight talk on memory layers, GraphRAG and why prompt hacks alone won’t cut it.
Give it a read 👉🏼 dub.sh/context_engi...
Hello, world—with context! 🧠
🚀 We are launching “Insights into AI Memory”—a monthly signal on the tech, tools & people teaching AI to remember.
Grab the initial post & subscribe 👉 aimemory.substack.com

We’re days away from opening the cognee SaaS beta 🚀 where you’ll bring your knowledge graphs & LLM workflows to life without the infra pain.
🔍 Built for everyone who cares about clean data, speed, and reproducibility.
Want in on day 1? Join the waitlist →
dub.sh/beta-saas-co...

⚡ Learn the BaseRetriever pattern
⚡ See real code snippets
⚡ Take the “Which Retriever Are You?” quiz
Read to get smarter answers? Let me know which retriever you are 🙂
dub.sh/cognee-retri...
Tired of asking brilliant questions and getting “meh” answers from your LLM?
We just shipped “The Art of Intelligent Retrieval”—a deep dive into how Cognee layers semantic search, vector DBs & knowledge-graph magic across specialized retrievers (RAG, Cypher, CoT, more)
Bottom line: if you’re building agents, assitants, or automated workflows, it’s time to evolve from “data lake” to AI memory “lake”.
- Read the deep dive ➡️ dub.sh/file-based-m...
- GitHub ➡️ github.com/topoteretes/...
- Join us on Discord ➡️ discord.com/invite/tV7pr...
We also introduce dreamify - our optimization engine that tunes chunk sizes, retriever configs & prompts in real time for max accuracy and latency ✨
12.06.2025 14:48 — 👍 0 🔁 0 💬 1 📌 0Why file-based?
• Cheap, cloud-native (S3, GCS)
• Scales linearly with data growth
• Easy diff + version control
• Plays nicely with existing ETL & BI stacks
It’s a living system:
1️⃣ User adds data
2️⃣ Data is cognified
3️⃣ Search & reasoning improve
4️⃣ Feedback flows in
5️⃣ System self-optimizes
…and the loop keeps compounding value. ♻️
🔑 Key insight: Data → Memory → Intelligence
Our pipeline “cognifies” every file into graphs, giving agents memory - just like a human mind. So let’s see how 👇🏼
First, why care about AI memory?
LLMs are brilliant—until they meet your fragmented data. They forget, hallucinate, or drown in silos. File-based AI memory bridges that gap, turning raw files into contextual intelligence. 📂🧠
Why file-based AI Memory will power next-gen AI apps?
We break down how a simple folder in the cloud becomes the semantic backbone for agents & copilots. Let’s unpack it 🧵👇

Woke up to 🚀 cognee hitting 5000 stars!
Thank you for the trust, feedback and code you pour in. Let’s keep building 🛠️

find us on @github.com trending!
05.06.2025 13:22 — 👍 3 🔁 2 💬 0 📌 0
Explore the research: arxiv.org/abs/2505.24478
Our GitHub: github.com/topoteretes/...

Taken together, the results support the use of hyperparameter optimization as a routine part of deploying retrieval-augmented QA systems. Gains are possible and sometimes substantial, but they are also dependent on task design, metric selection, and evaluation procedure.
03.06.2025 14:01 — 👍 2 🔁 0 💬 1 📌 0
We evaluate on three established multi-hop QA benchmarks: HotPotQA, TwoWikiMultiHop, and Musique. Each configuration is scored using one of three metrics: exact match (EM), token-level F1, or correctness.
03.06.2025 14:01 — 👍 0 🔁 0 💬 1 📌 0We present a structured study of hyperparameter
optimization in graph-based RAG systems, with a focus on tasks that combine unstructured inputs, knowledge graph construction, retrieval, and generation.
Building AI memory and data pipelines to populate them is tricky. The performance of these pipelines depends
heavily on a wide range of configuration choices, including chunk size, retriever type, top-k thresholds, and prompt templates.

Why does AI memory matter?
LLMs can’t give us details about our data, they "forget" or simply don’t know the details.

Yesterday, we released our paper, "Optimizing the Interface Between Knowledge Graphs and LLMs for Complex Reasoning"
We have developed a new tool to enable AI memory optimization that considerably improve AI memory accuracy for AI Apps and Agents. Let’s dive into the details of our work 📚
We're ramping up our r/AIMemory channel for broader discussions on AI Memory and to share in the conversation outside of cognee.
We'd love to see you share what you're working on, your thoughts and questions on AI memory, and any resources that would benefit the broader community.

Join the conversation at r/AIMemory. dub.sh/ai-memory
30.05.2025 14:29 — 👍 2 🔁 2 💬 0 📌 1
Full write-up → www.cognee.ai/blog/fundame...
If you’re exploring how to blend vectors and graphs for richer retrieval, we build exactly that at @cognee.bsky.social - DMs open for a chat!
@PGvector
If your need something cheap and a way to get started, pgvector is the key. If you need something to run in production with large volumes, well, maybe you will run into trouble there. Still, it will do a lot of heavy lifting for you
@redisinc.bsky.social Stack (vector search)
When latency budgets are measured in single-digit milliseconds, Redis’s in-memory design shines. Add the vector module, keep your other Redis data structures, and serve real-time recs or similarity lookups with room to spare.
@pinecone
Want vector search without touching infra? Pinecone’s managed service handles sharding, replication, and automatic scaling. Consistent sub-second queries plus usage-based pricing—great for teams that just need it to work.
@qdrant.bsky.social
Written in Rust for raw speed, Qdrant keeps latency low even on modest hardware. HNSW under the hood, solid filtering, and a tiny memory footprint—it’s a strong pick for edge or resource-constrained deployments.
@weaviate.bsky.social
Weaviate is the “batteries-included” option. Open-source, GraphQL API, and optional modules that auto-vectorize your data. Hybrid queries mix semantic + keyword filters out of the box, so you can start simple and grow.
@milvusio.bsky.social
Need to crunch billions of embeddings? Milvus is built for that. Distributed architecture, multiple index types (HNSW, IVF-PQ, DiskANN) and tunable consistency make it a go-to for large-scale analytics or “hot” user-facing search.


















