
MMLU-Redux Poster at NAACL 2025
MMLU-Redux just touched down at #NAACL2025! 🎉
Wish I could be there for our "Are We Done with MMLU?" poster today (9:00-10:30am in Hall 3, Poster Session 7), but visa drama said nope 😅
If anyone's swinging by, give our research some love! Hit me up if you check it out! 👋
02.05.2025 13:00 —
👍 17
🔁 11
💬 0
📌 0
Come say hi :)
11.04.2025 08:53 —
👍 1
🔁 0
💬 0
📌 0
I think as long as there are desirable job offers in academia and industry alike that hinge on X amount of papers published in "prestigious" venues, people continue to be incentivised to grind out more papers
18.01.2025 21:47 —
👍 3
🔁 0
💬 0
📌 0
Super cool, can't wait!
16.01.2025 09:53 —
👍 0
🔁 0
💬 0
📌 0
So jealous! Ever more reasons to apply to AllenAI... Can we get a sneak peek at what the tool is saying? 🙏
15.01.2025 21:20 —
👍 2
🔁 0
💬 1
📌 0
At least we can look at how often it occurs in OLMo's pre-training data, but what's a smart way to do so? Regex-ing the OLMo-mix for "protolithic" surely lands me in data jail...
15.01.2025 17:30 —
👍 0
🔁 0
💬 1
📌 0

Caught off-guard by the Llama 3.3 release? This is the loss of Llama-3.3-70B-Instruct (4bit quantized) on its own Twitter release thread. It really didn't like ' RL' (loss of 13.47) and wanted the text to instead go "... progress in online learning, which allows the model to adapt"
08.12.2024 22:33 —
👍 2
🔁 0
💬 0
📌 0
Thank you, that's very kind! Credit to the ROME authors for how cool the plots look, I'm using their public GitHub code. Just posted some results comparing to the base model too :)
03.12.2024 17:34 —
👍 1
🔁 0
💬 0
📌 0
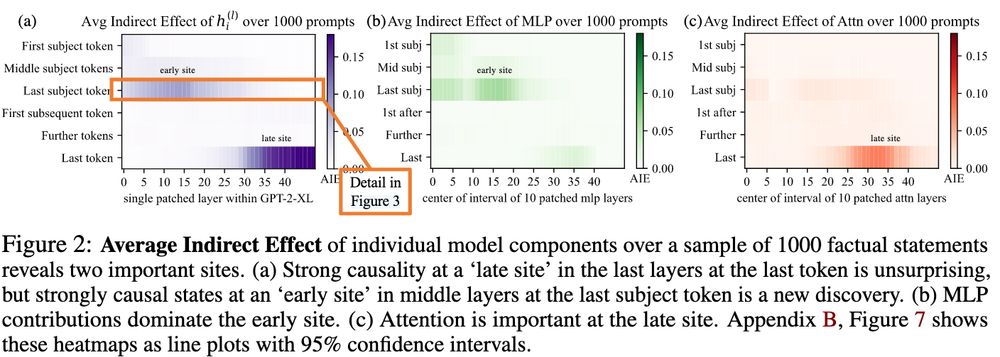
'late site' Attn results replicate somewhat, though this does not look as clean as their results on GPT-2-XL! There does seem to be non-negligible 'late site' MLP Indirect Effect for Llama 3.1 8B. I wonder how this affects their hypothesis? But keep in mind this is only for one Llama model! 3/3
03.12.2024 17:32 —
👍 1
🔁 0
💬 0
📌 0
is not in the model output, the prompt is skipped. In total, the default dataset from the ROME code contains 1209 prompts, so for the base model, only the result from ~15% of prompts make it to this graph, compared to ~71% for instruct. Again cool to see how Meng et al.'s 'early site' MLP vs. 2/3
03.12.2024 17:32 —
👍 1
🔁 0
💬 1
📌 0
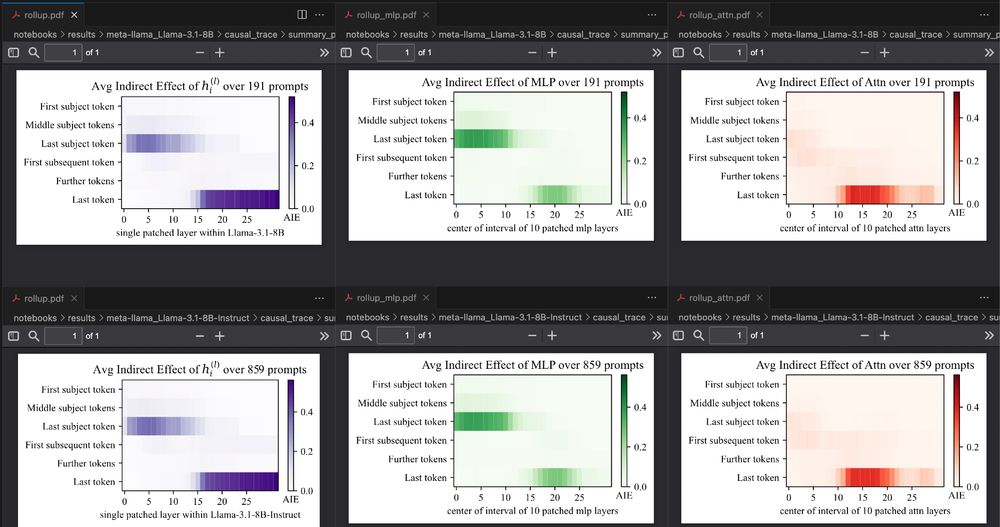
Do instruct models store factual associations differently than base models? 🤔 Doesn't look like it! When adapting ROME's causal tracing code to Llama 3.1 8B, the plots look very similar (base on top, instruct at the bottom). Note the larger sample size for instruct: If the "correct prediction" 1/3
03.12.2024 17:32 —
👍 3
🔁 0
💬 1
📌 0
I now also wish I knew about this much earlier! Ty for sharing
02.12.2024 14:57 —
👍 1
🔁 0
💬 0
📌 0
Awesome, thank you!! 🙏
01.12.2024 18:32 —
👍 1
🔁 0
💬 0
📌 0
Sounds good, looking forward!
01.12.2024 17:04 —
👍 0
🔁 0
💬 0
📌 0
Any chance I might be able to borrow it when you're done? :)
01.12.2024 10:51 —
👍 0
🔁 0
💬 1
📌 0
Hey Oliver, I'm a PhD student working on MechInterp. Was wondering if I could perhaps be added to the starter pack too? :)
01.12.2024 10:48 —
👍 1
🔁 0
💬 0
📌 0
Hey Julian! I'm a PhD student working on interpretability at the University of Edinburgh, was wondering if I could kindly ask to be added as well? 🙌
01.12.2024 10:44 —
👍 0
🔁 0
💬 1
📌 0
How do LLMs learn to reason from data? Are they ~retrieving the answers from parametric knowledge🦜? In our new preprint, we look at the pretraining data and find evidence against this:
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
20.11.2024 16:31 —
👍 854
🔁 138
💬 36
📌 24
From a technical standpoint this is clearly impressive, but it has a really eery quality to it. And the fact that it 'sang' the "(Fade out with improvised soul scatting)" instruction in the outro was a funny touch 😅
26.11.2024 15:46 —
👍 1
🔁 0
💬 0
📌 0

Hello to all #ICLR reviewers on #MLsky
25.11.2024 04:47 —
👍 27
🔁 4
💬 0
📌 2
Thank you :)
25.11.2024 08:58 —
👍 1
🔁 0
💬 0
📌 0
Hey @ramandutt4.bsky.social, any chance I could kindly ask you to add me too? 🙏
25.11.2024 08:26 —
👍 1
🔁 0
💬 1
📌 0
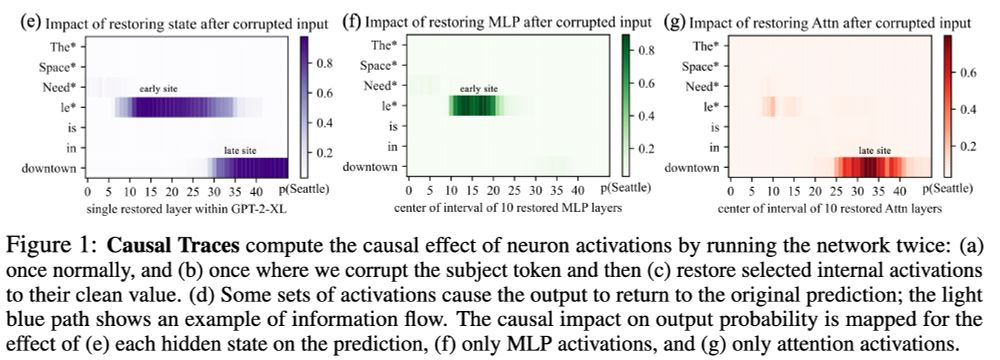
2/2 My hacky attempt at changing their codebase to accept Llama3.1 8B Instruct. Pretty cool that the 'early-site/late-site' findings replicate somewhat even on a single sample. Very curious for my sweep of the full 1209 samples from their paper to finish for more representative results :D
24.11.2024 23:21 —
👍 2
🔁 0
💬 1
📌 0
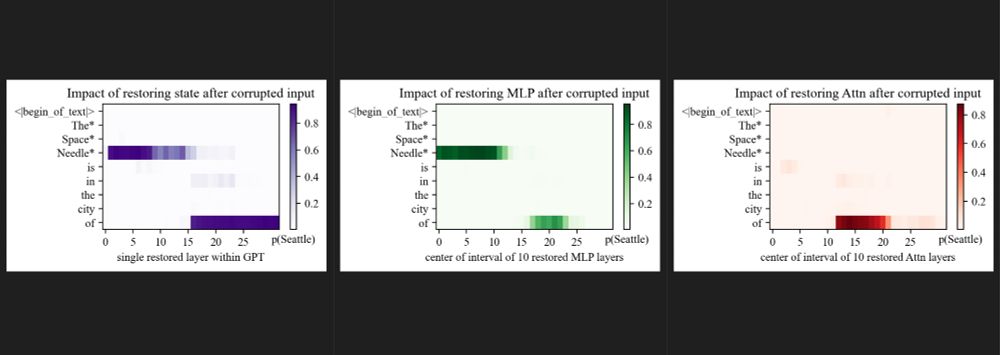
1/2 The original 2022 ROME paper by Meng et al.:
24.11.2024 23:15 —
👍 2
🔁 0
💬 1
📌 0
🙋♂️
24.11.2024 17:04 —
👍 0
🔁 0
💬 0
📌 0
