Check out our new work on getting more out of your Vision Transformers without fine-tuning by leveraging intermediate representations when probing!
We find that attentive probing is most robust for fusing across layers while showing exactly which layers matter for what task 👇
20.01.2026 13:44 —
👍 2
🔁 1
💬 0
📌 0
Check out our new work on getting more out of your Vision Transformers without fine-tuning by leveraging intermediate representations when probing!
We find that attentive probing is most robust for fusing across layers while showing exactly which layers matter for what task 👇
20.01.2026 13:44 —
👍 2
🔁 1
💬 0
📌 0
3/
Noise Hypernetworks: Amortizing Test-Time Compute in Diffusion Models
@lucaeyring.bsky.social , @shyamgopal.bsky.social , Alexey Dosovitskiy, @natanielruiz.bsky.social , @zeynepakata.bsky.social
[Paper]: arxiv.org/abs/2508.09968
[Code]: github.com/ExplainableM...
13.10.2025 14:43 —
👍 2
🔁 1
💬 2
📌 0

🎓PhD Spotlight: Karsten Roth
Celebrate @confusezius.bsky.social , who defended his PhD on June 24th summa cum laude!
🏁 His next stop: Google DeepMind in Zurich!
Join us in celebrating Karsten's achievements and wishing him the best for his future endeavors! 🥳
04.08.2025 14:11 —
👍 9
🔁 2
💬 1
📌 1
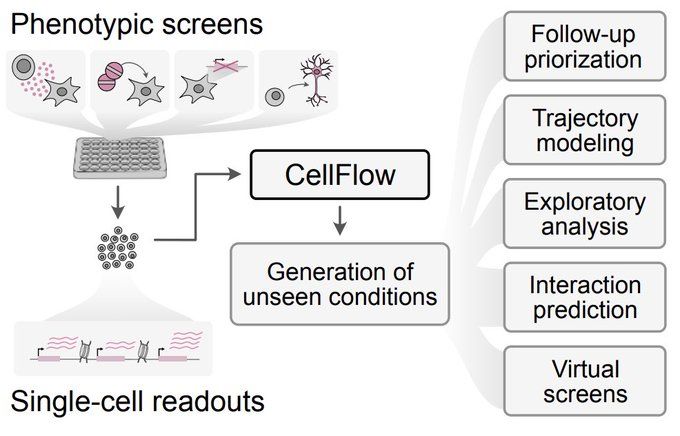
From cell lines to full embryos, drug treatments to genetic perturbations, neuron engineering to virtual organoid screens — odds are there’s something in it for you!
Built on flow matching, CellFlow can help guide your next phenotypic screen: biorxiv.org/content/10.1101/2025.04.11.648220v1
23.04.2025 09:26 —
👍 17
🔁 7
💬 1
📌 1
(4/4) Disentangled Representation Learning with the Gromov-Monge Gap
@lucaeyring.bsky.social will present GMG, a novel regularizer that matches prior distributions with minimal geometric distortion.
📍 Hall 3 + Hall 2B #603
🕘 Sat Apr 26, 10:00 a.m.–12:30 p.m.
22.04.2025 13:52 —
👍 4
🔁 1
💬 0
📌 0

Disentangled Representation Learning with the Gromov-Monge Gap
Learning disentangled representations from unlabelled data is a fundamental challenge in machine learning. Solving it may unlock other problems, such as generalization, interpretability, or fairness. ...
(3/4) Disentangled Representation Learning with the Gromov-Monge Gap
A fantastic work contributed by Theo Uscidda and @lucaeyring.bsky.social , with @confusezius.bsky.social , @fabiantheis.bsky.social , @zeynepakata.bsky.social , and Marco Cuturi.
📖 [Paper]: arxiv.org/abs/2407.07829
07.04.2025 09:34 —
👍 5
🔁 1
💬 1
📌 0
Happy to share that we have 4 papers to be presented in the coming #ICLR2025 in the beautiful city of #Singapore . Check out our website for more details: eml-munich.de/publications. We will introduce the talented authors with their papers very soon, stay tuned😉
19.03.2025 11:54 —
👍 7
🔁 4
💬 0
📌 0
Thrilled to announce that four papers from our group have been accepted to #CVPR2025 in Nashville! 🎉 Congrats to all authors & collaborators.
Our work spans multimodal pre-training, model merging, and more.
📄 Papers & codes: eml-munich.de#publications
See threads for highlights in each paper.
#CVPR
02.04.2025 11:36 —
👍 11
🔁 4
💬 1
📌 0
📄 Disentangled Representation Learning with the Gromov-Monge Gap
with Théo Uscidda, Luca Eyring, @confusezius.bsky.social, Fabian J Theis, Marco Cuturi
📄 Decoupling Angles and Strength in Low-rank Adaptation
with Massimo Bini, Leander Girrbach
24.01.2025 20:02 —
👍 10
🔁 2
💬 0
📌 0
Missing the deep learning part? go check out the follow up work @neuripsconf.bsky.social (tinyurl.com/yvf72kzf) and @iclr-conf.bsky.social (tinyurl.com/4vh8vuzk)
23.01.2025 08:45 —
👍 11
🔁 3
💬 0
📌 0
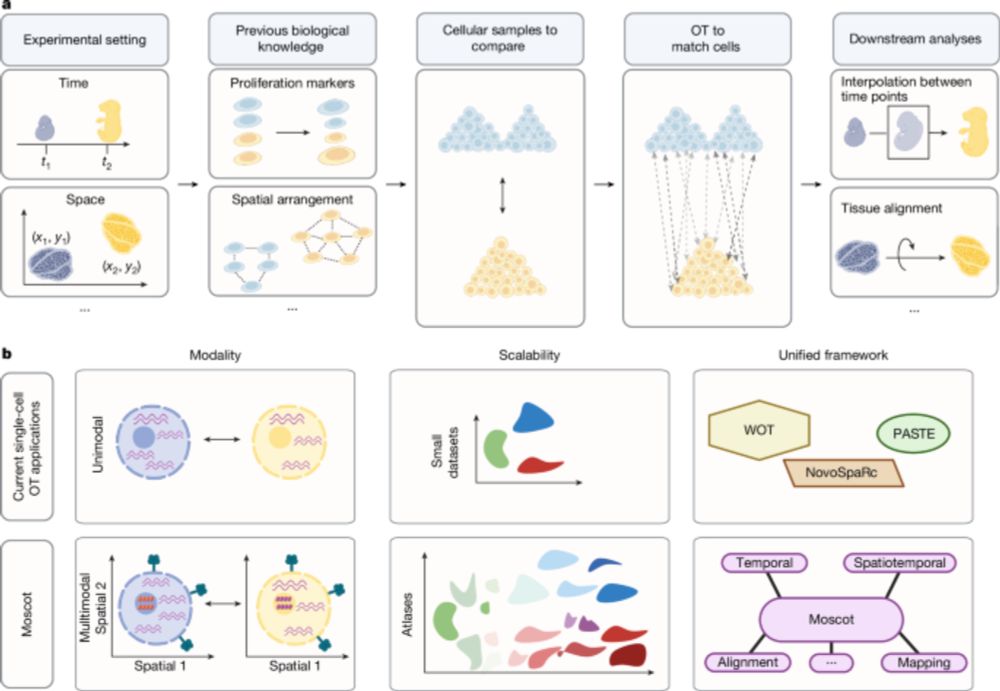
Mapping cells through time and space with moscot - Nature
Moscot is an optimal transport approach that overcomes current limitations of similar methods to enable multimodal, scalable and consistent single-cell analyses of datasets across spatial and temporal...
Good to see moscot-tools.org published in @nature.com ! We made existing Optimal Transport (OT) applications in single-cell genomics scalable and multimodal, added a novel spatiotemporal trajectory inference method and found exciting new biology in the pancreas! tinyurl.com/33zuwsep
23.01.2025 08:41 —
👍 49
🔁 13
💬 1
📌 3
Today is a great day for optimal transport 🎉! Lots of gratitude 🙏 for all folks who contributed to ott-jax.readthedocs.io and pushed for the MOSCOT (now @ nature!) paper, from visionaries @dominik1klein.bsky.social, G. Palla, Z. Piran to the magician, Michal Klein! ❤️
www.nature.com/articles/s41...
22.01.2025 22:17 —
👍 22
🔁 7
💬 0
📌 1
This is maybe my favorite thing I've seen out of #NeurIPS2024.
Head over to HuggingFace and play with this thing. It's quite extraordinary.
14.12.2024 19:32 —
👍 3
🔁 2
💬 0
📌 0
ReNO shows that some initial noise are better for some prompts! This is great to improve image generation, but i think it also shows a deeper property of diffusion models.
12.12.2024 11:23 —
👍 2
🔁 2
💬 1
📌 0

GitHub - ExplainableML/ReNO: [NeurIPS 2024] ReNO: Enhancing One-step Text-to-Image Models through Reward-based Noise Optimization
[NeurIPS 2024] ReNO: Enhancing One-step Text-to-Image Models through Reward-based Noise Optimization - ExplainableML/ReNO
This is joint work with @shyamgopal.bsky.social (co-lead), @confusezius.bsky.social, Alexey, and @zeynepakata.bsky.social.
To dive into all the details, please check out:
Code: github.com/ExplainableM...
Paper (updated with latest FLUX-Schnell + ReNO results): arxiv.org/abs/2406.043...
11.12.2024 23:05 —
👍 5
🔁 0
💬 0
📌 0

Even within the same computational budget, a ReNO-optimized one-step model outperforms popular multi-step models such as SDXL and PixArt-α. Additionally, our strongest model, ReNO-enhanced HyperSDXL, is on par even with SOTA proprietary models, achieving a win rate of 54% vs SD3.
11.12.2024 23:05 —
👍 3
🔁 0
💬 1
📌 0

ReNO optimizes the initial noise in one-step T2I models at inference based on human preference reward models. We show that ReNO achieves significant improvements over five different one-step models quantitatively on common benchmarks and using comprehensive user studies.
11.12.2024 23:05 —
👍 3
🔁 0
💬 1
📌 0
Thanks to @fffiloni.bsky.social and @natanielruiz.bsky.social, we have a running live Demo of ReNO, play around with it here:
🤗: huggingface.co/spaces/fffil...
We are excited to present ReNO at #NeurIPS2024 this week!
Join us tomorrow from 11am-2pm at East Exhibit Hall A-C #1504!
11.12.2024 23:05 —
👍 4
🔁 0
💬 1
📌 1

Can we enhance the performance of T2I models without any fine-tuning?
We show that with our ReNO, Reward-based Noise Optimization, one-step models consistently surpass the performance of all current open-source Text-to-Image models within the computational budget of 20-50 sec!
#NeurIPS2024
11.12.2024 23:05 —
👍 27
🔁 7
💬 1
📌 1

After a break of over 2 years, I'm attending a conference again! Excited to attend NeurIPS, even more so to be presenting ReNO, getting inference-time scaling and preference optimization to work for text-to-image generation.
Do reach out if you'd like to chat!
09.12.2024 21:27 —
👍 12
🔁 3
💬 0
📌 0


