that's all the code you need to run detection and tracking
"how to track objects with SORT tracker" notebook: colab.research.google.com/github/robof...

@skalskip92.bsky.social
Open-source Lead @roboflow. VLMs. GPU poor. Dog person. Coffee addict. Dyslexic. | GH: https://github.com/SkalskiP | HF: https://huggingface.co/SkalskiP
that's all the code you need to run detection and tracking
"how to track objects with SORT tracker" notebook: colab.research.google.com/github/robof...
it's build on top of supervision package allowing you to take advantage of all the tools we already created
25.04.2025 13:03 — 👍 2 🔁 0 💬 1 📌 0trackers v2.0.0 is out
combo object detectors from top model libraries with multi-object tracker of your choice
for now we support SORT and DeepSORT; more trackers coming soon
link: github.com/roboflow/tra...
object detection example project: bsky.app/profile/skal...
11.12.2024 16:58 — 👍 2 🔁 0 💬 0 📌 0image to JSON example project: bsky.app/profile/skal...
11.12.2024 16:58 — 👍 2 🔁 0 💬 1 📌 0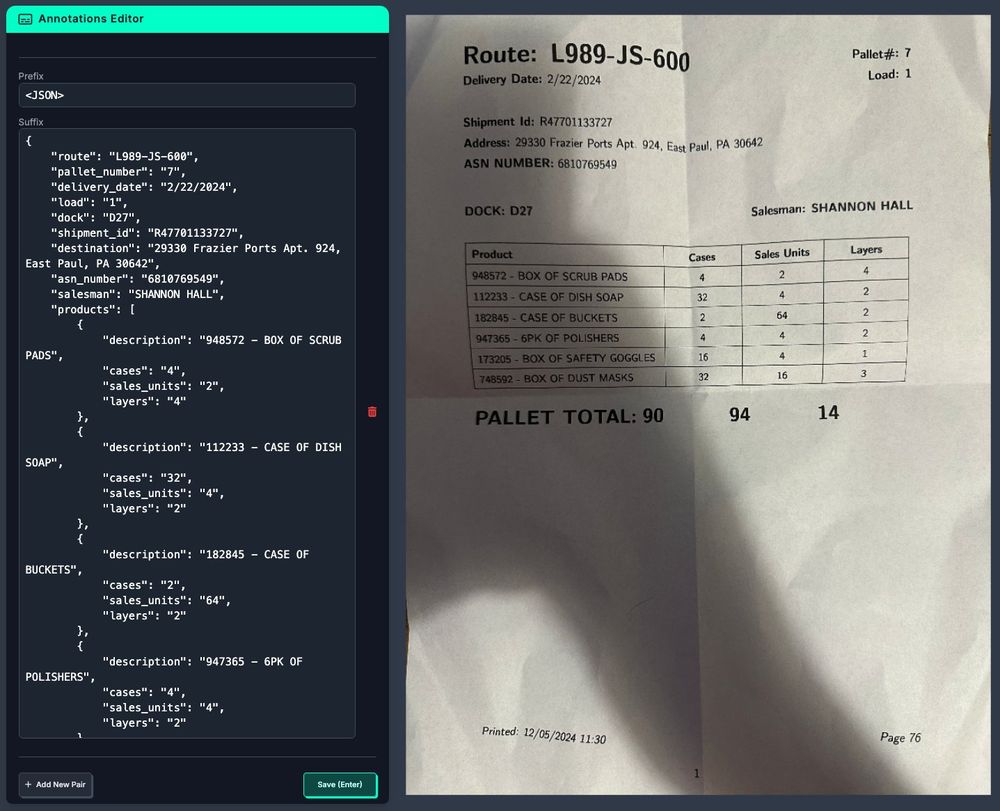
you need to prepare your dataset in JSONL format; dataset includes three subsets: train, test, and valid
each subset contains images and annotations.jsonl file where each line of the file is a valid JSON object; each JSON object has three keys: image, prefix, and suffix

to limit the memory (VRAM) usage during the training, we can use LoRA, QLoRA, or freeze parts of the graph
11.12.2024 16:58 — 👍 1 🔁 0 💬 1 📌 0fine-tuning large vision-language models like PaliGemma 2 can be resource-intensive. to put this into perspective, the largest variant of the recent YOLOv11 object detection model (YOLOv11x) has 56.9M parameters. in contrast, PaliGemma 2 models range from 3B to 28B parameters.
11.12.2024 16:58 — 👍 1 🔁 0 💬 1 📌 0

PG2 offers 9 pre-trained models with sizes of 3B, 10B, and 28B parameters and resolutions of 224, 448, and 896 pixels.
to pick the right variant, you need to take into account the vision-language task you are solving, available hardware, amount of data, inference speed

PG2 combines a SigLIP-So400m vision encoder with a Gemma 2 language model to process images and text. these tokens are then linearly projected and combined with input text tokens. Gemma 2 language model processes these combined tokens and generates output text tokens.
11.12.2024 16:58 — 👍 1 🔁 0 💬 1 📌 0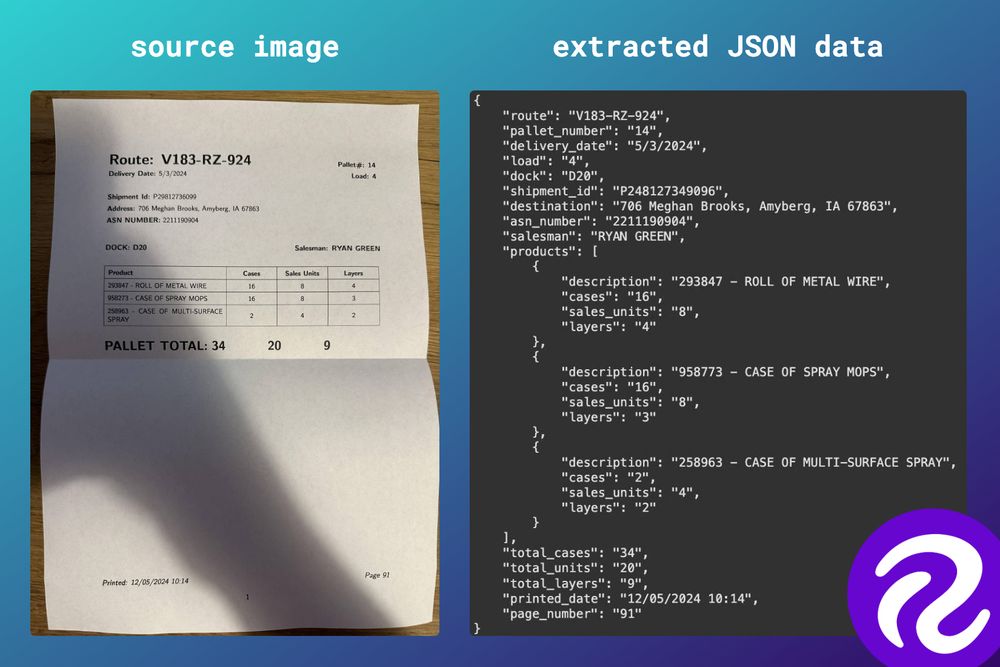
new blog post is out: how to fine-tune PaliGemma 2
all I learned in a single blog
- PaliGemma 2 architecture
- dataset annotation and structure
- picking the right checkpoint
- memory optimization
- hyperparameters tuning
link: blog.roboflow.com/fine-tune-pa...

the paper suggests some nice strategies to increase the model's detection accuracy using fake boxes and <noise> special token; I plan to explore those in the coming days.
08.12.2024 16:26 — 👍 1 🔁 0 💬 0 📌 0
PG2 offers 9 pre-trained models with sizes of 3B, 10B, and 28B parameters and resolutions of 224, 448, and 896 pixels.
we can see that PaliGemma2's object detection performance depends more on input resolution than model size. 3B 448 seems like a sweet spot.

PG2 performs worse on the object detection task than specialized detectors; you can easily train a YOLOv11 model with 0.9 mAP on this dataset.
compared to PG1, it performs much better; datasets with a large number of classes were hard to fine-tune with previous version


PaliGemma2 for object detection on custom dataset
- used google/paligemma2-3b-pt-448 checkpoint
- trained on A100 with 40GB VRAM
- 1h of training
- 0.62 mAP on the validation set
colab with complete fine-tuning code: colab.research.google.com/github/robof...
also take into account that Gemini and Gemma are 2 different models; Gemma is a lot smaller, open-source and can run locally
08.12.2024 15:03 — 👍 1 🔁 0 💬 0 📌 0totally agree; it's not perfect! but
- there are still a lot bigger versions of the model, both in terms of parameters and input resolution
- I only trained it for 1 hour

a multimodal dataset I used to fine-tune the model.
link: universe.roboflow.com/roboflow-jvu...

PG2 offers 9 pre-trained models with sizes of 3B, 10B, and 28B parameters and resolutions of 224, 448, and 896 pixels.
it looks like OCR-related metrics ST-VQA, TallyQA, and TextCaps... benefit more from increased resolution than model size. that's why I went from 224 to 336.

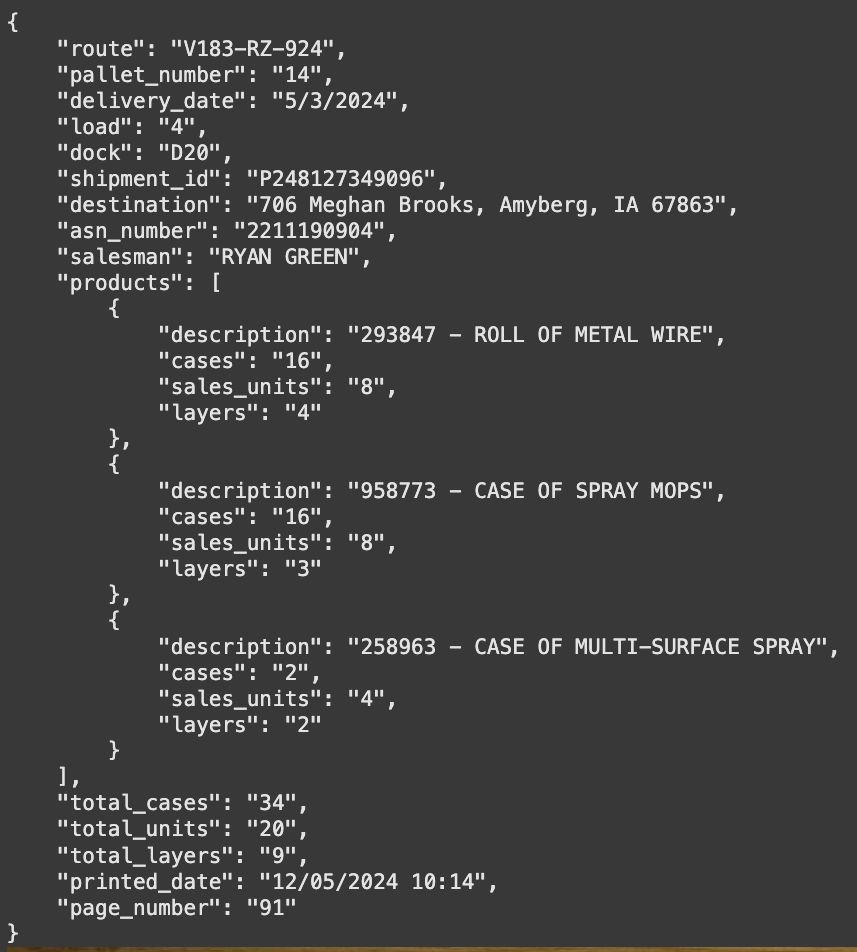
PaliGemma2 for image to JSON data extraction
- used google/paligemma2-3b-pt-336 checkpoint; I tried to make it happen with 224, but 336 performed a lot better
- trained on A100 with 40GB VRAM
- trained with LoRA
colab with complete fine-tuning code: colab.research.google.com/github/robof...

how to prevent this in open-source projects?
- never allow github actions from first-time contributors.
- always require review for new contributors.
- never run important actions automatically via bots.
- protect release actions with unique cases and selected actors.

what happened?
malicious code was injected into the pypi deployment workflow (github action).
the source code itself wasn't infected. however, the resulting tar/wheel files were corrupted during the build process.
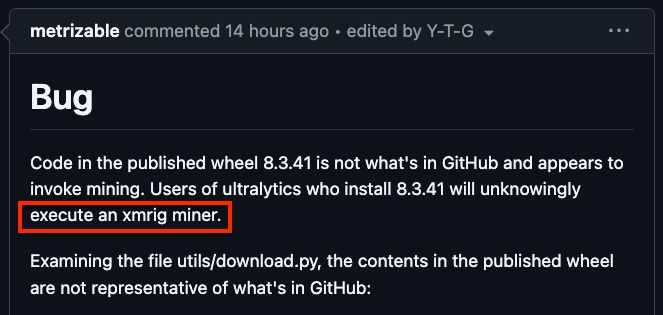
popular computer vision package ultralytics (home of yolov8 and yolo11) was compromised.
a crypto miner was injected into versions 8.3.41 and 8.3.42.
link: github.com/ultralytics/...
smart parking systems are just the beginning. roboflow workflows can be used for so much more. check out my clothes detection + sam2 + stabilityai inpainting workflow
27.11.2024 17:43 — 👍 3 🔁 0 💬 0 📌 0
custom python blocks in roboflow workflows are powerful. built a telegram bot connector for real-time alerts.
27.11.2024 17:43 — 👍 2 🔁 0 💬 1 📌 02 years ago i made a whole tutorial on coding this from scratch. now it's just 2 clicks in workflows.
link to my original line counting tutorial: www.youtube.com/watch?v=OS5q...

I regret using OpenAI for license plate OCR.
expensive, slow, censors results, and refuses to read plates 20-30% of the time.
open-source models like florence2 are more reliable.
built a smart parking system with roboflow workflows.
- license plate detection and ocr
- object tracking with bytetrack.
- counting cars entering and leaving the lot.
- real-time alerts via telegram.