
What’s the right resolution for such ontologies? 1,000-10,000 seems like the sweet spot.
H/t @aneeshsathe.com
aneeshsathe.com/2025/01/15/d...

@gowthami.bsky.social
PhD-ing at UMD. Knows a little about multimodal generative models. Check out my website to know more - https://somepago.github.io/
What’s the right resolution for such ontologies? 1,000-10,000 seems like the sweet spot.
H/t @aneeshsathe.com
aneeshsathe.com/2025/01/15/d...
About to send my last DLCT email of the year today (in 2 hours).
Join the 7-year-old mailing list if you haven't heard of it. (And if you have heard of it but haven't joined, I trust that it's a well thought decision that suits you the best.)
groups.google.com/g/deep-learn...
The recording of my #NeurIPS2024 workshop talk on multimodal iterative refinement is now available to everyone who registered: neurips.cc/virtual/2024...
My talk starts at 1:10:45 into the recording.
I believe this will be made publicly available eventually, but I'm not sure when exactly!
![[M2L 2024] Transformers - Lucas Beyer](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:5pnsngbdz5udoytu3lylog7z/bafkreid5njn432psqkaccemu426qa4qcnig4gaet2s55htw4gsdozhbccy@jpeg)
One of the best tutorials for understanding Transformers!
📽️ Watch here: www.youtube.com/watch?v=bMXq...
Big thanks to @giffmana.ai for this excellent content! 🙌
Anne Gagneux, Ségolène Martin, @quentinbertrand.bsky.social Remi Emonet and I wrote a tutorial blog post on flow matching: dl.heeere.com/conditional-... with lots of illustrations and intuition!
We got this idea after their cool work on improving Plug and Play with FM: arxiv.org/abs/2410.02423
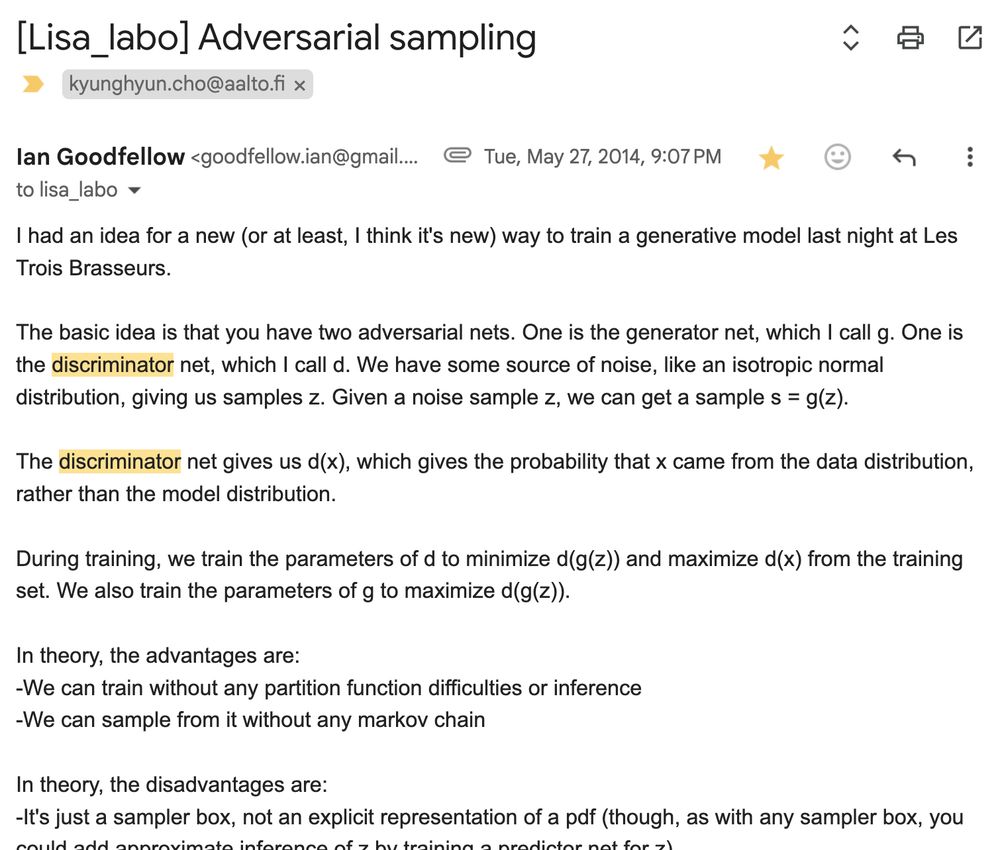


congratulations, @ian-goodfellow.bsky.social, for the test-of-time award at @neuripsconf.bsky.social!
this award reminds me of how GAN started with this one email ian sent to the Mila (then Lisa) lab mailing list in May 2014. super insightful and amazing execution!
Maybe I’m cynical 🙈, this feels more like a KPI meeting activity than something that’s actually useful. There are 1000s of open datasets on HF which are barely used which are curated with a task in mind.
27.11.2024 01:01 — 👍 5 🔁 0 💬 0 📌 0Trying to build a "books you must read" list for my lab that everyone gets when they enter. Right now its:
- Sutton and Barto
- The Structure of Scientific Revolutions
- Strunk and White
- Maybe "Prediction, Learning, and Games", TBD
Kinda curious what's missing in an RL / science curriculum

This is a simple and good paper, which somehow nobody working on these things cites, or even seems to be aware of arxiv.org/abs/2406.05213 It is simple idea that seems useful; it formulates the subjective uncertainty for natural language generation in a decision-theoretic setup.
25.11.2024 02:16 — 👍 27 🔁 3 💬 2 📌 1

A real-time (or very fast) open-source txt2video model dropped: LTXV.
HF: huggingface.co/Lightricks/L...
Gradio: huggingface.co/spaces/Light...
Github: github.com/Lightricks/L...
Look at that prompt example though. Need to be a proper writer to get that quality.

1. Computing standard errors of the mean using the Central Limit Theorem 2. When questions are drawn in related groups, computing clustered standard errors 3. Reducing variance by resampling answers and by analyzing next-token probabilities 4. When two models are being compared, conducting statistical inference on the questionlevel paired differences, rather than the population-level summary statistics 5. Using power analysis to determine whether an eval (or a random subsample) is capable of testing a hypothesis of interest
Perhaps an unpopular opinion, but I don't think the problem with Large Language Model evaluations is the lack of error bars.
22.11.2024 14:25 — 👍 110 🔁 5 💬 9 📌 2
let me say it once more: "the gap between OAI/Anthropic/Meta/etc. and a large group of companies all over the world you've never cared to know of, in terms of LM pre-training? tiny"
22.11.2024 15:29 — 👍 77 🔁 8 💬 12 📌 1👋
22.11.2024 19:02 — 👍 1 🔁 0 💬 0 📌 0

The return of the Autoregressive Image Model: AIMv2 now going multimodal.
Excellent work by @alaaelnouby.bsky.social & team with code and checkpoints already up:
arxiv.org/abs/2411.14402

Interesting paper on arxiv this morning: arxiv.org/abs/2411.13683
It's a video masked autoencoder in which you learn which tokens to mask to process fewer of them and scale to longer videos. It's a #NeurIPS2024 apparently.
I wonder if there could be such strategy in the pure generative setup.
Very true. Completely forgot about this. However I don’t believe this model is a true reflection of VLMs trained from scratch are capable of though… or maybe my hypothesis is wrong. 🤷♀️
22.11.2024 07:22 — 👍 0 🔁 0 💬 0 📌 0💯 ! Haven’t seen a single VLM where everything is trained from scratch
22.11.2024 06:01 — 👍 0 🔁 0 💬 3 📌 0I have the same thing on, and it’s giving me follow notifications but not comments (which is very stupid! 🥲)
22.11.2024 05:58 — 👍 1 🔁 0 💬 0 📌 0I’m not getting notifications for comments here, anyone facing the same issue?
22.11.2024 03:19 — 👍 0 🔁 0 💬 1 📌 0@kampta.bsky.social is a relevant add.
21.11.2024 21:34 — 👍 0 🔁 0 💬 0 📌 0
Discrete diffusion has become a very hot topic again this year. Dozens of interesting ICLR submissions and some exciting attempts at scaling. Here's a bibliography on the topic from the Kuleshov group (my open office neighbors).
github.com/kuleshov-gro...
Ofcourse! :)
21.11.2024 20:25 — 👍 1 🔁 0 💬 0 📌 0Added you.
21.11.2024 18:14 — 👍 0 🔁 0 💬 0 📌 0Added you!
21.11.2024 18:14 — 👍 0 🔁 0 💬 0 📌 0Added!
21.11.2024 18:13 — 👍 1 🔁 0 💬 1 📌 0Done!
21.11.2024 18:13 — 👍 1 🔁 0 💬 0 📌 0Added!
21.11.2024 18:13 — 👍 1 🔁 0 💬 1 📌 0I only got to know today this awesome diffusion starter pack exists! I’ll try to fill up my generative models pack with some complementary folks. :)
21.11.2024 18:10 — 👍 6 🔁 0 💬 0 📌 0Can people create accounts here without invite now? 🤔
21.11.2024 07:56 — 👍 5 🔁 0 💬 5 📌 0




















