
TAO: Using test-time compute to train efficient LLMs without labeled data
LIFT fine-tunes LLMs without labels using reinforcement learning, boosting performance on enterprise tasks.
The hardest part about finetuning is that people don't have labeled data. Today, @databricks.bsky.social introduced TAO, a new finetuning method that only needs inputs, no labels necessary. Best of all, it actually beats supervised finetuning on labeled data. www.databricks.com/blog/tao-usi...
25.03.2025 17:19 — 👍 35 🔁 6 💬 0 📌 2
Two years ago at Mosaic we had an idea for an "RLXF as a service"
One year and an acquisition later, the prototypes went into preview at Databricks
Today we share some results and findings of "what does it take to actually do enterprise RL and put it into a real product"
25.03.2025 20:05 — 👍 14 🔁 4 💬 1 📌 0
Profiling code and hunting for 10x latency gains is pure joy 👨🏻💻
05.03.2025 04:39 — 👍 0 🔁 0 💬 0 📌 0
Nevertheless, the team has developed an exceptional inference system and commendably shared their expertise with the community. Kudos to them!
02.03.2025 06:25 — 👍 0 🔁 0 💬 0 📌 0
DeepSeek's inference system overview is truly impressive. However, we should not overinterpret its eye popping profit margin. The key takeaway is that with high traffic volumes, you can create extremely large batch sizes to maximize GPU utilization. The reported 545% profit margin comes with caveats
02.03.2025 06:25 — 👍 1 🔁 0 💬 1 📌 0
New open source OCR VLM!
26.02.2025 00:56 — 👍 2 🔁 0 💬 0 📌 0
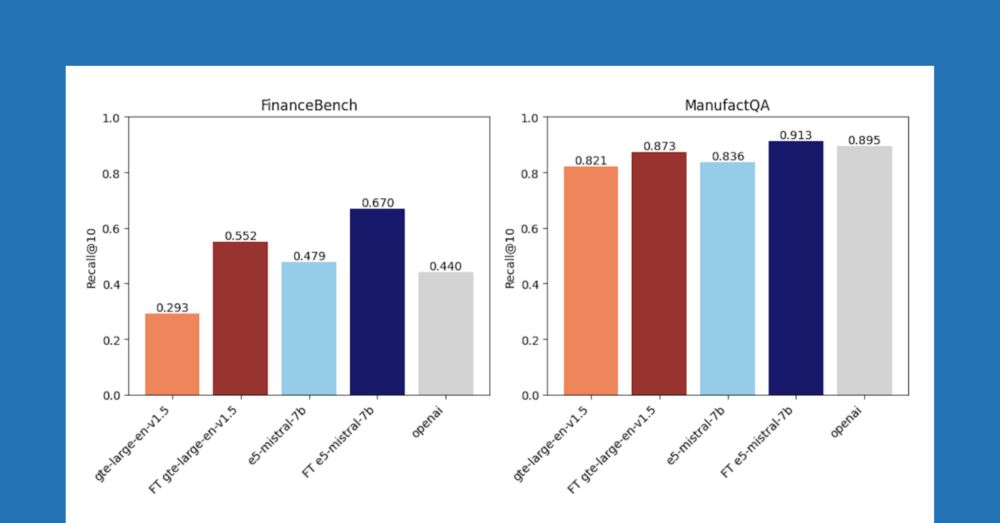
Improving Retrieval and RAG with Embedding Model Finetuning
Fine-tune embedding models on Databricks to enhance retrieval and RAG accuracy with synthetic data—no manual labeling required.
We're probably a little too obsessed with zero-shot retrieval. If you have documents (you do), then you can generate synthetic data, and finetune your embedding. Blog post lead by @jacobianneuro.bsky.social shows how well this works in practice.
www.databricks.com/blog/improvi...
26.02.2025 00:48 — 👍 9 🔁 5 💬 1 📌 0
Making LLMs run efficiently can feel scary, but scaling isn’t magic, it’s math! We wanted to demystify the “systems view” of LLMs and wrote a little textbook called “How To Scale Your Model” which we’re releasing today. 1/n
04.02.2025 18:54 — 👍 95 🔁 28 💬 3 📌 8
It's remarkable to see the brightest minds and top talents from the US, China, and numerous other countries are all working to push AI's frontiers—advancing reasoning, efficiency, applications, etc.
While competition certainly exists, I'm finding more collaborative spirit in this coopetition state.
28.01.2025 00:23 — 👍 0 🔁 0 💬 0 📌 0
Qwen 2.5 VL seems to have great emphasis on document image analysis -- layout detection, special html output format, localization of objects -- and the performance on docvqa seems to be very strong.
27.01.2025 23:57 — 👍 0 🔁 0 💬 0 📌 0
Qwen2.5-1M: Deploy Your Own Qwen with Context Length up to 1M Tokens
Very significant new release from Alibaba's Qwen team. Their openly licensed (sometimes Apache 2, sometimes Qwen license, I've had trouble keeping up) Qwen 2.5 LLM previously had an input token …
Alibaba's Qwen group just shipped Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M - two Apache 2 licensed LLMs with an impressive 1 million token context limit!
Here are my notes, including my so-far unsuccessful attempts to run large context prompts on my Mac simonwillison.net/2025/Jan/26/...
26.01.2025 18:56 — 👍 102 🔁 8 💬 5 📌 0
I don’t care when “AGI” arrives I’m just out here having a good time with AI anyways.
21.01.2025 16:15 — 👍 18 🔁 3 💬 2 📌 0
The Basics of Reinforcement Learning from Human Feedback
The Basics of Reinforcement Learning from Human Feedback
I was reading @natolambert.bsky.social's RLHF book when I came across an unexpected chapter about his experience working with data labeling vendors: rlhfbook.com/c/06-prefere...). He shared several realistic, frustrating stories and data points. I strongly resonated with his experiences.
08.12.2024 01:46 — 👍 1 🔁 0 💬 1 📌 0
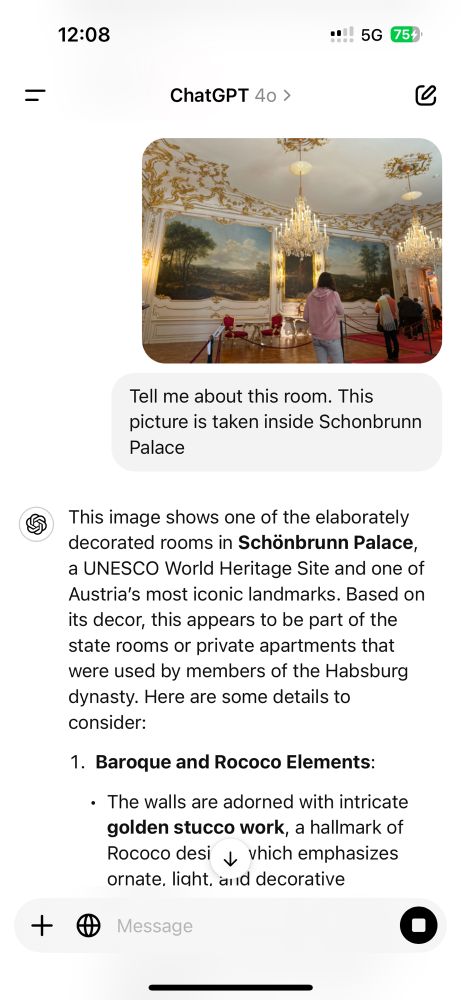

The vision capability enriches interactions with the real world. The experience is quite delightful when it works.
21.11.2024 11:14 — 👍 0 🔁 0 💬 0 📌 0
Assist. Prof at CMU, CS PhD at UW. HCI+AI, map general-purpose models to specific use cases!
PhD Student @ UC Berkeley working on computational imaging.
lakabuli.github.io
cs phd student @ UC Berkeley
Build and share machine learning apps in 3 lines of Python. Part of the
@Huggingface family 🤗.
DMs are open for sharing your gradio app with us!
research scientist at google deepmind.
co-author of JAX (https://github.com/jax-ml/jax).
https://cs.stanford.edu/~rfrostig
Researcher at Google DeepMind. I make LLMs go fast. I also play piano and climb sometimes. Opinions my own
PhD @ MIT. Prev: Google Deepmind, Apple, Stanford. 🇨🇦 Interests: AI/ML/NLP, Data-centric AI, transparency & societal impact
RL + LLM @ai2.bsky.social; main dev of https://cleanrl.dev/
I (try to) do NLP research. Antipodean abroad.
currently doing PhD @uwcse,
prev @usyd @ai2
🇦🇺🇨🇦🇬🇧
ivison.id.au
#NLP research @ai2.bsky.social; OLMo post-training
https://pdasigi.github.io/
PhD student @uwnlp, student researcher @allen_ai. NLP/ML.
Researcher in NLP, ML, computer music. Prof @uwcse @uwnlp & helper @allen_ai @ai2_allennlp & familiar to two cats. Single reeds, tango, swim, run, cocktails, מאַמע־לשון, GenX. Opinions not your business.
Research Scientist at Ai2, PhD in NLP 🤖 UofA. Ex
GoogleDeepMind, MSFTResearch, MilaQuebec
https://nouhadziri.github.io/
Assistant Professor of CS & DS at NYU. Machine Learning, Human-like AI, Continual Learning | Head of @agentic-ai-lab.bsky.social
mengyeren.com
Writer http://jalammar.github.io. O'Reilly Author http://LLM-book.com. LLM Builder Cohere.com.
AI, RL, NLP, Games Asst Prof at UCSD
Research Scientist at Nvidia
Lab: http://pearls.ucsd.edu
Personal: prithvirajva.com
i write code sometimes and sometimes alot :')
hot takes, linear Algebra, JAX apologist, Raconteur





























