
We introduce MIRO: a new paradigm for T2I model alignment integrating reward conditioning into pretraining, eliminating the need for separate fine-tuning/RL stages. This single-stage approach offers unprecedented efficiency and control.
- 19x faster convergence ⚡
- 370x less FLOPS than FLUX-dev 📉
31.10.2025 11:24 — 👍 60 🔁 14 💬 3 📌 5
Super interesting to see pure SSL outperforms text alignement on a super competitive but text-aligned suited task 🤯
18.08.2025 15:44 — 👍 2 🔁 0 💬 0 📌 0
🛰️ At #CVPR2025 presenting "AnySat: An Earth Observation Model for Any Resolutions, Scales, and Modalities" - Saturday afternoon, Poster 355!
If you're here and want to discuss geolocation or geospatial foundation models, let's connect!
11.06.2025 21:08 — 👍 13 🔁 3 💬 0 📌 0

I will be presenting our work on the detection of archaeological looting with satellite image time series at CVPR 2025 EarthVision workshop tomorrow!
Honored and grateful that this paper received the best student paper award!
11.06.2025 04:03 — 👍 15 🔁 6 💬 1 📌 0
We've added new experiments demonstrating robust generalization capabilities! Notably, AnySat shows strong performance on HLS Burn Scars - a sensor never seen during pretraining! 🔥🛰️
Check it out:
📄 Paper: arxiv.org/abs/2412.14123
🌐 Project: gastruc.github.io/anysat
30.04.2025 14:00 — 👍 9 🔁 3 💬 0 📌 0
Looking forward to #CVPR2025! We will present the following papers:
30.04.2025 13:04 — 👍 28 🔁 7 💬 1 📌 1


🔥🔥🔥 CV Folks, I have some news! We're organizing a 1-day meeting in center Paris on June 6th before CVPR called CVPR@Paris (similar as NeurIPS@Paris) 🥐🍾🥖🍷
Registration is open (it's free) with priority given to authors of accepted papers: cvprinparis.github.io/CVPR2025InPa...
Big 🧵👇 with details!
21.03.2025 06:43 — 👍 136 🔁 51 💬 7 📌 10
Starter pack including some of the lab members: go.bsky.app/QK8j87w
14.03.2025 10:34 — 👍 24 🔁 11 💬 0 📌 1

🧩 Excited to share our paper "RUBIK: A Structured Benchmark for Image Matching across Geometric Challenges" (arxiv.org/abs/2502.19955) accepted to #CVPR2025! We created a benchmark that systematically evaluates image matching methods across well-defined geometric difficulty levels. 🔍
28.02.2025 15:23 — 👍 19 🔁 7 💬 2 📌 0
Weights for CAD are finally available. It's one of the smallest diffusion models on the market, achieving performance close to SD and Pixart, featuring a Perceiver-like architecture.
We leverage our coherence aware training to improve the textual understanding
20.02.2025 12:14 — 👍 11 🔁 3 💬 0 📌 0
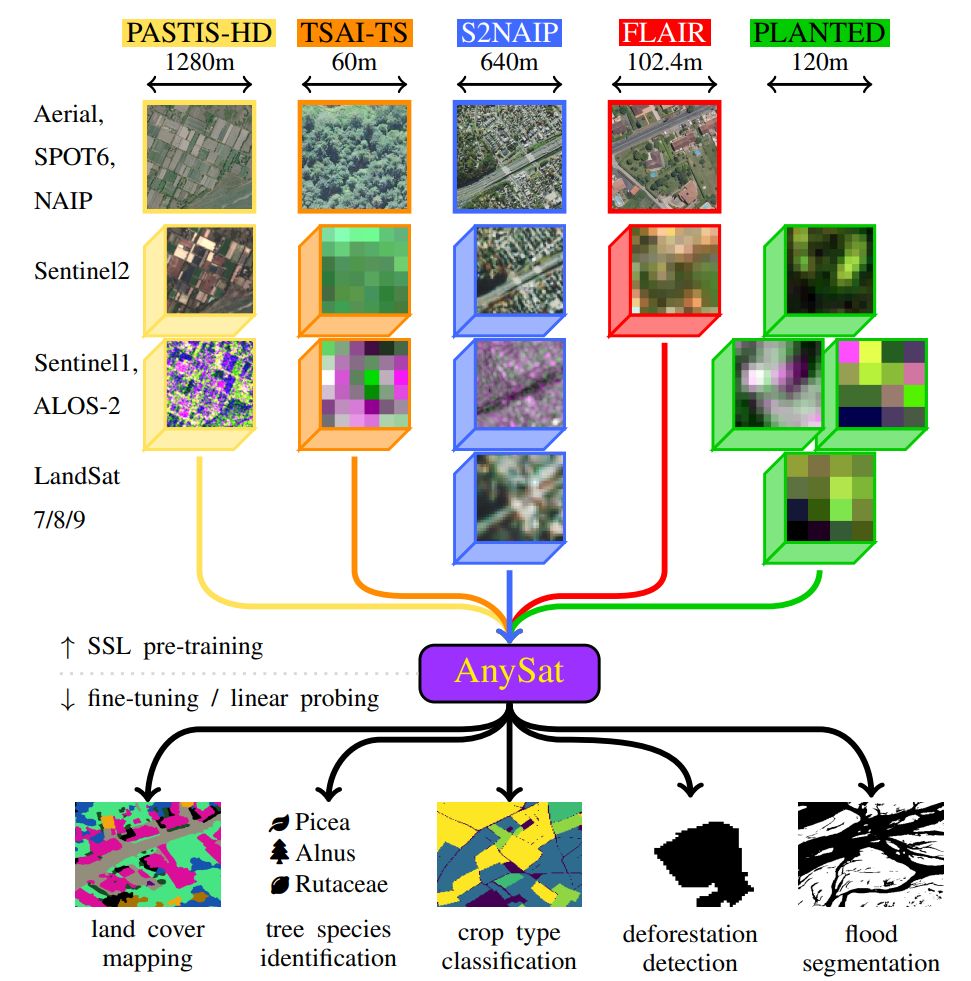
🔗 Check it out:
📜 Paper: arxiv.org/abs/2412.14123
🌐 Project: gastruc.github.io/anysat
🤗 HuggingFace: huggingface.co/g-astruc/Any...
🐙 GitHub: github.com/gastruc/AnySat
19.12.2024 10:46 — 👍 5 🔁 0 💬 0 📌 0

🚀 Even better: AnySat supports linear probing for semantic segmentation!
That means you can fine-tune just a few thousand parameters and achieve SOTA results on challenging tasks—all with minimal effort.
19.12.2024 10:46 — 👍 3 🔁 0 💬 1 📌 0
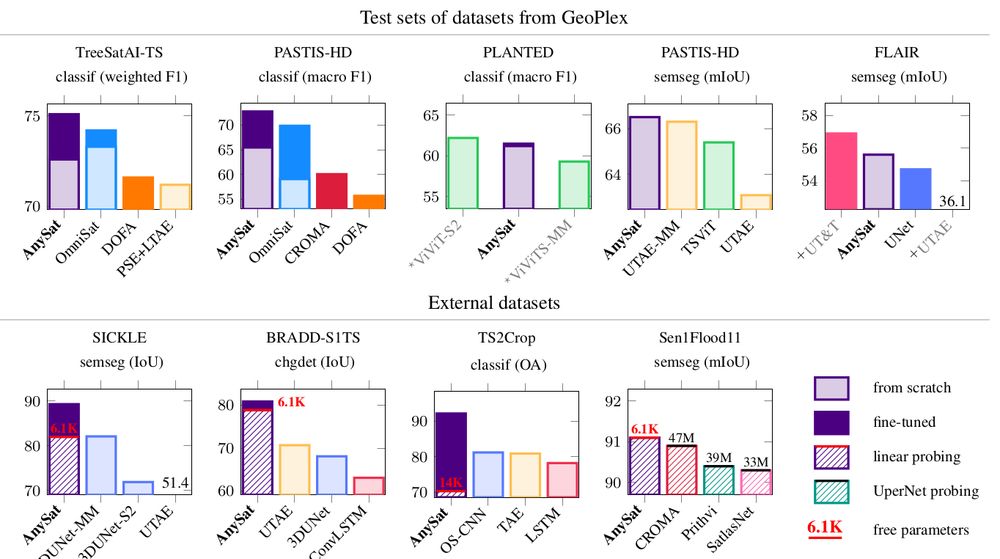
AnySat achieves SOTA performance on 6 tasks across 10 datasets:
🌱 Land cover mapping
🌾 Crop type segmentation
🌳 Tree species classification
🌊 Flood detection
🌍 Change detection
19.12.2024 10:46 — 👍 2 🔁 0 💬 1 📌 0
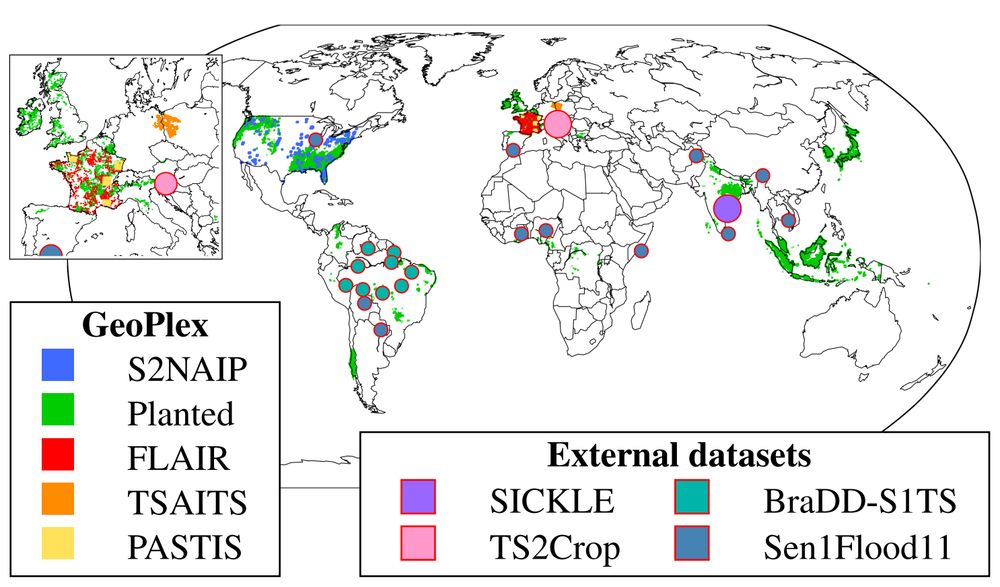
We trained AnySat on 5 multimodal datasets simultaneously:
📡 11 distinct sensors
📏 Resolutions: 0.2m–500m
🔁 Revisit: single date to weekly
🏞️ Scales: 0.3–150 hectares
The pretrained model can adapt to truly diverse data, and probably yours too!
19.12.2024 10:46 — 👍 2 🔁 0 💬 1 📌 0
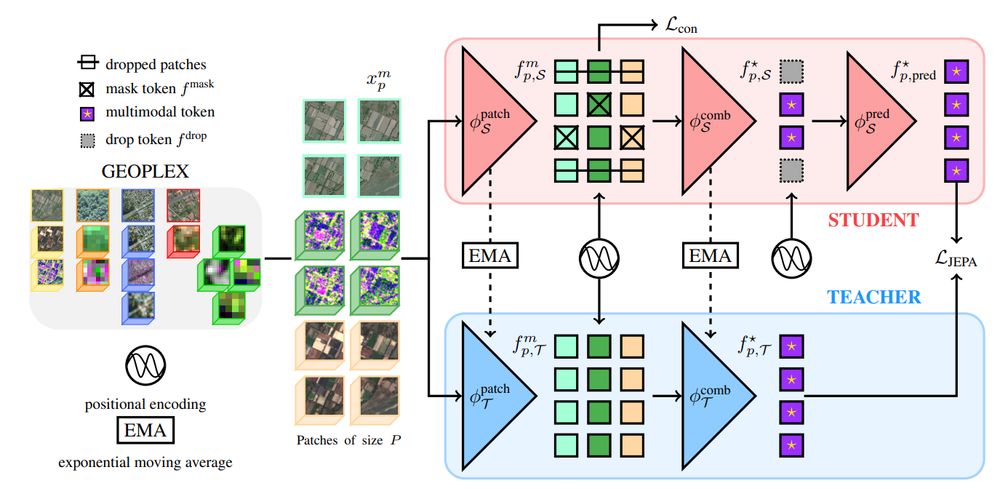
🔍Thanks to our modified JEPA training scheme and scale-adaptive spatial encoders, AnySat trains on datasets with diverse scales, resolutions, and modalities!
🧠 75% of its parameters are shared across all inputs, enabling unmatched flexibility.
19.12.2024 10:46 — 👍 3 🔁 0 💬 1 📌 0

🤔 What if embedding multimodal EO data was as easy as using a ResNet on images?
Introducing AnySat: one model for any resolution (0.2m–250m), scale (0.3–2600 hectares), and modalities (choose from 11 sensors & time series)!
Try it with just a few lines of code:
19.12.2024 10:46 — 👍 35 🔁 10 💬 2 📌 2
Guillaume Astruc, Nicolas Gonthier, Clement Mallet, Loic Landrieu
AnySat: An Earth Observation Model for Any Resolutions, Scales, and Modalities
https://arxiv.org/abs/2412.14123
19.12.2024 06:45 — 👍 6 🔁 3 💬 0 📌 0
⚠️Reconstructing sharp 3D meshes from a few unposed images is a hard and ambiguous problem.
☑️With MAtCha, we leverage a pretrained depth model to recover sharp meshes from sparse views including both foreground and background, within mins!🧵
🌐Webpage: anttwo.github.io/matcha/
11.12.2024 14:59 — 👍 38 🔁 11 💬 4 📌 1
🌍 Guessing where an image was taken is a hard, and often ambiguous problem. Introducing diffusion-based geolocation—we predict global locations by refining random guesses into trajectories across the Earth's surface!
🗺️ Paper, code, and demo: nicolas-dufour.github.io/plonk
10.12.2024 15:56 — 👍 97 🔁 32 💬 8 📌 5
Hi, I am a PhD student from @imagineenpc.bsky.social. Could you also add us both please?
25.11.2024 15:55 — 👍 4 🔁 0 💬 1 📌 0
Assoc. Prof. in computer science at Univ. Bretagne Sud / IRISA
Research in time-series analysis with applications to Earth observations
👩💻📈🛰️🌍
Researcher in photogrammetry
Trying to understand scenes in 3D.
Postdoc at @ecoledesponts.bsky.social , PhD at @tugraz.bsky.social
Research Scientist @ Google DeepMind - working on video models for science. Worked on video generation; self-supervised learning; VLMs - 🦩; point tracking.
Trending papers in Vision and Graphics on www.scholar-inbox.com.
Scholar Inbox is a personal paper recommender which keeps you up-to-date with the most relevant progress in your field. Follow us and never miss a beat again!
Prof. @notredame.bsky.social. IEEE Computer Society PAMI TC Chair. Computer Vision Foundation CTO. Artificial Intelligence + Digital Humanities + History of Technology. wjscheirer.com
Artist working on and about A.I. https://evar.in
Research scientist at Google Deepmind
generative modeling, rl, birds, poetry, games, robots
📍London 🔗 edouardleurent.com
Postdoc in Digital Narratives @ P1 in Copenhagen; PhD in Computer Vision; conceptual artist; tortured-philosopher; ex-poet
Niantic Spatial, Research.
Throws machine learning at traditional computer vision pipelines to see what sticks. Differentiates the non-differentiable.
📍Europe 🔗 http://ebrach.github.io
Official Account for the European Conference on Computer Vision (ECCV) #ECCV2026, Malmo 🇸🇪 Hosted by @jbhaurum and @CSProfKGD
🔥🗺️ Pyrogeographer.
🛰️🛩️🔥 #RemoteSensing of #Wildfire.
❤️🚒 Passionate about finding ways to help emergency responders.
📣 #SciComm
👩💻 https://www.kristaleewest.com/
📍 Colorado, USA
VP Geopatial @ Hexagon | geogeek | cyclist | outdoor enthusiast | curious thinker | continuous learner | Views my own. #geospatial
Assistant Professor Machine Learning & Remote Sensing at Wageningen University, NL
AI Researcher @ LGND AI // Core team @ Climate Change AI
https://konstantinklemmer.github.io
Professor for Data Science in Earth Observation @tumuenchen.bsky.social




























