
I had always wanted to work on something that can combine my love for fiction and NLP research, making this project a lot of fun. Huge thanks to the wonderful @melaniesclar.bsky.social and @tsvetshop.bsky.social!
We welcome any feedback and questions -- don't hesitate to reach out!
16/16
22.04.2025 18:50 — 👍 1 🔁 1 💬 0 📌 0

But how can story summaries have plot holes? Upon close inspection we find LLMs often omit crucial details in the summary that make subsequent events illogical or inconsistent. This highlights weaknesses in summarization—a task many consider "solved" with current LLMs.
13/n
22.04.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0

Our results show LLM-generated content contains significantly more plot holes than human-authored stories: 50%+ higher detection rates for summaries and 100%+ increase for contemporary adaptations of classics.
12/n
22.04.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0
We then assess plot holes in LLM generated text, focusing on tasks of story summarization and contemporary adaptation of classical stories. We use our best model on FlawedFictions to automatically detect the presence of plot holes in LLM generated stories.
11/n
22.04.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0


Does extra test time compute help? Mostly no. Increasing reasoning effort for o1 and o3-mini shows no improvements. Claude-3.7-Sonnet's extended thinking helps, but still underperforms models using <50% of the test time compute.
9/n
22.04.2025 18:50 — 👍 1 🔁 0 💬 1 📌 0

Yet on FlawedFictionsLong (our benchmark with longer stories), even the best models barely outperform trivial baselines. And these stories are still under 4000 words—far shorter than novels or screenplays where plot holes typically occur.
8/n
22.04.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0
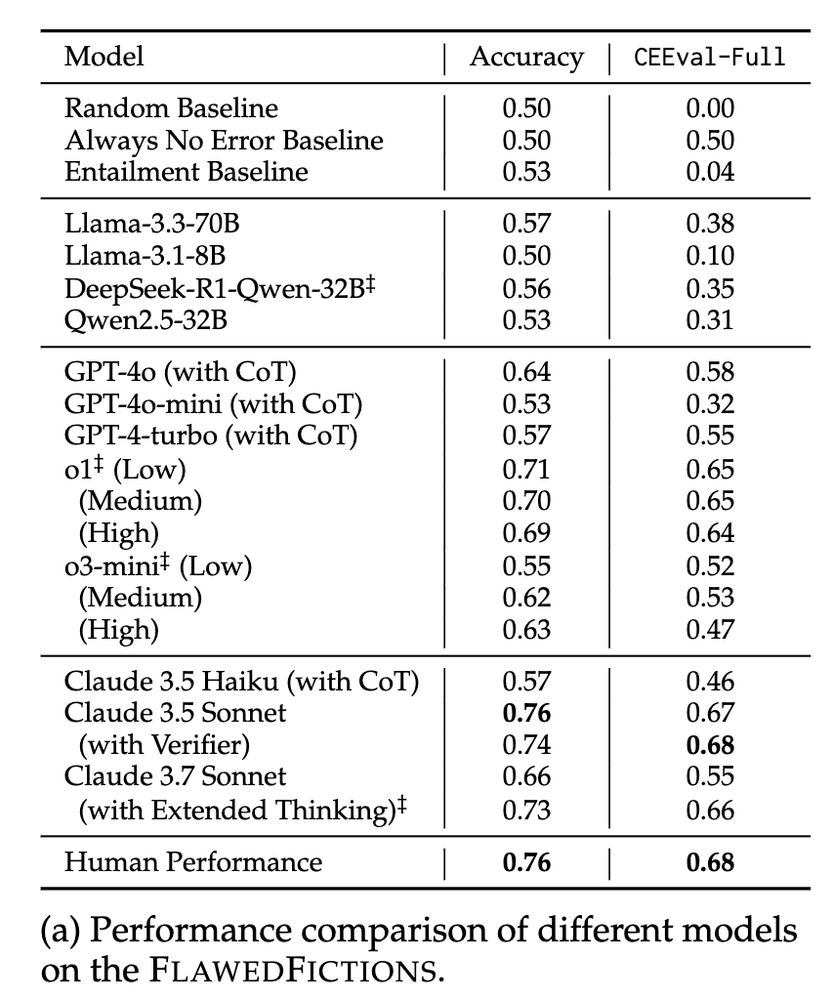
We find that most open-weight models and proprietary LLMs like GPT-4o-mini, GPT-4o, and Claude-Haiku struggle on the task, often only slightly improving over trivial baselines. Advanced models like Claude-3.5-Sonnet and o1 fare better, approaching human performance.
7/n
22.04.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0
We tested various LLMs on FlawedFictions. For classification task we report accuracy and for localization task we define CEEval-Full (0-1) that measures if the models correctly localize the sentences with error and the sentences contradicted by the error.
6/n
22.04.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0

Using FlawedFictionsMaker + human verification, we created FlawedFictions - a benchmark for plot hole detection that tests: a) identifying if a story contains a plot hole, and b) localizing both the error and the contradicted fact in the text
5/n
22.04.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0

Diagram showing the"FlawedFictionsMaker" algorithm that introduces plot holes into stories. It has 5 steps labeled A through E: A: "Partition Original Story in Three Acts" - Shows three story snippets about Watson's injured left arm. B: "Extract Story Facts" - Lists facts including "Sherlock lives in Baker Street" and "Watson has a war wound on his left arm." C: "Select and Build Contradicting Fact" - Shows "What if Watson had a war wound on his left knee instead?" D: "Generate Counterfactual Story" - Shows the same three story snippets but with "knee" replacing "arm" in red text. E: "Rebuild Story, Creating a Plot Hole" - Shows the altered story with inconsistent mentions of both arm and knee injuries.
We introduce FlawedFictionsMaker an algorithm to controllably generate plot holes in stories by extracting facts from a story's first act and contradicting them later in the story.
E.g. If Watson has a left arm injury, we edit it to become a knee injury in later mentions.
4/n
22.04.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0
It can also be interpreted as inference time world-modeling - inferring the rules of a story's world at test time and assessing if they're consistently followed throughout the narrative.
3/n
22.04.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0
Why study plot hole detection? It's a sophisticated reasoning problem requiring:
- Tracking states across long contexts
- Common sense & pragmatics for implicit details
- Theory of mind for character motivations/beliefs
2/n
22.04.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0

A screenshot of the first page of the paper, containing the paper title: Finding Flawed Fictions: Evaluating Complex Reasoning in Language Models via Plot Hole Detection and the names of the authors: Kabir Ahuja, Melanie Sclar, and Yulia Tsvetkov. All the three authors are from CSE department in the University of Washington in Seattle, USA. They can be reached at {kahuja,msclar,yuliats}@cs.washington.edu
📢 New Paper!
Tired 😴 of reasoning benchmarks full of math & code? In our work we consider the problem of reasoning for plot holes in stories -- inconsistencies in a storyline that break the internal logic or rules of a story’s world 🌎
W @melaniesclar.bsky.social, and @tsvetshop.bsky.social
1/n
22.04.2025 18:50 — 👍 10 🔁 4 💬 1 📌 1
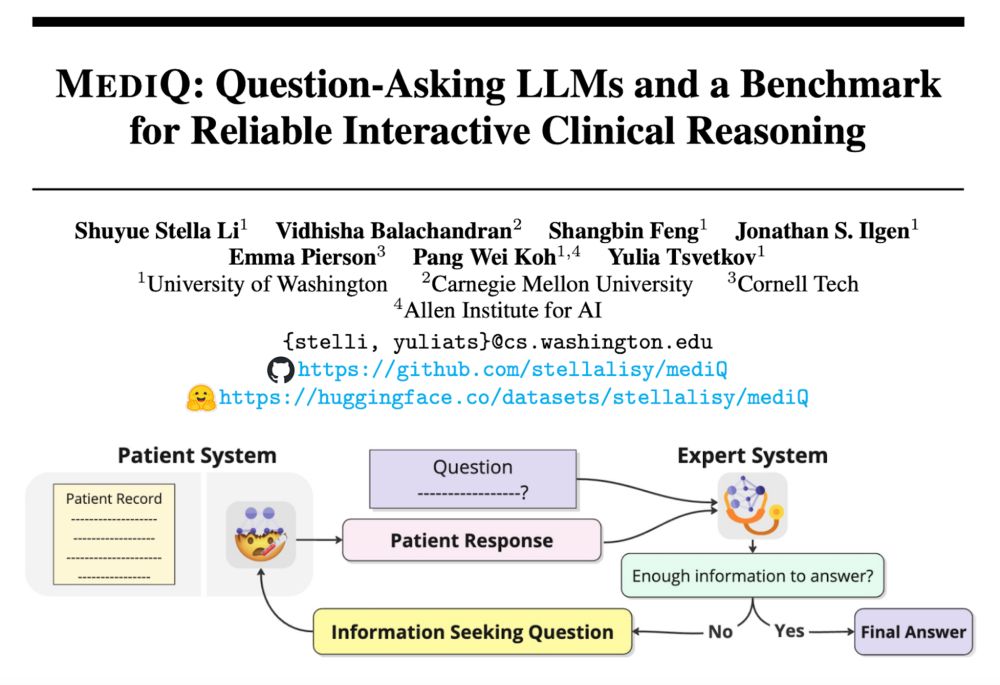
31% of US adults use generative AI for healthcare 🤯But most AI systems answer questions assertively—even when they don’t have the necessary context. Introducing #MediQ a framework that enables LLMs to recognize uncertainty🤔and ask the right questions❓when info is missing: 🧵
06.12.2024 22:51 — 👍 68 🔁 14 💬 2 📌 2
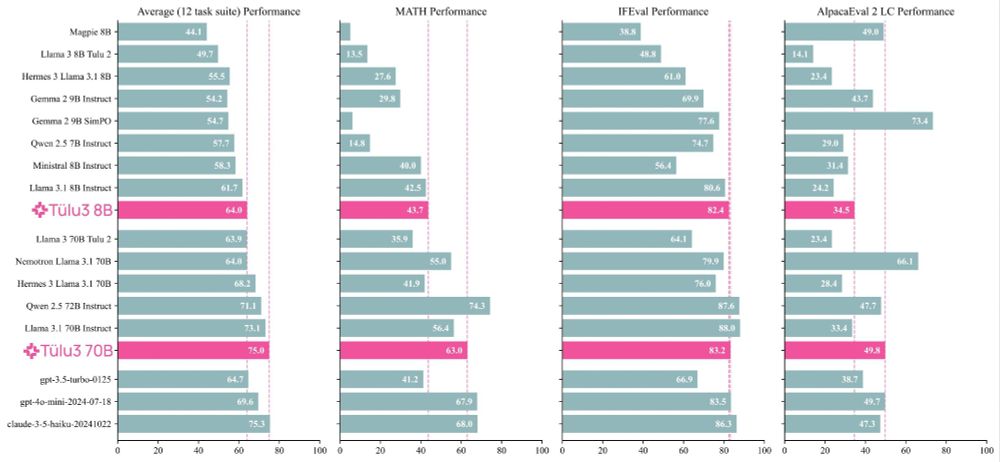
Excited to release Tulu 3! We worked hard to try and make the best open post-training recipe we could, and the results are good!
I was lucky enough to work on almost every stage of the pipeline in one way or another. Some comments + highlights ⬇️
21.11.2024 17:45 — 👍 9 🔁 5 💬 1 📌 0
PhD Student @ UNSW Sydney
PhD at UW iSchool. Research in NLP, Responsible AI, AI Ethics.
She/her
navreeetkaur.github.io
causal ml; ai+society; social media, comp social science. having fun.. my opinions. he/him. http://hci.social/@emrek
Assistant Professor at UC Berkeley and UCSF.
Machine Learning and AI for Healthcare. https://alaalab.berkeley.edu/
<Causality | Ph.D. Candidate @mit | Physics>
I narrate (probably approximately correct) causal stories.
Past: Research Fellow @MSFTResearch
Website: abhinavkumar.info
PhD Student @ UW CSE
NLP | BData | Mental Health
CS PhD @Harvard • Pre-doc @GoogleDeepMind • Anything `science', ~cosmos, and Oxford commas
I work at Sakana AI 🐟🐠🐡 → @sakanaai.bsky.social
https://sakana.ai/careers
I research interactive and explainable Sociotechnical Artificial Intelligence, building models that push the frontier of learnability and generalizability through data-deep exploration as well as technologies that support human collaboration and learning
PhD student WAVLab@LTI, CMU
Multimodality and multilinguality
prev. predoc Google Deepmind
Researcher in NLP, ML, computer music. Prof @uwcse @uwnlp & helper @allen_ai @ai2_allennlp & familiar to two cats. Single reeds, tango, swim, run, cocktails, מאַמע־לשון, GenX. Opinions not your business.
Ph.D. Student at UNC NLP | Prev: Apple, Amazon, Adobe (Intern) vaidehi99.github.io | Undergrad @IITBombay
Robotics PhD @ UW | IITK, CMU
Wandering musician with a beach ball
Professor at UW; Researcher at Meta. LMs, NLP, ML. PNW life.
PhD Student at Mila and McGill | Research in ML and NLP | Past: AI2, MSFTResearch
arkilpatel.github.io
Postdoc at Uppsala University Computational Linguistics with Joakim Nivre
PhD from LMU Munich, prev. UT Austin, Princeton, @ltiatcmu.bsky.social, Cambridge
computational linguistics, construction grammar, morphosyntax
leonieweissweiler.github.io
Director, MIT Computational Psycholinguistics Lab. President, Cognitive Science Society. Chair of the MIT Faculty. Open access & open science advocate. He.
Lab webpage: http://cpl.mit.edu/
Personal webpage: https://www.mit.edu/~rplevy


























