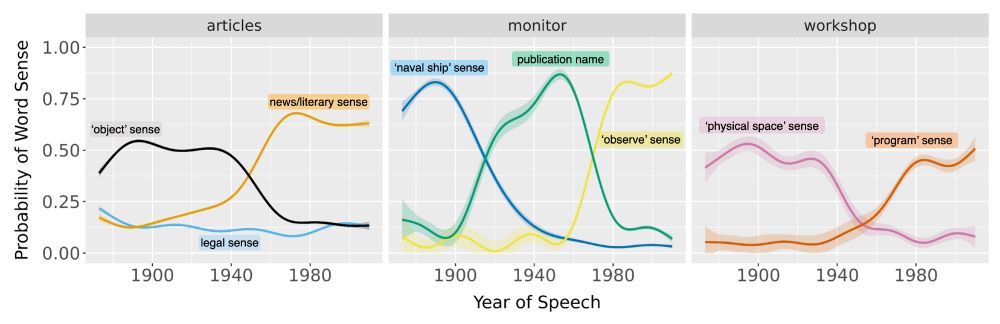
Our new paper in #PNAS (bit.ly/4fcWfma) presents a surprising finding—when words change meaning, older speakers rapidly adopt the new usage; inter-generational differences are often minor.
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
29.07.2025 12:05 — 👍 34 🔁 17 💬 3 📌 2

AgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories
We are releasing the first benchmark to evaluate how well automatic evaluators, such as LLM judges, can evaluate web agent trajectories.
15.04.2025 19:10 — 👍 7 🔁 4 💬 1 📌 1
Thoughtology paper is out!! 🔥🐳
We study the reasoning chains of DeepSeek-R1 across a variety of tasks and find several surprising and interesting phenomena!
Incredible effort by the entire team!
🌐: mcgill-nlp.github.io/thoughtology/
02.04.2025 07:10 — 👍 4 🔁 0 💬 0 📌 0
Exploiting Instruction-Following Retrievers for Malicious Information Retrieval
Parishad BehnamGhader, Nicholas Meade, Siva Reddy
Instruction-following retrievers can efficiently and accurately search for harmful and sensitive information on the internet! 🌐💣
Retrievers need to be aligned too! 🚨🚨🚨
Work done with the wonderful Nick and @sivareddyg.bsky.social
🔗 mcgill-nlp.github.io/malicious-ir/
Thread: 🧵👇
12.03.2025 16:15 — 👍 12 🔁 8 💬 1 📌 0
Llamas browsing the web look cute, but they are capable of causing a lot of harm!
Check out our new Web Agents ∩ Safety benchmark: SafeArena!
Paper: arxiv.org/abs/2503.04957
10.03.2025 17:50 — 👍 9 🔁 3 💬 0 📌 0
Paper: arxiv.org/pdf/2502.14678
Data: tinyurl.com/chase-data
Code: github.com/McGill-NLP/C...
21.02.2025 16:28 — 👍 2 🔁 1 💬 0 📌 0
𝐍𝐨𝐭𝐞: Our work is a preliminary exploration into attempting to automatically generate high quality challenging benchmarks for LLMs. We discuss concrete limitations and huge scope for future work in the paper.
21.02.2025 16:28 — 👍 2 🔁 0 💬 1 📌 0
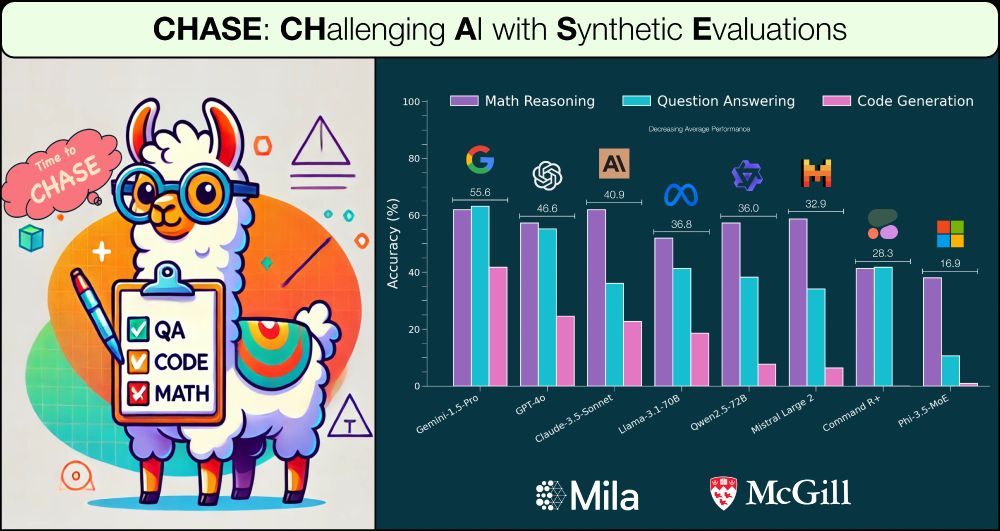
Results:
- SOTA LLMs achieve 40-60% performance
- 𝐂𝐇𝐀𝐒𝐄 distinguishes between models well (as opposed to similar performances on standard benchmarks like GSM8k)
- While LLMs today have 128k-1M context sizes, 𝐂𝐇𝐀𝐒𝐄 shows they struggle to reason even at ~50k context size
21.02.2025 16:28 — 👍 2 🔁 0 💬 1 📌 0

𝐂𝐇𝐀𝐒𝐄 uses 2 simple ideas:
1. Bottom-up creation of complex context by “hiding” components of reasoning process
2. Decomposing generation pipeline into simpler, "soft-verifiable" sub-tasks
21.02.2025 16:28 — 👍 2 🔁 0 💬 1 📌 0

𝐂𝐇𝐀𝐒𝐄 automatically generates challenging evaluation problems across 3 domains:
1. 𝐂𝐇𝐀𝐒𝐄-𝐐𝐀: Long-context question answering
2. 𝐂𝐇𝐀𝐒𝐄-𝐂𝐨𝐝𝐞: Repo-level code generation
3. 𝐂𝐇𝐀𝐒𝐄-𝐌𝐚𝐭𝐡: Math reasoning
21.02.2025 16:28 — 👍 2 🔁 0 💬 1 📌 0
Why synthetic data for evaluation?
- Creating “hard” problems using humans is expensive (and may hit a limit soon!)
- Impractical for humans to annotate long-context data
- Other benefits: scalable, renewable, mitigate contamination concerns
21.02.2025 16:28 — 👍 3 🔁 0 💬 1 📌 0
Presenting ✨ 𝐂𝐇𝐀𝐒𝐄: 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐧𝐠 𝐜𝐡𝐚𝐥𝐥𝐞𝐧𝐠𝐢𝐧𝐠 𝐬𝐲𝐧𝐭𝐡𝐞𝐭𝐢𝐜 𝐝𝐚𝐭𝐚 𝐟𝐨𝐫 𝐞𝐯𝐚𝐥𝐮𝐚𝐭𝐢𝐨𝐧 ✨
Work w/ fantastic advisors Dima Bahdanau and @sivareddyg.bsky.social
Thread 🧵:
21.02.2025 16:28 — 👍 17 🔁 8 💬 1 📌 1
MSc Master's @mila-quebec.bsky.social @mcgill-nlp.bsky.social
Research Fellow @ RBC Borealis
Model analysis, interpretability, reasoning and hallucination
Studying model behaviours to make them better :))
Looking for Fall '26 PhD
Indigenous language technology. PhD candidate at McGill University in Montreal. Ngāpuhi Nui Tonu.
Reinforcement learning researcher - PhD candidate @Mila
PhD-ing at McGill Linguistics + Mila, working under Prof. Siva Reddy. Mostly computational linguistics, with some NLP; habitually disappointed Arsenal fan
PhD fellow in XAI, IR & NLP
✈️ Mila - Quebec AI Institute | University of Copenhagen 🏰
#NLProc #ML #XAI
Recreational sufferer
PhD student at Université de Montréal and Mila
https://mj10.github.io/
PhD student @mila-quebec.bsky.social; Interested in performative prediction, causality, evolution of cooperation,NLProc; previously Unbabel, HotClubeJazz, @istecnico.bsky.social
Researcher (OpenAI. Ex: DeepMind, Brain, RWTH Aachen), Gamer, Hacker, Belgian.
Anon feedback: https://admonymous.co/giffmana
📍 Zürich, Suisse 🔗 http://lucasb.eyer.be
Visiting Scientist at Schmidt Sciences. Visiting Researcher at Stanford NLP Group
Interested in AI safety and interpretability
Previously: Anthropic, AI2, Google, Meta, UNC Chapel Hill
PhD candidate at University of Oxford. Engineer and a computational neuroscientist thinking about pain and safe AI. (Views are my own; he/his)
https://www.pranavmahajan.info/
Ph.D. Student at Mila
Visiting Researcher at Meta FAIR
Causality, Trustworthy ML
Former: Microsoft Research, IIT Kanpur
divyat09.github.io
MIT // researching fairness, equity, & pluralistic alignment in LLMs
previously @ MIT media lab, mila / mcgill
i like language and dogs and plants and ultimate frisbee and baking and sunsets
https://elinorp-d.github.io
Research scientist at Meta, PhD candidate at Mila and Université de Montréal. Working on multimodal vision+language generation. Català a Zúric.
PhD student @uwnlp.bsky.social
Postdoc, artiste, shitposter
exchanging algorithms with ai
ekinakyurek.github.io
(open-source) ai and health @ mila, neuropoly & montreal heart institute | prev: harvardmed
rohanbanerjee.github.io


















