
The best part is: you can start using our methods today by pip installing our open source package probmetrics.
📖 Read the paper: arxiv.org/abs/2511.03685
👩💻 Calibrate your models with probmetrics: github.com/dholzmueller...

@eberta.bsky.social
PhD student at INRIA Paris. Working on calibration of machine learning classifiers.
The best part is: you can start using our methods today by pip installing our open source package probmetrics.
📖 Read the paper: arxiv.org/abs/2511.03685
👩💻 Calibrate your models with probmetrics: github.com/dholzmueller...



Still using temperature scaling?
With @dholzmueller.bsky.social, Michael I. Jordan and @bachfrancis.bsky.social we argue that with well designed regularization, more expressive models like matrix scaling can outperform simpler ones across calibration set sizes, data dimensions, and applications.
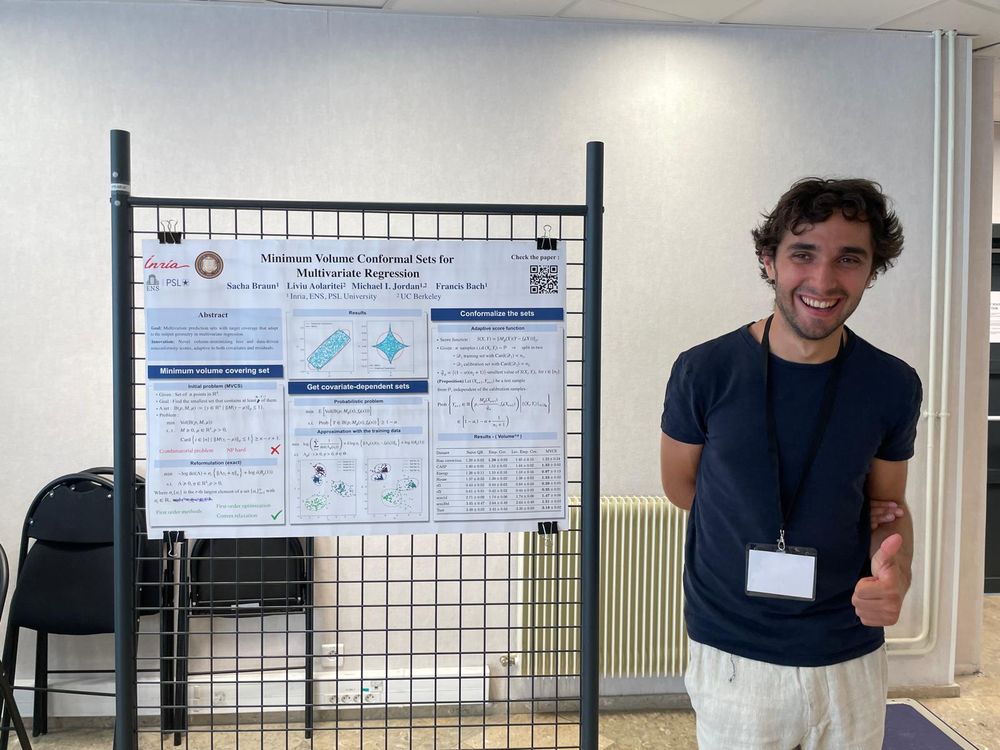
COLT Workshop on Predictions and Uncertainty was a banger!
I was lucky to present our paper "Minimum Volume Conformal Sets for Multivariate Regression", alongside my colleague @eberta.bsky.social and his awsome work on calibration.
Big thanks to the organizers!
#ConformalPrediction #MarcoPolo
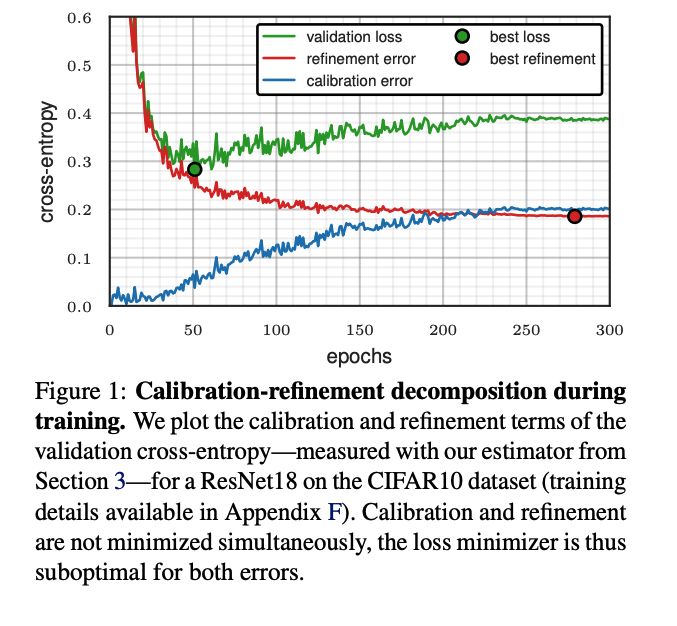
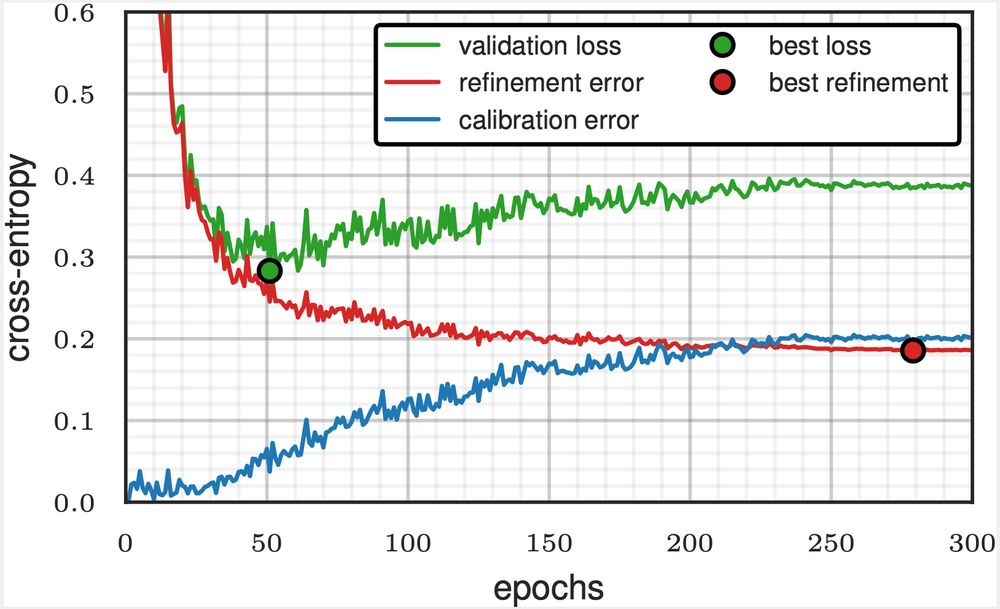
What if we have been doing early stopping wrong all along?
When you break the validation loss into two terms, calibration and refinement
you can make the simplest (efficient) trick to stop training in a smarter position
This suggests a clear link with the ROC curve in the binary case, but writing it down formally, the relationship between the two is a bit ugly…
05.02.2025 10:38 — 👍 1 🔁 0 💬 0 📌 0Isotonic regression minimizes the risk of any « Bregman loss function » (included cross-entropy, see section 2.1 below) up to monotonic relabeling, which looks a lot like our « refinement as a minimiser » formulation. It also find the ROC convex hull.
proceedings.mlr.press/v238/berta24...
However, for calibration of the final model, adding an intercept or doing matrix scaling might work even better in certain scenario (imbalanced, non-centered). We’ve experimented with existing implementation with limited success for now, maybe we should look at that in more details…
05.02.2025 10:23 — 👍 0 🔁 0 💬 0 📌 0Not yet! Vector/matrix scaling has more parameters so it is more prone to overfitting the validation set, and simple TS seems to calibrate well empirically, which is why we stuck with that to estimate refinement error for early stopping.
05.02.2025 10:20 — 👍 1 🔁 0 💬 1 📌 0I’ve observed refinement being minimized before calibration for small (probably under-fitter) neural nets. In many cases, the refinement curve also starts « overfitting » at some point.
04.02.2025 19:33 — 👍 2 🔁 0 💬 0 📌 0We’ve not tried what you’re suggesting but if the training cost is small this might indeed be a good option!
04.02.2025 19:32 — 👍 1 🔁 0 💬 0 📌 0Indeed regularisation seems very important. It can have large impact on how calibration error behaves. Combined with learning rate schedulers, this can have surprising effects, like calibration error starting to go down again at some point.
04.02.2025 19:28 — 👍 1 🔁 0 💬 1 📌 0Thanks! We have experimented with many models, observing various behaviours. The « calibration going up while refinement goes down » seems typical in deep learning from what I’ve seen. With smaller models other things can appear, as suggested by our logistic regression analysis (section 6).
04.02.2025 19:24 — 👍 2 🔁 0 💬 2 📌 0 03.02.2025 13:33 — 👍 4 🔁 0 💬 0 📌 0
03.02.2025 13:33 — 👍 4 🔁 0 💬 0 📌 0
📖 Read the full paper: arxiv.org/abs/2501.19195
💻 Check out our code: github.com/dholzmueller...
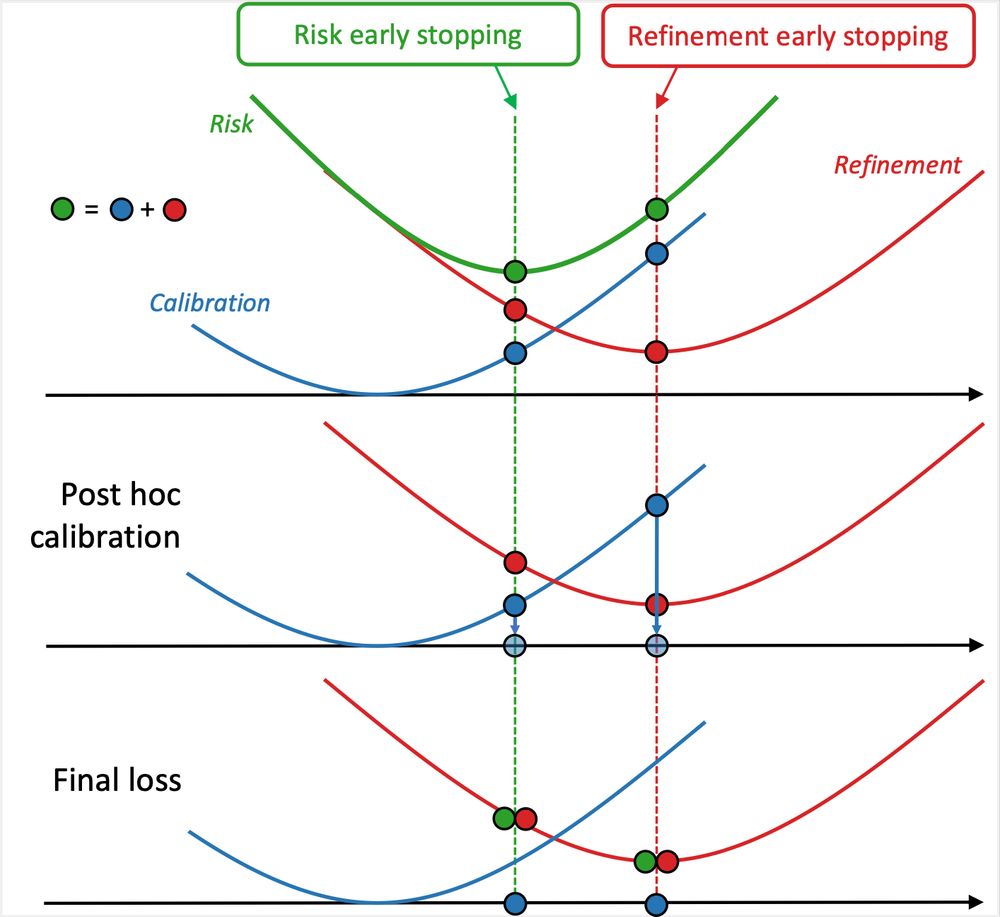
Early stopping on validation loss? This leads to suboptimal calibration and refinement errors—but you can do better!
With @dholzmueller.bsky.social, Michael I. Jordan, and @bachfrancis.bsky.social, we propose a method that integrates with any model and boosts classification performance across tasks.



















