Paper🧵 (cross-posted at X): When does composition of diffusion models "work"? Intuitively, the reason dog+hat works and dog+horse doesn’t has something to do with independence between the concepts being composed. The tricky part is to formalize exactly what this means. 1/
11.02.2025 05:59 —
👍 39
🔁 15
💬 2
📌 2
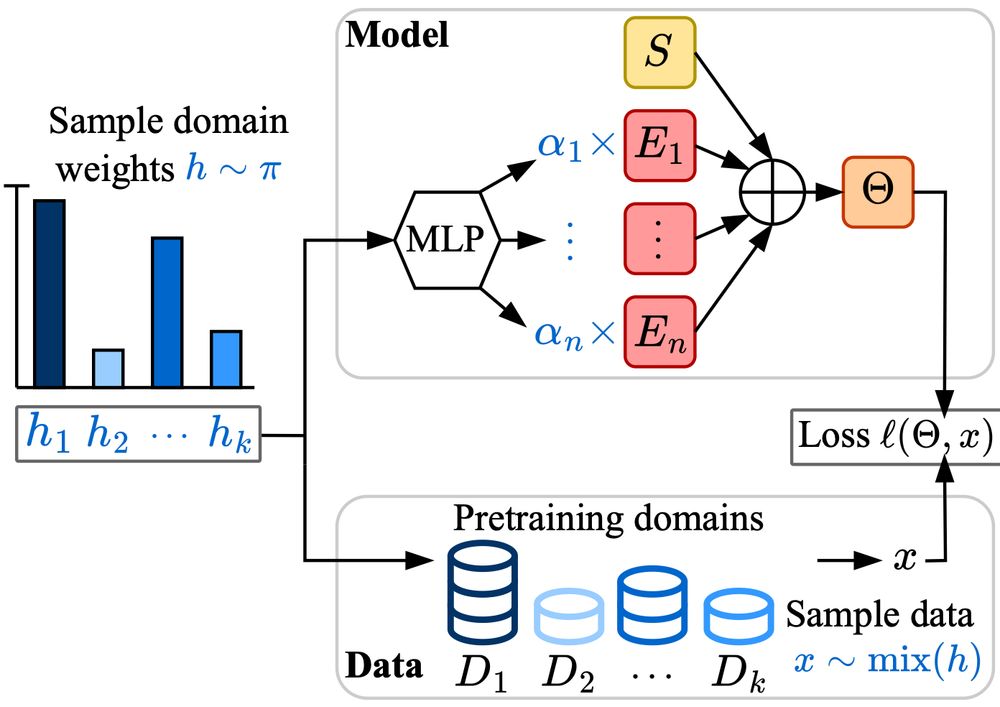
Excited to share Soup-of-Experts, a new neural network architecture that, for any given specific task, can instantiate in a flash a small model that is very good on it.
Made with ❤️ at Apple
Thanks to my co-authors David Grangier, Angelos Katharopoulos, and Skyler Seto!
arxiv.org/abs/2502.01804
05.02.2025 09:32 —
👍 12
🔁 4
💬 0
📌 0
Really proud of these two companion papers by our team at GDM:
1) Joint Learning of Energy-based Models and their Partition Function
arxiv.org/abs/2501.18528
2) Loss Functions and Operators Generated by f-Divergences
arxiv.org/abs/2501.18537
A thread.
31.01.2025 12:06 —
👍 14
🔁 3
💬 1
📌 1
How do tokens evolve as they are processed by a deep Transformer?
With José A. Carrillo, @gabrielpeyre.bsky.social and @pierreablin.bsky.social, we tackle this in our new preprint: A Unified Perspective on the Dynamics of Deep Transformers arxiv.org/abs/2501.18322
ML and PDE lovers, check it out!
31.01.2025 16:56 —
👍 95
🔁 16
💬 2
📌 0
Byte Pair Encoding is a tokenization method that starts with all characters as initial tokens. It iteratively merges the most frequent adjacent byte pairs in the text, adding new tokens to the vocabulary until reaching a predefined size. The output is a sequence of tokens. https://buff.ly/42oG80f
30.01.2025 06:00 —
👍 14
🔁 2
💬 1
📌 1

🎓 💫 We are opening post-doc positions at the intersection of AI, data science, and medicine:
• Large Language Models for French medical texts
• Evaluating digital medical devices: statistics and causal inference
29.01.2025 08:19 —
👍 27
🔁 16
💬 1
📌 0
Mixture of experts are all the rage when it comes to shipping low-latency LLMs.
Check out this awesome work by Samira et al. about scaling laws for mixture of experts !
28.01.2025 10:15 —
👍 3
🔁 0
💬 0
📌 0

🚨 One question that has always intrigued me is the role of different ways to increase a model's capacity: parameters, parallelizable compute, or sequential compute?
We explored this through the lens of MoEs:
28.01.2025 06:25 —
👍 18
🔁 8
💬 1
📌 3

Thrilled to share the latest work from our team at
@Apple
where we achieve interpretable and fine-grained control of LLMs and Diffusion models via Activation Transport 🔥
📄 arxiv.org/abs/2410.23054
🛠️ github.com/apple/ml-act
0/9 🧵
10.12.2024 13:09 —
👍 47
🔁 15
💬 3
📌 5
The Apple Machine Learning Research (MLR) team in Paris has openings for both FTE roles and a short-term post-doc position to contribute to our team's research agenda. Researchers at Apple's MLR (led by Samy Bengio) target impactful publications in top-tier ML venues and OSS.
18.12.2024 17:05 —
👍 13
🔁 3
💬 1
📌 2
Congratulations for these new models !!
22.11.2024 10:33 —
👍 4
🔁 0
💬 0
📌 0

𝗗𝗼𝗲𝘀 𝗮𝘂𝘁𝗼𝗿𝗲𝗴𝗿𝗲𝘀𝘀𝗶𝘃𝗲 𝗽𝗿𝗲-𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝘄𝗼𝗿𝗸 𝗳𝗼𝗿 𝘃𝗶𝘀𝗶𝗼𝗻? 🤔
Delighted to share AIMv2, a family of strong, scalable, and open vision encoders that excel at multimodal understanding, recognition, and grounding 🧵
paper: arxiv.org/abs/2411.14402
code: github.com/apple/ml-aim
HF: huggingface.co/collections/...
22.11.2024 08:32 —
👍 59
🔁 19
💬 3
📌 1
YouTube video by probabl
Why the MinHashEncoder is great for boosted trees
Great video explaining a clever vectorization for learning on strings and dirty categories:
the MinHashEncoder is fast, stateless, and excellent with tree-based learners.
It's in @skrub-data.bsky.social
youtu.be/ZMQrNFef8fg
21.11.2024 10:12 —
👍 75
🔁 8
💬 2
📌 0





