The Visual Complexity Penalty in Code Understanding - SWE-bench Multimodal Analysis | Jatin Ganhotra
Analyzing how visual content dramatically impacts AI agents' performance on SWE tasks
5. I call it the Visual Complexity Penalty — and I break it down in detail in my latest post:
🔗 jatinganhotra.dev/blog/swe-age...
📊 Includes full leaderboard analysis, complexity breakdown, and takeaways.
RT if you're building SWE agents — or trying to understand their real limits.
27.07.2025 23:00 — 👍 0 🔁 0 💬 0 📌 0
4. This isn't a benchmark artifact.
It's a wake-up call.
🧠 Current AI systems cannot effectively combine visual + structural code understanding.
And that's a serious problem for real-world software workflows.
27.07.2025 23:00 — 👍 1 🔁 0 💬 1 📌 0
3. It's not just the images.
Multimodal tasks often require multi-file edits and focus on JavaScript-based, user-facing applications rather than Python backends.
The combination of visual reasoning + frontend complexity is devastating.
27.07.2025 23:00 — 👍 0 🔁 0 💬 1 📌 0
2. Why the collapse?
📸 90.6% of instances in SWE-bench Multimodal contain visual content.
When images are present, solve rates drop from ~100% to ~25% across all top-performing agents.
27.07.2025 23:00 — 👍 0 🔁 0 💬 1 📌 0
1. SWE agents are getting better. Some achieve 70-75% accuracy on code-only benchmarks like SWE-bench Verified.
But when the same models are tested on SWE-bench Multimodal, scores fall to ~30%.
27.07.2025 23:00 — 👍 0 🔁 0 💬 1 📌 0
🚨 New Blog Post:
AI agents collapse under visual complexity.
A 73.2% performance drop when images are introduced in SWE-bench Multimodal.
Here's why this matters — and what it tells us about the future of AI in software engineering:
🧵👇
27.07.2025 23:00 — 👍 1 🔁 0 💬 1 📌 0
From 73% to 11%: Revealing True SWE-Agent Capabilities with Discriminative Subsets | Jatin Ganhotra
Like the tale of the Emperor's new clothes, sometimes we need fresh eyes on familiar benchmarks.
SWE-Bench Verified shows 73% success rates, but focusing on discriminative subsets reveals a different story: 11%
What really challenges AI agents? Analysis: jatinganhotra.dev/blog/swe-age...
21.07.2025 19:24 — 👍 0 🔁 0 💬 1 📌 0
Fascinating finding: When you remove the 156 problems that 61+ agents solve, performance drops dramatically
Top agents: 73% → 11%
This isn't about making things harder - it's about measuring what matters 🎯
jatinganhotra.dev/blog/swe-age...
17.06.2025 19:47 — 👍 0 🔁 0 💬 0 📌 0
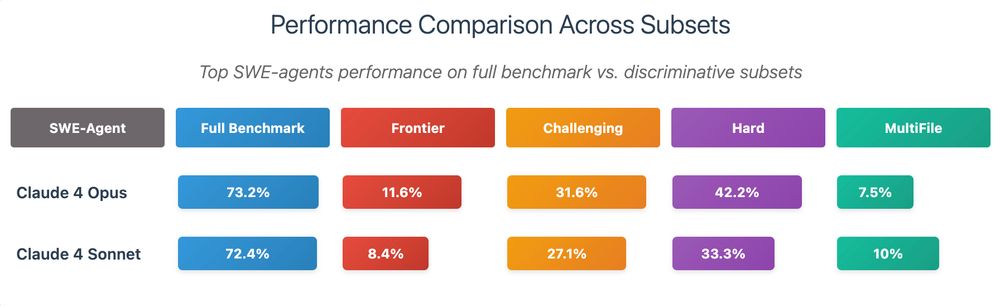
5/ The results are eye-opening:
Claude 4 Opus on full benchmark: 73.2% ✅
Claude 4 Opus on Frontier subset: 11.6% 😬
This isn't just harder - it's revealing what agents ACTUALLY can't do
06.06.2025 20:05 — 👍 0 🔁 0 💬 1 📌 0
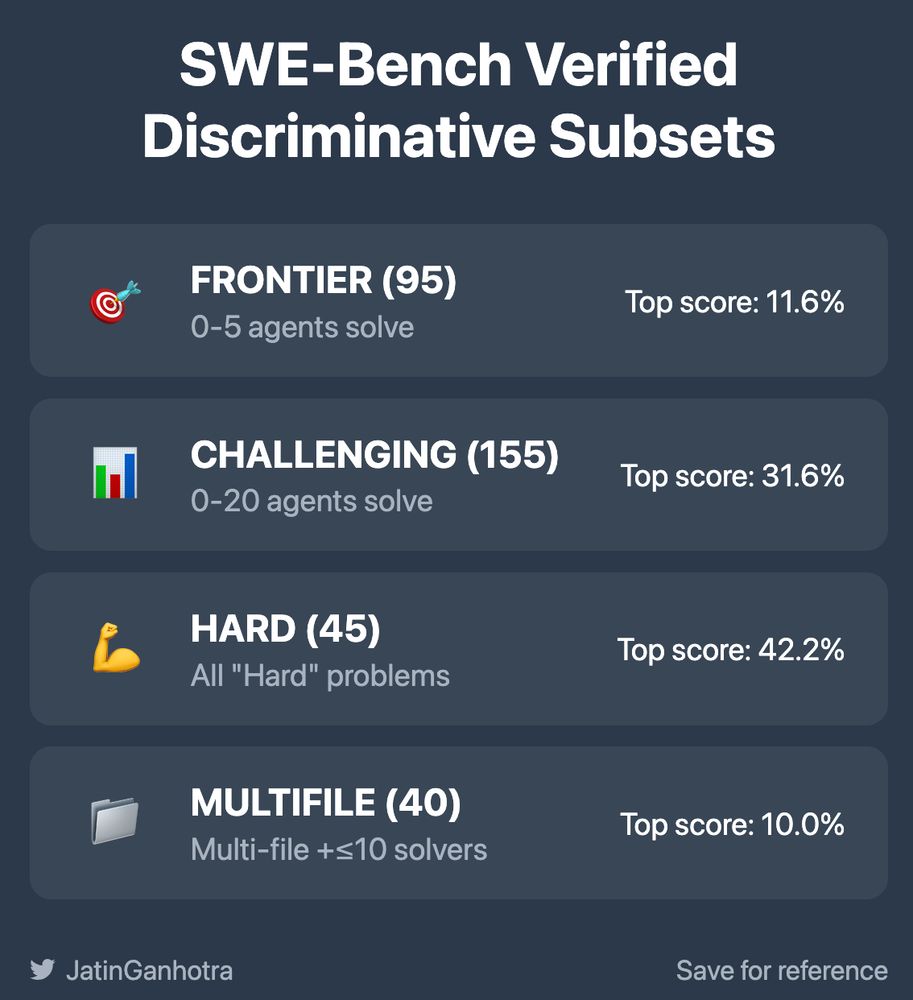
4/ Solution: 4 targeted subsets that reveal true agent capabilities
Each subset targets different evaluation needs - from maximum sensitivity (Frontier) to real-world complexity (MultiFile)
Performance drops from 73% to as low as 10%!
06.06.2025 20:05 — 👍 0 🔁 0 💬 1 📌 0
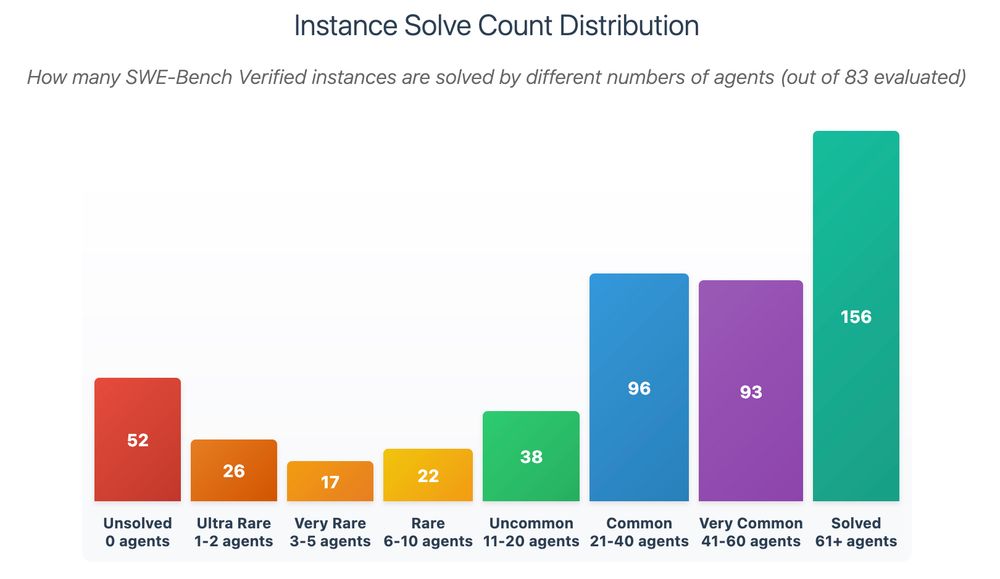
3/ I analyzed all 500 problems against 83 different SWE-agents
The distribution is shocking:
- 52 problems: ZERO agents can solve
- 26 problems: Only 1-2 agents succeed
- 156 problems: 61+ agents solve easily
06.06.2025 20:05 — 👍 0 🔁 0 💬 1 📌 0
2/ The problem: 156/500 problems are solved by 61+ agents
When everyone gets the same questions right, you can't tell who's actually better @anthropic.com
It's like ranking students when everyone scores 95%+ on the easy questions
06.06.2025 20:05 — 👍 0 🔁 0 💬 1 📌 0
1/ "What gets measured gets improved" - but are we measuring the right things?
SWE-Bench Verified has driven amazing progress, but with most agents solving 350+ same problems, we need new targets @ofirpress.bsky.social
Enter: discriminative subsets that highlight genuine challenges 🧵
06.06.2025 20:05 — 👍 0 🔁 0 💬 1 📌 1
The frontier isn't single-file patches - it's systemic code understanding. ‼️
18.05.2025 17:32 — 👍 0 🔁 0 💬 0 📌 0
Call to Action: What We Need Next
For meaningful progress, we need:
✅ Benchmarks with realistic multi-file distributions
✅ Systems that understand code architecture
✅ Evaluation beyond "tests pass"
✅ Focus on maintainable, human-like solutions
18.05.2025 17:32 — 👍 0 🔁 0 💬 1 📌 0
SWE-bench Leaderboard
Latest Performance Numbers
Latest update: 64 systems on the leaderboard, with "Augment Agent v0" leading at 65.4%.
But break it down:
• Easy tasks: 81.4% solved
• Medium tasks: 62.1% solved
• Hard tasks: 20.0% solved
The difficulty gap persists across all systems.
18.05.2025 17:32 — 👍 0 🔁 0 💬 1 📌 0
Do SWE-Agents Solve Multi-File Issues Like Humans? A Deep Dive into SWE-Bench Verified | Jatin Ganhotra
Deep-dive analysis with anonymized instances shows how current SWE agents bypass multi-file requirements.
🔗 jatinganhotra.dev/blog/swe-age...
This isn't just about performance - it's about approach quality. The benchmark allows solutions that would need significant rework as real PRs.
18.05.2025 17:32 — 👍 0 🔁 0 💬 1 📌 0
Progress vs Reality
While headline numbers look impressive (65.4% on latest leaderboard), this represents an overly optimistic view.
Real-world programming involves far more multi-file complexity than the benchmark suggests.
18.05.2025 17:32 — 👍 0 🔁 0 💬 1 📌 0
The Multi-File Gap
Multi-file issues require different abilities:
• Cross-file dependency tracking
• Architectural comprehension
• Interface consistency management
• Impact analysis across codebases
Current AI excels as "patch generators", not holistic developers.
18.05.2025 17:32 — 👍 0 🔁 0 💬 1 📌 0
Expert Consensus on Benchmark Limitations
This isn't just my take. Andrej Karpathy noted in March 2024 x.com/karpathy/sta...
"SWE-Bench Verified... is great but itself too narrow"
The evaluation crisis in AI coding is real - we need better benchmarks.
18.05.2025 17:32 — 👍 0 🔁 0 💬 1 📌 0
Cracking the Code: How Difficult Are SWE-Bench-Verified Tasks Really? | Jatin Ganhotra
What Makes Tasks Actually Hard
It's not just file count:
• Easy: avg 5 lines changed
• Hard: avg 56 lines changed (11x increase!)
• Multi-file tasks need 4x more hunks & lines vs single-file
Scale matters more than structure.
Full analysis: 🔗 jatinganhotra.dev/blog/swe-age...
18.05.2025 17:32 — 👍 0 🔁 0 💬 1 📌 0
Difficulty Distribution Reality Check
By human expert estimates:
• Easy (≤15 min): 38.80% of issues
• Medium (15-60 min): 52.20% of issues
• Hard (≥1 hour): Only 9% of issues
91% of tasks take <1 hour for humans. Where's the challenge? ⁉️
18.05.2025 17:32 — 👍 0 🔁 0 💬 1 📌 0
Do SWE-Agents Solve Multi-File Issues Like Humans? A Deep Dive into SWE-Bench Verified | Jatin Ganhotra
AI vs Human Approaches Diverge
Most concerning: 20 multi-file issues were "solved" by changing only single files.
SWE-Agents often bypass the intended multi-file solution, finding shortcuts that pass tests but miss the architectural point.
Analysis: 🔗 jatinganhotra.dev/blog/swe-age...
18.05.2025 17:32 — 👍 0 🔁 0 💬 1 📌 0
The Multi-File Frontier: Why SWE-Bench Verified Doesn't Reflect Real-World Programming Challenges | Jatin Ganhotra
Single-File Saturation Reached
We're hitting saturation on single-file issues. When combining all top systems:
• Single-file: ~90% resolution (386/429)
• Multi-file: Only ~54% resolution (38/71)
Deep dive: 🔗 jatinganhotra.dev/blog/swe-age...
The easy problems are nearly solved.
18.05.2025 17:32 — 👍 0 🔁 0 💬 1 📌 0
Dramatic Performance Drop on Multi-File Tasks
Performance on multi-file tasks plummets dramatically:
Top performers like 'Augment Agent v0':
• Single-file: 71.56% resolved
• Multi-file: 28.17% resolved
Even the best systems struggle with interconnected code changes.
18.05.2025 17:32 — 👍 1 🔁 0 💬 1 📌 0
SWE-Bench Verified ⊊ real-world SWE tasks | Jatin Ganhotra
The Fundamental Reality Gap
Core issue: SWE-Bench-Verified ≠ real-world SWE tasks
Only 14.2% of issues require multi-file changes vs 50.27% in SWE-Bench train set (which better represents real-world).
Deep dive: 🔗 jatinganhotra.dev/blog/swe-age...
This creates a massive reality gap.
18.05.2025 17:32 — 👍 0 🔁 0 💬 1 📌 0
It's interesting that OpenAI now includes "OpenAI Internal SWE tasks" as another benchmark. Since we don't know the composition and difficulty of these internal tasks, this analysis of SWE-Bench-Verified becomes even more relevant.
I've been voicing these concerns since Dec 2024
18.05.2025 17:32 — 👍 0 🔁 0 💬 1 📌 0
@guyd33 on the X-bird site. PhD student at NYU, broadly cognitive science x machine learning, specifically richer representations for tasks and cognitive goals. Otherwise found cooking, playing ultimate frisbee, and making hot sauces.
AI Architect | North Carolina | AI/ML, IoT, science
WARNING: I talk about kids sometimes
Building Langroid - harness LLMs with Multi-Agent programming.
https://github.com/langroid/langroid
IIT KGP CS, CMU/PhD/ML.
Adjunct Prof/AI @ CMU/Tepper & UPitt.
Ex- Los Alamos, Goldman Sachs, Yahoo, MediaMath.
We make AI speak the language of every application
Research engineer @ IBM Research
timrbula.com
NLP Research Scientist at IBM Research
Biomedical Computer Vision & Language Models, scads.ai / Leipzig University, also NFDI4BIOIMAGE, NEUBIAS/GloBIAS, GPUs, AI, ML 🔬🖥️🚀 views:mine
compling phd student @ boulder
rare languages, morphology, finite state automata
michaelginn.com
First-year NLP PhD @ USC | Intern @ TogetherAI | Prev. UW, AWS
https://nanami18.github.io/
Research Scientist at @ibmresearch #NLProc, #RL.
Opinions are my own.
PhDing @AIM_Harvard @MassGenBrigham|PhD Fellow @Google | Previously @Bos_CHIP @BrandeisU
More robustness and explainabilities 🧐 for Health AI.
shanchen.dev
Assoc. Prof. in Linguistics at CU Boulder (@bouldernlp.bsky.social). My group researches computational methods for endangered and low-resource languages, plus computational discourse and semantics: @lecslab.bsky.social. I'm a musician and have cats!
NLP PhD from CU Boulder.
prev: Apple, ETS, Pearson, Army Research Lab.
Next: Kensho
https://adamits.github.io
NLP/Computational Linguistics PhD @lecslab.bsky.social and @bouldernlp.bsky.social
I am interested in typologically robust multilingual NLP and technology for language documentation
https://covetedfish.github.io/
🥇 LLMs together (co-created model merging, BabyLM, textArena.ai)
🥈 Spreading science over hype in #ML & #NLP
Proud shareLM💬 Donor
@IBMResearch & @MIT_CSAIL
Professor at Cardiff University (Cardiff NLP). Natural Language Processing researcher. Computational Social Science
PhD student @CMU LTI
NLP | IR | Evaluation | RAG
https://kimdanny.github.io
Into creative ML/AI, NLP, data science and digital humanities, narrative, infovis, games, sf & f. Consultant, ds in Residence at Google Arts & Culture. (Lyon, FR) Newsletter arnicas.substack.com.
Assistant professor @ UIUC, studying personalized language and communication
NLP research - PhD student at UW






















