How can we combine the process-level insight that think-aloud studies give us with the large scale that modern online experiments permit? In our new CogSci paper, we show that speech-to-text models and LLMs enable us to scale up the think-aloud method to large experiments!
25.06.2025 05:32 — 👍 22 🔁 5 💬 0 📌 0
Can we record and study human chains of thought? Check out our new work led by @danielwurgaft.bsky.social and @benpry.bsky.social !!
25.06.2025 18:11 — 👍 1 🔁 0 💬 0 📌 0

Some absolutely marvellous work from @gandhikanishk.bsky.social et al! Wow!
11.03.2025 15:57 — 👍 1 🔁 1 💬 0 📌 0
12/13 Would also like to thank Charlie Snell, Dimitris Papailiopoulos, Eric Zelikman, Alex Havrilla, Rafael Rafaelov, @upiter.bsky.social and Archit Sharma for discussions about the magic and woes of RL training with LLMs.
04.03.2025 18:15 — 👍 2 🔁 0 💬 1 📌 0
11/13 Work with amazing collaborators Ayush Chakravarthy, Anikait Singh, Nathan Lile and @noahdgoodman.bsky.social
04.03.2025 18:15 — 👍 0 🔁 0 💬 1 📌 0
10/13 This paper gives us some clues as to what facilitated self-improvement in the recent generation of LLMs and what kind of data enables it. The key lies in exploration of the right behaviors!
04.03.2025 18:15 — 👍 1 🔁 0 💬 1 📌 0
9/13 Our findings reveal a fundamental connection between a model's initial reasoning behaviors and its capacity for improvement through RL. Models that explore verification, backtracking, subgoals, and backward chaining are primed for success.
04.03.2025 18:15 — 👍 0 🔁 0 💬 1 📌 0

8/13 By curating an extended pretraining set to amplify them, we enable Llama to match Qwen's improvement.
04.03.2025 18:15 — 👍 0 🔁 0 💬 1 📌 0
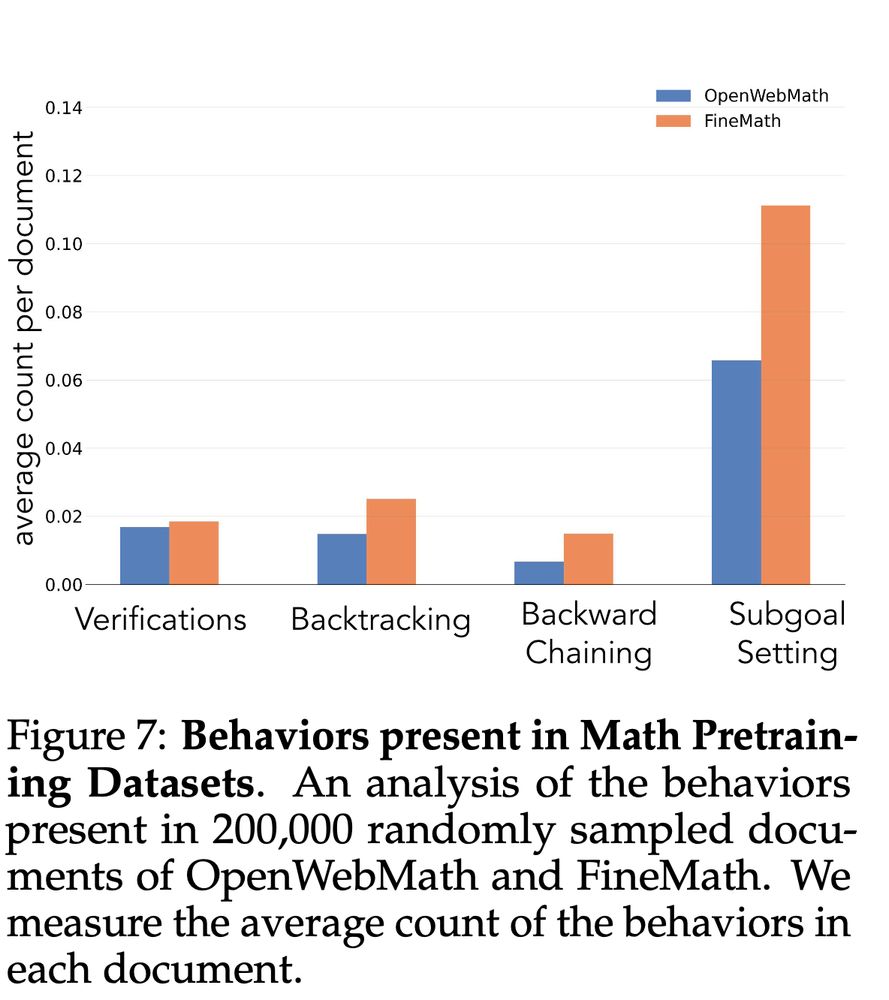
7/13 Can we apply these insights to pretraining? We analyze math pretraining sets like OpenWebMath & FineMath, finding these key behaviors are quite rare.
04.03.2025 18:15 — 👍 1 🔁 0 💬 1 📌 0
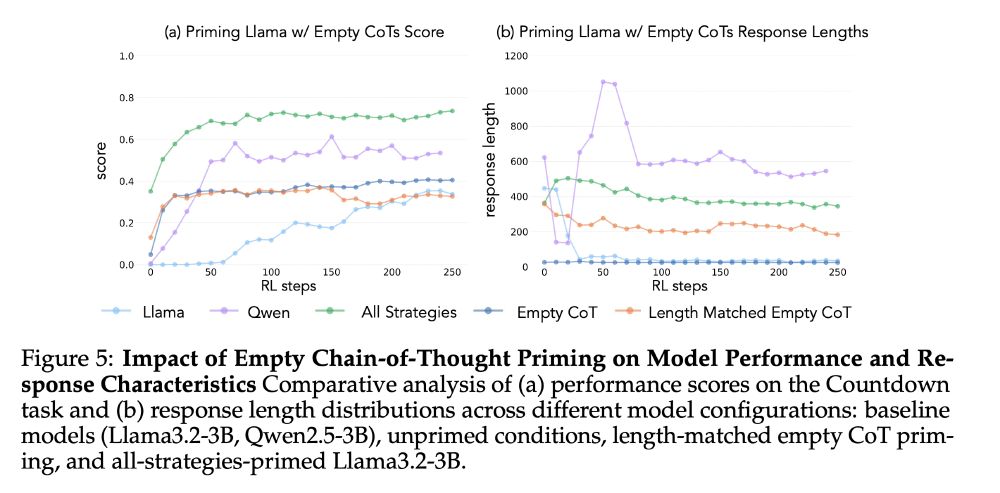
6/13 Empty and length matched empty chain-of-thought priming fails to produce improvement, reverting models to baseline performance. This shows it's the specific cognitive behaviors, not just longer outputs, enabling learning.
04.03.2025 18:15 — 👍 3 🔁 0 💬 1 📌 0
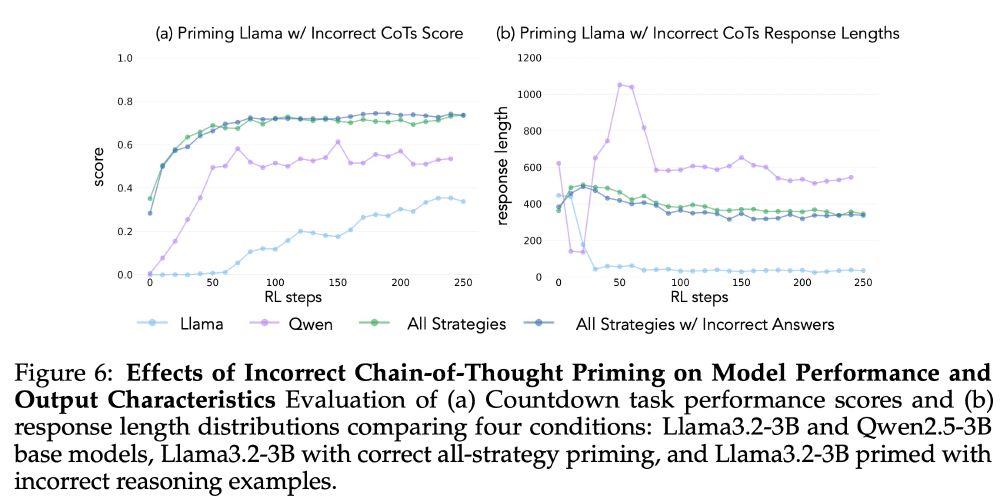
5/13 Crucially, the reasoning patterns matter more than having correct answers. Models primed with incorrect solutions that demonstrate the right cognitive behaviors still show substantial improvement. The behaviors are key.
04.03.2025 18:15 — 👍 2 🔁 0 💬 1 📌 0
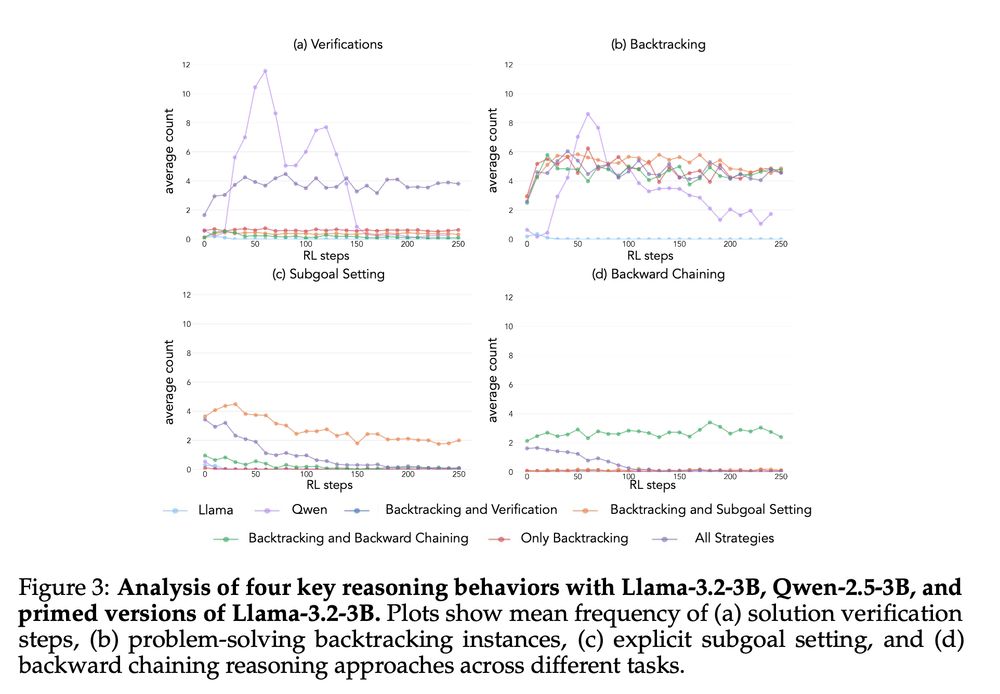
4/13 We curate priming datasets with different behavior combinations and find that models primed with backtracking and verification consistently improve. Interestingly, RL selectively amplifies the most useful behaviors for reaching the goal.
04.03.2025 18:15 — 👍 1 🔁 0 💬 1 📌 0
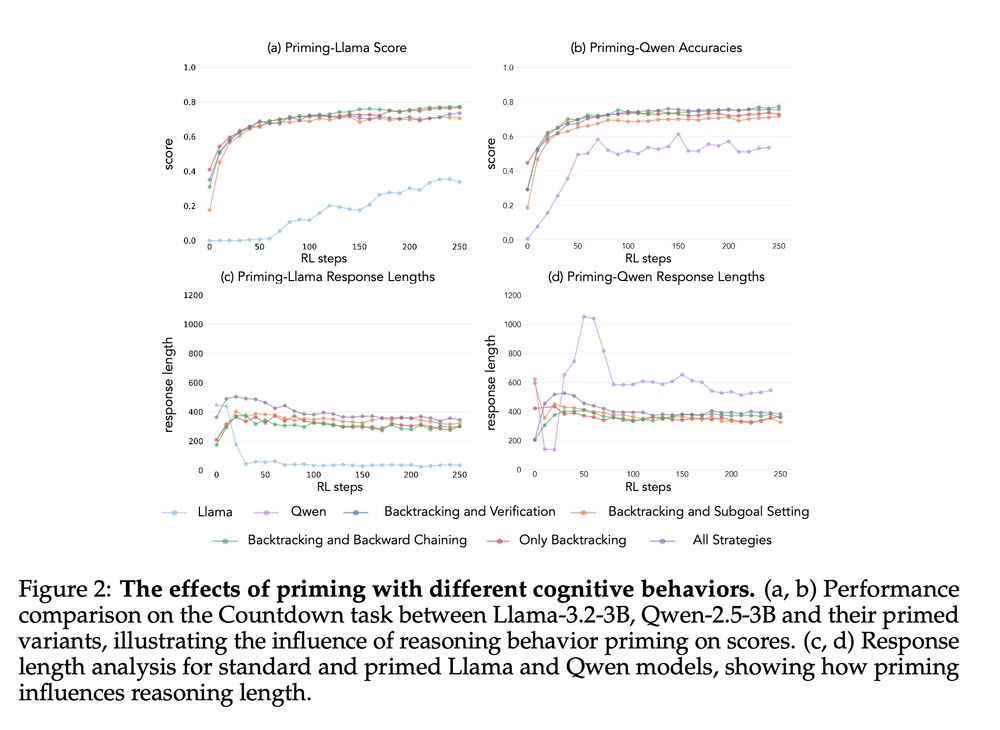
3/13 Can we change a model's initial properties to enable improvement? Yes! After "priming" Llama, by finetuning on examples demonstrating these behaviors, it starts improving from RL just like Qwen. The priming jumpstarts the learning process.
04.03.2025 18:15 — 👍 4 🔁 0 💬 1 📌 0
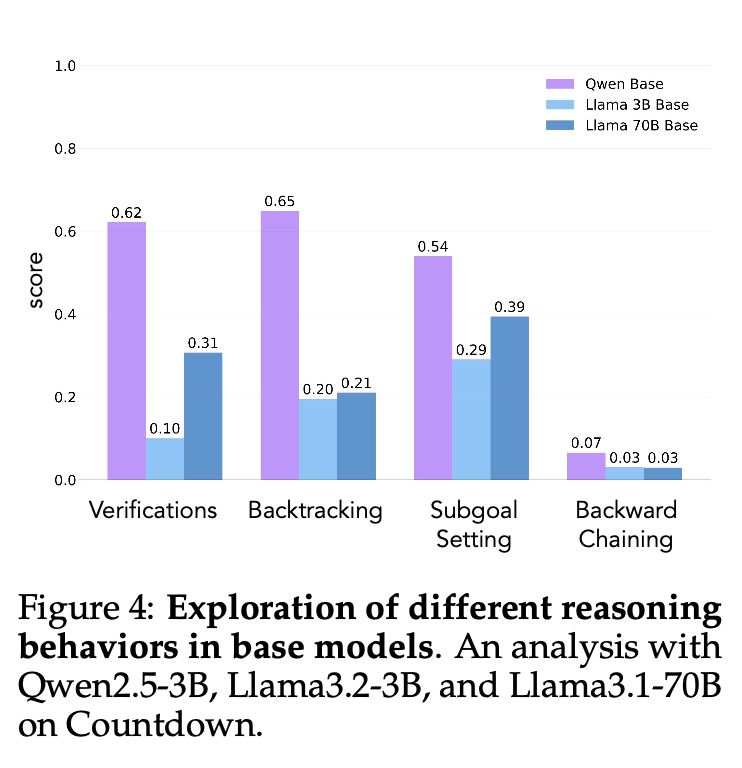
2/13 We identify 4 key cognitive behaviors that enable successful learning: Verification (checking work), Backtracking (trying new approaches), Subgoal Setting (breaking problems down) & Backward Chaining (working backwards from a goal). Qwen naturally exhibits these, while Llama mostly lacks them.
04.03.2025 18:15 — 👍 5 🔁 1 💬 1 📌 1

1/13 New Paper!! We try to understand why some LMs self-improve their reasoning while others hit a wall. The key? Cognitive behaviors! Read our paper on how the right cognitive behaviors can make all the difference in a model's ability to improve with RL! 🧵
04.03.2025 18:15 — 👍 56 🔁 17 💬 2 📌 3
emotionally, i’m constantly walking into a glass door
19.02.2025 04:44 — 👍 40 🔁 7 💬 4 📌 0

a romantic toaster presenting a single red rose
Can Large Language Models THINK and UNDERSTAND? The answer from cognitive science is, of course, lolwut YES!
The more interesting question is CAN TOASTERS LOVE? Intriguingly, the answer is ALSO YES! And they love YOU
19.01.2025 12:39 — 👍 102 🔁 20 💬 4 📌 7

They present a scientifically optimized recipe of “Pasta alla Cacio e pepe” based on their findings, enabling a consistently flawless execution of this classic dish.
"Phase behavior of Cacio and Pepe sauce"
arxiv.org/abs/2501.00536
06.01.2025 23:47 — 👍 24 🔁 1 💬 0 📌 2
These are actually good? No blatant physics violations at least? Definitely better than I expected
18.12.2024 05:53 — 👍 5 🔁 0 💬 1 📌 0
Actually can you try it with objects that it might have actually seen? Like a blue book falling on a tennis ball? I feel like in abstract prompts like these material properties are underspecified.
18.12.2024 03:08 — 👍 4 🔁 0 💬 1 📌 0

The broader spectrum of in-context learning
The ability of language models to learn a task from a few examples in context has generated substantial interest. Here, we provide a perspective that situates this type of supervised few-shot learning...
What counts as in-context learning (ICL)? Typically, you might think of it as learning a task from a few examples. However, we’ve just written a perspective (arxiv.org/abs/2412.03782) suggesting interpreting a much broader spectrum of behaviors as ICL! Quick summary thread: 1/7
10.12.2024 18:17 — 👍 123 🔁 31 💬 2 📌 1
I'll be at Neurips this week :) looking forward to catching up with folks! Please reach out if you want to chat!!
09.12.2024 05:26 — 👍 4 🔁 0 💬 0 📌 0
Oo can you add me?
22.11.2024 00:52 — 👍 1 🔁 0 💬 1 📌 0
Okay the people requested one so here is an attempt at a Computational Cognitive Science starter pack -- with apologies to everyone I've missed! LMK if there's anyone I should add!
go.bsky.app/KDTg6pv
11.11.2024 17:27 — 👍 223 🔁 92 💬 71 📌 3
I am not actively looking for people this cycle, but re-sharing in case of relevance to others
12.11.2024 00:25 — 👍 3 🔁 1 💬 0 📌 0
Told my kids about the liar's paradox today and, I'm not lying, they didn't believe me.
17.12.2023 16:00 — 👍 3 🔁 1 💬 0 📌 0
Daily-updated stream of AI news || Monitoring research blog sites || Research articles from ArXiv
Postdoc, philosophy in psychiatry/medicine/biology, cogsci - functional symptoms (FND), predictive processing, basal cognition
Producer @manymindspod.bsky.social; freelance writer; fine arts photographer
https://www.linkedin.com/in/urte-laukaityte
Cognitive and perceptual psychologist, industrial designer, & electrical engineer. Assistant Professor of Industrial Design at University of Illinois Urbana-Champaign. I make neurally plausible bio-inspired computational process models of visual cognition.
phd-ing @ stanford hci
online groups, social platform design, and mental models. also books. books books books.
Stanford Health Policy: Interdisciplinary innovation, discovery and education to improve health policy here at home and around the world.
PhD @Stanford working w Noah Goodman
Studying in-context learning and reasoning in humans and machines
Prev. @UofT CS & Psych
Mentally I’m on the beach
https://lichess.org The free chess server. No paywall, no tracking, no ads. Just the good stuff. User support requests should be directed to https://lichess.org/contact
"I used to be just like you before I started going to therapy"
Research Scientist at Google DeepMind, interested in multiagent reinforcement learning, game theory, games, and search/planning.
Lover of Linux 🐧, coffee ☕, and retro gaming. Big fan of open-source. #gohabsgo 🇨🇦
For more info: https://linktr.ee/sharky6000
The official Bluesky account for the United States Department of Labor.
AMERICAN WORKERS FIRST!
Your U.S. Consumer Product Safety Commission. Product safety info, data, and recalls. Standing for safety since 1972. Official account of the USCPSC. HQ: Bethesda, MD.
Subscribe for recall emails on CPSC.gov.
Report unsafe products on SaferProducts.gov
A podcast about the airport books that captured our hearts and ruined our minds.
Patreon: patreon.com/ifbookspod
Merch: ifbookspod.dashery.com
Incoming Associate Professor of Computer Science and Psychology @ Princeton. Posts are my views only. https://cims.nyu.edu/~brenden/
I like tokens! Lead for OLMo data at @ai2.bsky.social (Dolma 🍇) w @kylelo.bsky.social. Open source is fun 🤖☕️🍕🏳️🌈 Opinions are sampled from my own stochastic parrot
more at https://soldaini.net
The official account of the Stanford Institute for Human-Centered AI, advancing AI research, education, policy, and practice to improve the human condition.
Stanford CS PhD working on RL and LLMs with Emma Brunskill and Chris Piech. Co-creator of Trace. Prev @GoogleDeepMind @MicrosoftResearch
Specifically
- Offline RL
- In-context RL
- Causality
https://anie.me/about
Unverified hot takes go to this account
Researching planning, reasoning, and RL in LLMs @ Reflection AI. Previously: Google DeepMind, UC Berkeley, MIT. I post about: AI 🤖, flowers 🌷, parenting 👶, public transit 🚆. She/her.
http://www.jesshamrick.com
LM/NLP/ML researcher ¯\_(ツ)_/¯
yoavartzi.com / associate professor @ Cornell CS + Cornell Tech campus @ NYC / nlp.cornell.edu / associate faculty director @ arXiv.org / researcher @ ASAPP / starting @colmweb.org / building RecNet.io





















