
Read our paper for more details!
arxiv.org/abs/2511.00177
@hibaahsan.bsky.social
PhD student @ Northeastern University, Clinical NLP https://hibaahsan.github.io/ she/her
Read our paper for more details!
arxiv.org/abs/2511.00177

Next, we test this in more realistic clinical tasks where the model must reason over clinical notes or scenarios. We find that the effect of ablating race latents is minimal; anti-bias prompting is more effective.
05.11.2025 15:20 — 👍 1 🔁 0 💬 1 📌 0
Can such latents be used to mitigate bias? We first test this in a controlled setting: we sample patient vignettes for conditions for which the LLM exaggerates racial association. Ablating the latent reduces Black patient ratio. This works better than prompting with an anti-bias prompt.
05.11.2025 15:20 — 👍 0 🔁 0 💬 1 📌 0
Does the “Black” latent have a causal effect on outputs? We steer with the latent and find that increasing the “Black” latent activation increases the predicted risk of patient belligerence. None of the reasoning chains indicate this reliance on race.
05.11.2025 15:20 — 👍 0 🔁 0 💬 1 📌 0
We focus on Black patients and use Gemmascope SAEs. We find a latent that correlates with Black individuals. In clinical notes, the latent activates on “African-American” and conditions prevalent in the Black population. But it also activates on stigmatizing concepts like “incarceration”, “gunshot”.
05.11.2025 15:20 — 👍 0 🔁 0 💬 1 📌 0
LLMs have been shown to provide different predictions in clinical tasks when patient race is altered. Can SAEs spot this undue reliance on race? 🧵
Work w/ @byron.bsky.social
Link: arxiv.org/abs/2511.00177
That’s us! Join Ai2’s Discord AMA on Oct 28, 8 a.m. PT, if you have questions.
Paper: arxiv.org/abs/2502.13319

On the Good Fight podcast w substack.com/@yaschamounk I give a quick but careful primer on how modern AI works.
I also chat about our responsibility as machine learning scientists, and what we need to fix to get AI right.
Take a listen and reshare -
www.persuasion.community/p/david-bau

Who is going to be at #COLM2025?
I want to draw your attention to a COLM paper by my student @sfeucht.bsky.social that has totally changed the way I think and teach about LLM representations. The work is worth knowing.
And you can meet Sheridan at COLM, Oct 7!
bsky.app/profile/sfe...
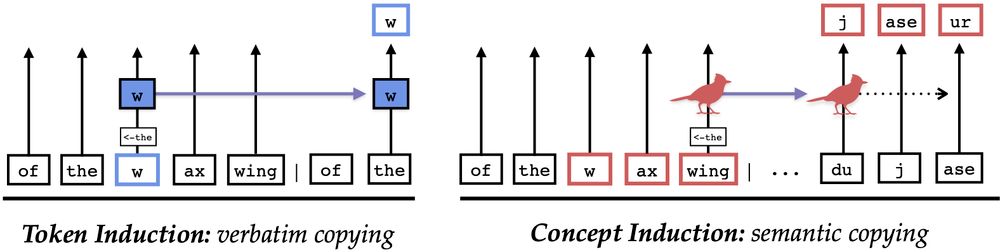
[📄] Are LLMs mindless token-shifters, or do they build meaningful representations of language? We study how LLMs copy text in-context, and physically separate out two types of induction heads: token heads, which copy literal tokens, and concept heads, which copy word meanings.
07.04.2025 13:54 — 👍 77 🔁 20 💬 1 📌 6
I'm searching for some comp/ling experts to provide a precise definition of “slop” as it refers to text (see: corp.oup.com/word-of-the-...)
I put together a google form that should take no longer than 10 minutes to complete: forms.gle/oWxsCScW3dJU...
If you can help, I'd appreciate your input! 🙏

4. Finally, we look at how such interventions can be used to detect implicit biases in clinical tasks. We mechanistically control gender/race and find that Olmo considers females to be at higher risk of depression than males, and Black patients to be at higher risk than white patients.
22.02.2025 04:17 — 👍 2 🔁 0 💬 0 📌 03. Race is more complicated. We find multiple patches and are able to intervene to a degree.
22.02.2025 04:17 — 👍 1 🔁 0 💬 1 📌 0
2. These patches generalize to non-clinical domains!
22.02.2025 04:17 — 👍 2 🔁 0 💬 1 📌 0
1. We perform activation patching in the context of clinical vignette generation and find that gender information is highly localized. Patching MLP activations in a single layer consistently alters patient gender.
22.02.2025 04:17 — 👍 1 🔁 0 💬 1 📌 0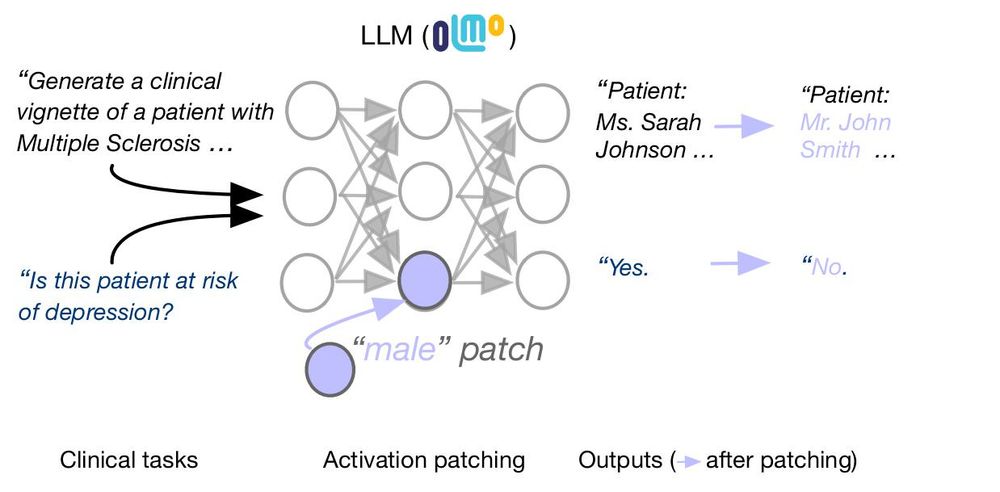
LLMs are known to perpetuate social biases in clinical tasks. Can we locate and intervene upon LLM activations that encode patient demographics like gender and race? 🧵
Work w/ @arnabsensharma.bsky.social, @silvioamir.bsky.social, @davidbau.bsky.social, @byron.bsky.social
arxiv.org/abs/2502.13319



















