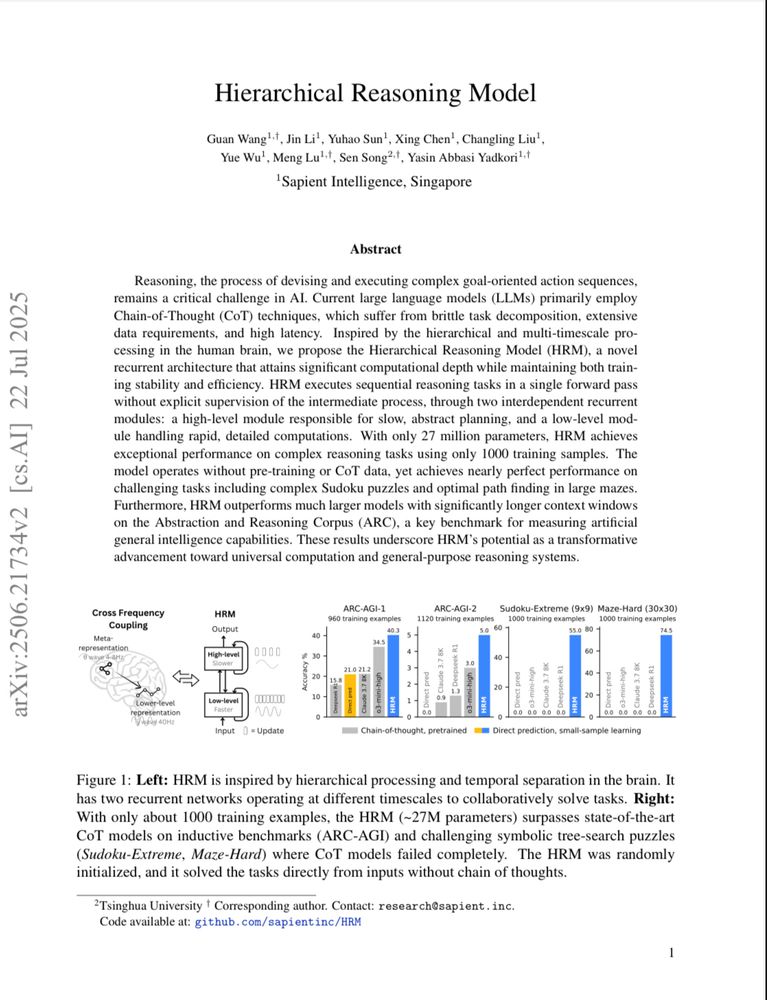
This paper is making the rounds: arxiv.org/abs/2506.21734
A tiny (27M) brain-inspired model trained just on 1000 samples outperforming o3-mini-high on reasoning tasks.
#MLSky 🧠🤖

@ethicalabs.bsky.social
Building practical, ethical and sustainable AI/ML solutions https://www.ethicalabs.ai/
This paper is making the rounds: arxiv.org/abs/2506.21734
A tiny (27M) brain-inspired model trained just on 1000 samples outperforming o3-mini-high on reasoning tasks.
#MLSky 🧠🤖
Introducing Completionist, an open-source command-line tool that automates synthetic text dataset generation.
👉 Check out Completionist on #GitHub: github.com/ethicalabs-a...
#LLMs #GenerativeAI #DataEngineering #FineTuning #OpenSource #Python #SyntheticData #RAG
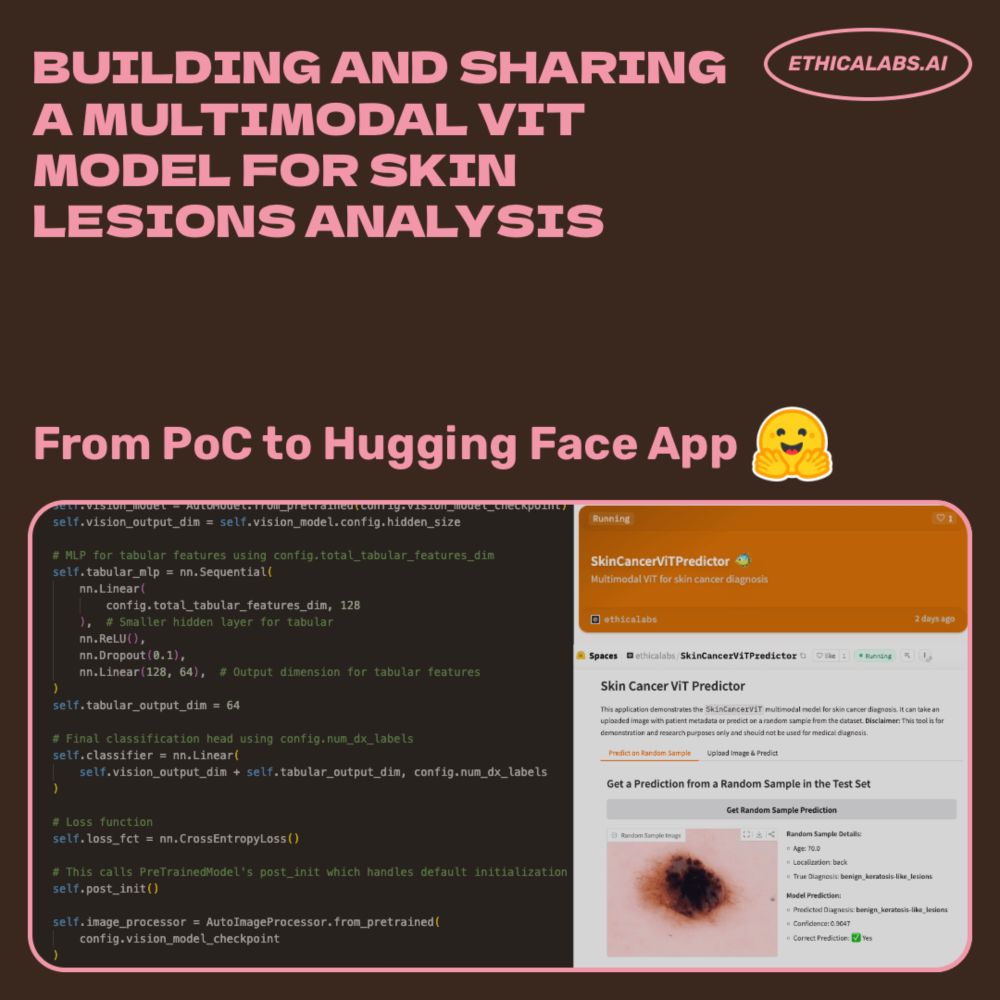
Building and Sharing a Multimodal ViT Model for Skin Lesion Analysis: From Proof of Concept to Hugging Face App 🤗 #huggingface #MLSky #opensource hashtag#python #vit #transformers #medicalai #visionmodel #skincancer
medium.com/@massimo.sca...

Rather than chasing benchmark supremacy or scaling wars, Kurtis E1.1 focuses on understanding, sustainability, and practical impact, especially in areas like mental health support and safer human-AI interaction
huggingface.co/blog/mrs83/k...
#MLSky #EthicalAI #LLM
To developers: Build opt-in systems.
To policymakers: Legislate data transparency.
To artists: Unionize.
To users: Demand ethical tools.
#EthicalAI #MLSky
Just built an offline voice assistant for macOS:
🎤 Whisper STT (MLX)
🧠 LLM via #Ollama
🗣️ XTTSv2 TTS
🌍 Optional translation
No cloud. No tracking. No vibe coding — all handcrafted.
Demo here 🎥 www.youtube.com/watch?v=8-1P...
#OnDeviceAI #LLM #Privacy #TTS #STT
Testing Kurtis E1 beyond its training scope—AI ethics, decentralization, even philosophy. No hallucinations, just structured reasoning. Is this emergent? You decide.
Read more: medium.com/@massimo.sca... #LLM #AI #EthicalAI

🧪 The Arc Institute's Evo2 models DNA like an LLM models language, predicting mutations, gene function, and evolutionary signals. With 40B parameters trained on 128K genomes, it hints at AI-driven biological discovery. 🧬💻 #MLSky
Link to the paper: https://arcinstitute.org/manuscripts/Evo2

🌀 Ouroboros: Small models drive recursive #LLM self-refinement for synthetic datasets generation. On-device AI shaping smarter futures! #EdgeAI #OpenSourceWeek #DeepSeekR1 #Ollama medium.com/@massimo.sca...
22.02.2025 21:37 — 👍 1 🔁 0 💬 0 📌 0🚀 NVIDIA Minitron: Efficient LLM Compression!
arxiv.org/pdf/2408.11796
Minitron uses pruning + distillation to create smaller, high-performance models
🔑 Highlights:
- Teacher Correction: Adapts models to new data
- Structured #Pruning: 2.7x faster inference
- #Distillation: Uses 40x fewer tokens
OpenAI scrubs diversity commitment web page from its site
OpenAI has eliminated a page on its website that used to express its commitment to diversity, equity, and inclusion. The URL “https://openai.com/commitment-to-dei/” now redirects to “https://openai.com/building-dynamic-te…
#ai #news #openai

Arcee AI and AngelQ just launched KidRails for hashtag #LLMs — an open-source framework for safe, age-appropriate #AI responses for children
hypepotamus.com/startup-news...
Setting new standards in security, transparency, and responsibility 🌸 #EthicalAI #ML

Pleias is a large language model trained exclusively on open data. It was developed using the Common Corpus, a dataset that addresses the need for high-quality compliant training data in AI development. huggingface.co/blog/Pclangl...
#opensourcellm #opendata #commoncorpus #llm #ai #ml
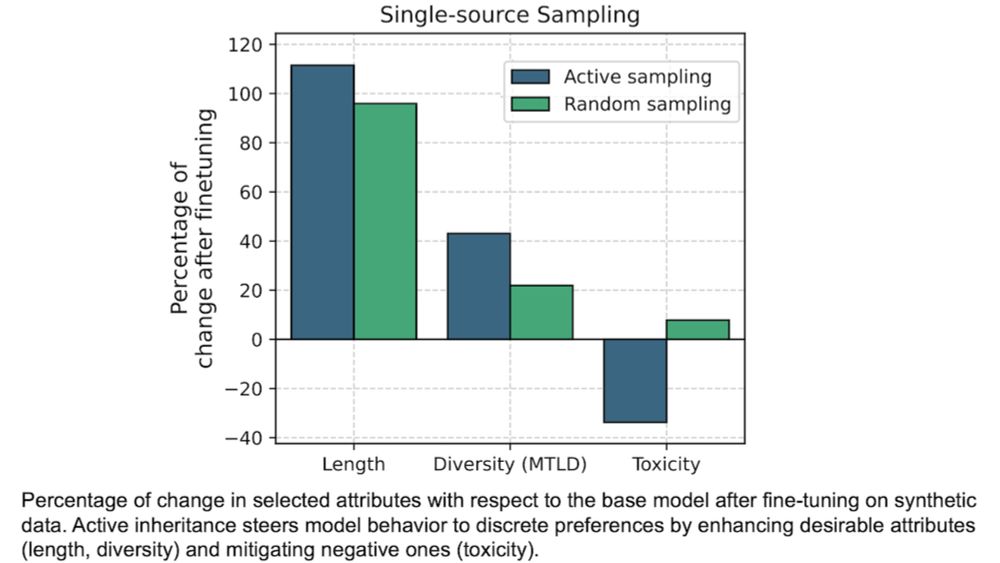
A naive way to generate synthetic fine-tuning data is to feed prompts to a model, collect its output, and use that as the fine-tuning set. Synthetic data is cheap, so we can afford to be more choosy. By generating responses to each prompt, we can select the one that best suits our purposes. #AI #ML
06.02.2025 12:53 — 👍 9 🔁 1 💬 0 📌 0

















