Ah that's something I didn't think of! This will be the next optimization I'll try on my renderer, now that I've saved a lot of memory I can afford some padding.
16.10.2025 09:05 — 👍 1 🔁 0 💬 0 📌 0
Are there engines or apps out there that uses vulkan as their sole gfx API /RHI and provide homemade vk implementations for other backends/platforms (with homemade extensions too) ?
16.09.2025 18:00 — 👍 0 🔁 0 💬 0 📌 0
25H2*
15.09.2025 23:42 — 👍 1 🔁 0 💬 0 📌 0
So it seems like a miracle happend in Win11 24H2. UpdateTileMappings() doesn't seems as unpredictable and slow on NVidia. I only did simple tests though, with buffers and not giga textures.
15.09.2025 23:40 — 👍 1 🔁 0 💬 1 📌 0

Graphics Programming weekly - Issue 381 - March 2nd, 2025 www.jendrikillner.com/post/graphic...
03.03.2025 15:18 — 👍 87 🔁 24 💬 0 📌 1
helps a lot to generalize systems. Combining with ECS, I think it is a very powerful mindset for games that are heavily data-driven/have A LOT of data and interactions.
26.01.2025 16:59 — 👍 2 🔁 0 💬 0 📌 0

Why it is time to start thinking of games as databases
How do we build games that can be understood by intelligent agents? An in-depth overview of the tech that could one day make this a…
ajmmertens.medium.com/why-it-is-ti...
This resonate with me a lot, recently I am prototyping on a game that involves a lot of data-driven logic and relationships between entities, factions, resources etc... Seeing this world has a database, a flat array of entities with relationships to each other
26.01.2025 16:59 — 👍 4 🔁 0 💬 1 📌 0
21 yo... why is time accelerating ?
22.01.2025 14:40 — 👍 0 🔁 0 💬 0 📌 0
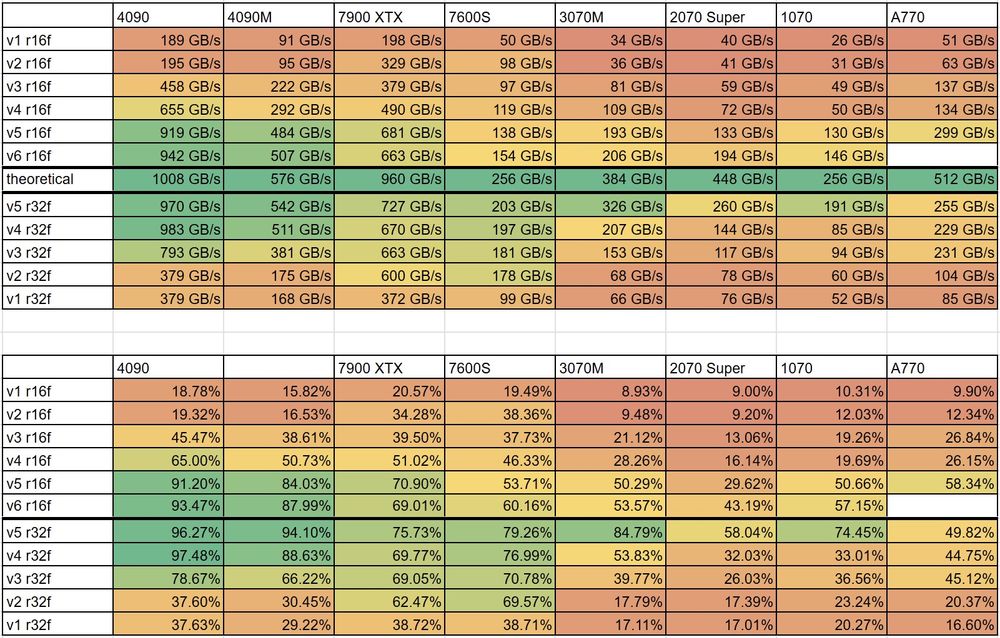
A table showing the experimental results of applying 6 different compute shader versions of a simple 3x3x3 box blur on a 512x512x512 texture using either GL_R16F or GL_R32F internal format for storage for a eight different GPUs spanning several GPU architectures and vendors.
The upper table shows the absolute effective bandwidth (measured as the sum of total bytes read and written divided by execution time), whereas the lower table shows the effective bandwidth relative to the theoretical bandwidth as a percentage.
Each row corresponds to a specific shader variant (except for the "theoretical" row, which displays the theoretical bandwidth according to the GPU specification), and each column corresponds to a specific GPU. The color coding is per column in the upper table, and it's a single color coding on the entire lower table.
Each version will be explained in detail in the subsequent posts.
Version 6 applies uses half precision floating point for the shared memory cache, and the relevant extension does not exist in the Intel drivers for Windows. Likewise this version is not applied to the GL_R32F internal format benchmarks since that would destroy the precision of the backing format anyway.
The code was written and initially tested on a desktop 4090 (the first column), which naturally skews the results a bit since everything was evaluated and tested on that GPU. Had I used another GPU I might have picked slightly different compromises, and the results would have been slightly different.
One interesting observation is that the RTX 4000 series (Ada Lovelace architecture) significantly overperform everything else, with 7900 XTX (RDNA3) slightly behind. A large part of these overwhelmingly efficient results is due to the massive caches these devices sport (72 MiB on the desktop 4090, 64 MiB on the laptop 4090, etc.), which really helps reach peak bandwidth a lot easier.
Let's wrap up this lovely week with a nice technical post
This is the "case study" from my Masterclass at GPC, where I apply a series of optimizations to improve the effective bandwidth of a 3x3x3 blur (a proxy for a huge set of operations on volumetric data)
Check ALT text for (a lot of) context.
17.11.2024 22:59 — 👍 133 🔁 24 💬 4 📌 4
Some of you may remember Itanium.
09.01.2025 16:46 — 👍 0 🔁 0 💬 1 📌 0
Graphics programming changed my PoV about CPU architectures. I want to see a more ILP/SIMD approach to software. I saw some architectures having what's called SPM (scratchpad memory) which is similar to groupshared memory. Wonder what computing would look like if we went full VLIW early.
09.01.2025 16:45 — 👍 2 🔁 0 💬 1 📌 0
The actor model is very elegant and message-passing in general always worked great for me to exchange data between threads. I would love to generalize my engine towards more actors, but I'm still skeptical about the overhead VS classical fibers/job graph with fine-grained locking (what I have).
28.12.2024 23:47 — 👍 1 🔁 0 💬 0 📌 0
oops avatar: frontiers of pandora* I mixed two different things haha
19.12.2024 04:53 — 👍 2 🔁 0 💬 0 📌 0
as rendering 30 low triangles electrical boxes. rasterizing & shading a big open forest is not comparable to rendering a city. and that's only the technical side of the problem. I hate these unfair comparaisons. it reminds me of UE Blueprints vs C++ perf videos doing 1 billion iterations. why??
19.12.2024 04:21 — 👍 3 🔁 0 💬 0 📌 0
yea so I watched again some videos of threat interactive, I agree on some of his points, but no, nanite is not a perf disaster. no serious game developer will use something without evalutating its tradeoffs with its content. rendering avatar: the last frontier is not the same
19.12.2024 04:21 — 👍 4 🔁 0 💬 3 📌 0

First look at Wakanda in 'Marvel 1943: The Rise of Hydra'
It will be a playable location
"We wanted to tell a globe-trotting story ... There are yet-to-be-revealed locations in between"
(via EW)
17.12.2024 19:47 — 👍 547 🔁 50 💬 11 📌 10
(2/2)
- Offset the AABB depth using the gradients and test, with a fallback to a conservative test for steeps gradients.
Could it work 🤔
29.11.2024 22:06 — 👍 0 🔁 0 💬 1 📌 0
(1/2)
Anyone experimented or have resources about depth gradient based occlusion culling ? I wonder how it could looks in a meshlet renderer.
This is how I see it:
- Store (or compute ?) in your hierarchical depth buffer the gradients
29.11.2024 22:06 — 👍 3 🔁 0 💬 1 📌 0
Repost if BlueSky is now your primary social media site.
28.11.2024 20:06 — 👍 22171 🔁 13247 💬 553 📌 476
The unsafe part is usable and I think can cover a big part of the library. But making it safe is quite hard since OpenUSD use a lot of mutability and shared pointers, in Rust you need somehow to attach a Mutex or RefCell to OpenUSD's smart pointers, or add an indirection. IMO too ugly.
27.11.2024 18:02 — 👍 1 🔁 0 💬 0 📌 0
Follow up on that, I started writing the safe part of the bindings and I hit several issues due to the differences between C++ and Rust, specially around mutability. So yesterday I started writing a USDA parser... let's see where this goes
27.11.2024 18:00 — 👍 2 🔁 0 💬 1 📌 0
yay I've been able to bind a small part of the OpenUSD api to Rust, only unsafe bindings for now
24.11.2024 17:28 — 👍 3 🔁 0 💬 0 📌 1
:o !!
21.11.2024 18:13 — 👍 5 🔁 0 💬 0 📌 0
France !
21.11.2024 15:41 — 👍 0 🔁 0 💬 3 📌 0
something* oops
21.11.2024 15:37 — 👍 0 🔁 0 💬 0 📌 0
Still, I'm so grateful to be able to work as a engine programmer. Truly like what I do and being paid to do it is sometime I hope everyone can experience in their life.
Time will tell if I made the right choice ;)
21.11.2024 15:37 — 👍 0 🔁 0 💬 2 📌 0
Building a new renderer at HypeHype. Former principal engineer at Unity and Ubisoft. Opinions are my own.
Setting values of 2D array, the job
Enjoy the large and lush world of Cyrodiil with updated graphics and mechanics in Skyrim's engine. #Skyblivion
🗓️ Release target: 2025
Engine Programmer @Realmforge Studios
⚙ Systems Engineer @Microids Studio Paris
🎮 Working on Amerzone - The Explorer's Legacy
Care deeply about simple & efficient code
Porting everything everywhere
Co-fondatrice des Audacieu.x.ses 🤍
My site: www.blanchemaurice.com
Working @ Epic Games Tools (RAD) on the RAD Debugger. Opinions my own.
Graphics programmer
@Ubisoft R&D on Snowdrop global illumination
Expert Shader Technical Director for That's No Moon. Working on our unannounced AAA game.
Principal Software Engineer @ Kongsberg Maritime Simulation | Unreal Engine 5, HLSL, GPGPU, Vulkan API - {C++, C#, Python}
フリーゲームや音楽やイラスト等、色々制作してます。
Kanogutiへの短い内容のご質問等は、XやBlueskyのKanogutiのアカウントのリプライ欄等にてできる限りお応えします。
僕のウェブサイトはこちら。
https://kanoguti93.neocities.org/
Game Developer, Programmer, C++, custom engines, C#, Unity. ex Warm Lamp Games, ex Alawar. Lead Programmer behind Beholder/Beholder 2.
Senior Software Engineer, Developer Relations at Epic Games.
Former Lead Programmer on #Returnal for #PS5 @Housemarque.
https://ari.games for my presentations!
Software engineer interested in graphics, distributed systems, networking, c, zig, go, asm and solving real problems.
Husband, dad of amazing girl and boy.
Professional Game Dev/Systems Programmer
Talking about the games industry, or whatever comes to mind. Opinions are my own and not reflective of any current or past employers.
he/him 24// NSFW 18+// 🇧🇷//
Patreon: http://alwaysfaceleft.com/patreon
Other social media: https://alwaysfaceleft.com/socials
Click here -> #afleft <- to see all art posts in a neat way!
Technical Game Designer at The Initiative working on Perfect Dark. Thoughts are mine and my own. Searching for a decent chopped cheese in San Francisco 🇲🇽🇺🇸
R&D Rendering Engineer - Snowdrop 3D Programmer @ Ubisoft
The painfully relatable comic about gamedev.
✨ Website ✨ http://devteamlife.com
💛 Shop 💛 http://devteamshop.com
➡️The Book➡️ https://www.studiolounak.com/lounak-shop/lounak-books


























