
7/ This was a very fun project with Ishan Amin and Sanjeev Raja, and will appear at #ICLR2025! Paper and code below:
Paper: openreview.net/forum?id=1du...
Code: github.com/ASK-Berkeley...

@ask1729.bsky.social
Assistant Professor at UC Berkeley
7/ This was a very fun project with Ishan Amin and Sanjeev Raja, and will appear at #ICLR2025! Paper and code below:
Paper: openreview.net/forum?id=1du...
Code: github.com/ASK-Berkeley...
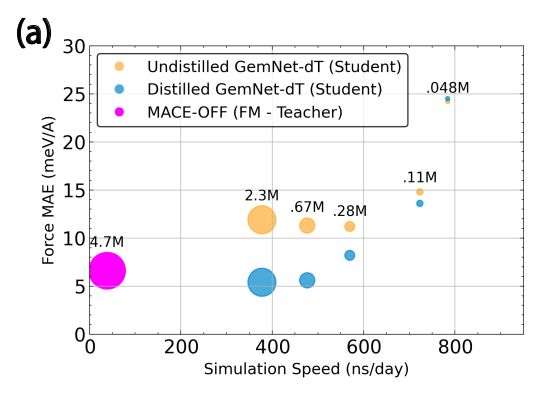
6/ The distilled MLFFs are much faster to run than the original large-scale MLFF: not everyone has the GPU resources to use big models and many scientists only care about studying specific systems (w/ the correct physics!). This is a way to get the best of all worlds!
13.03.2025 15:06 — 👍 1 🔁 0 💬 1 📌 0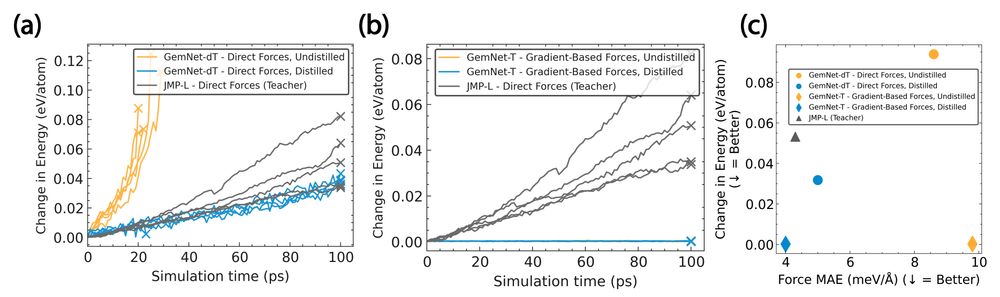
5/ We can also balance training at scale efficiently (often w/ minimal constraints) with distilling the correct physics into the small MLFF at test time: e.g., taking energy gradients to get conservative forces, and ensuring energy conservation for molecular dynamics.
13.03.2025 15:06 — 👍 0 🔁 0 💬 1 📌 0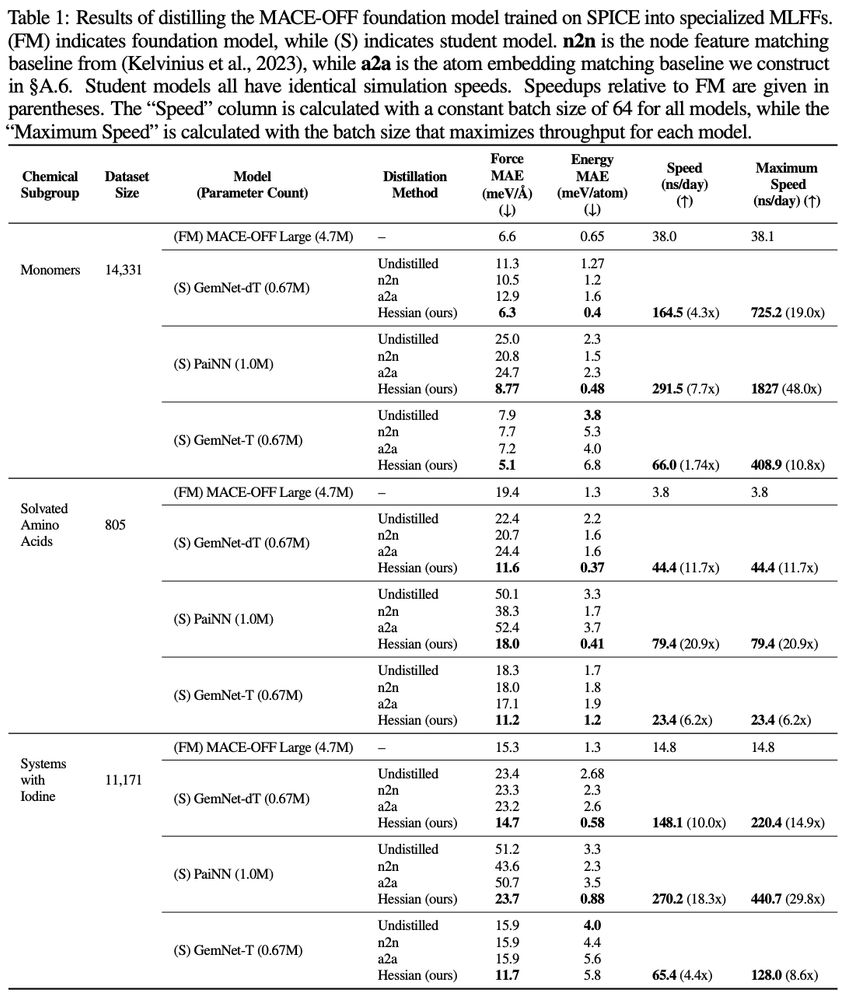
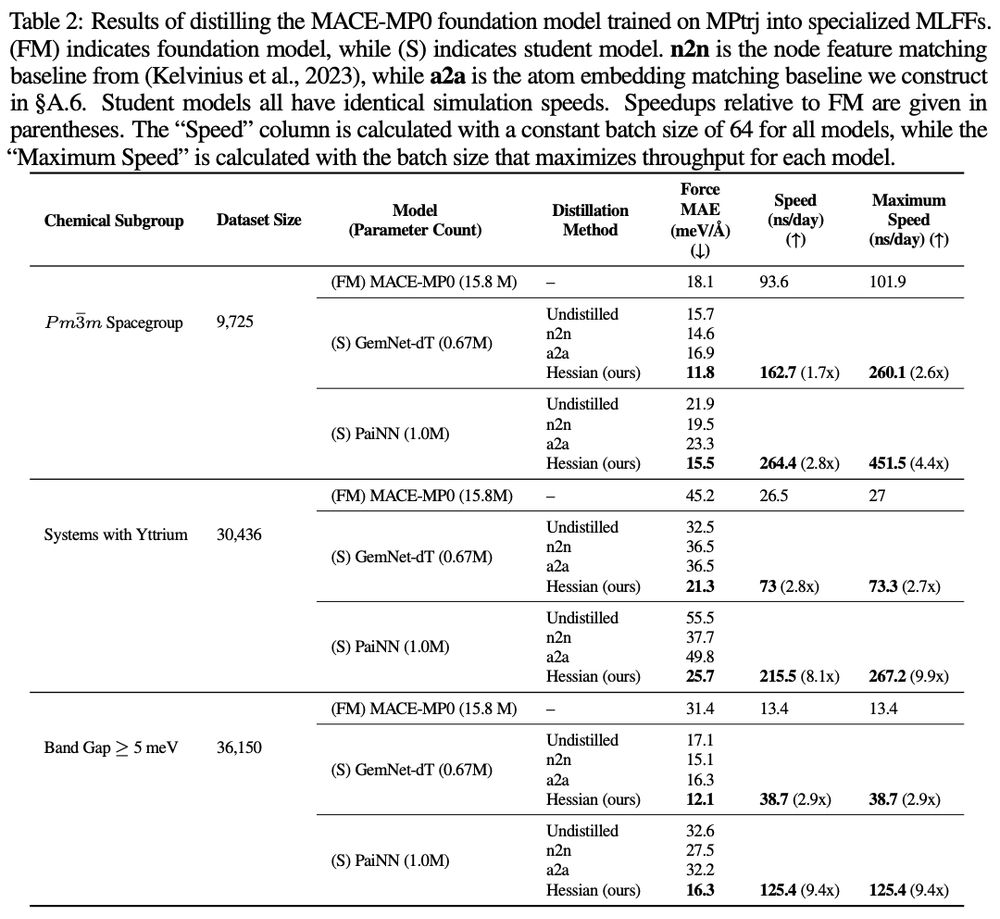
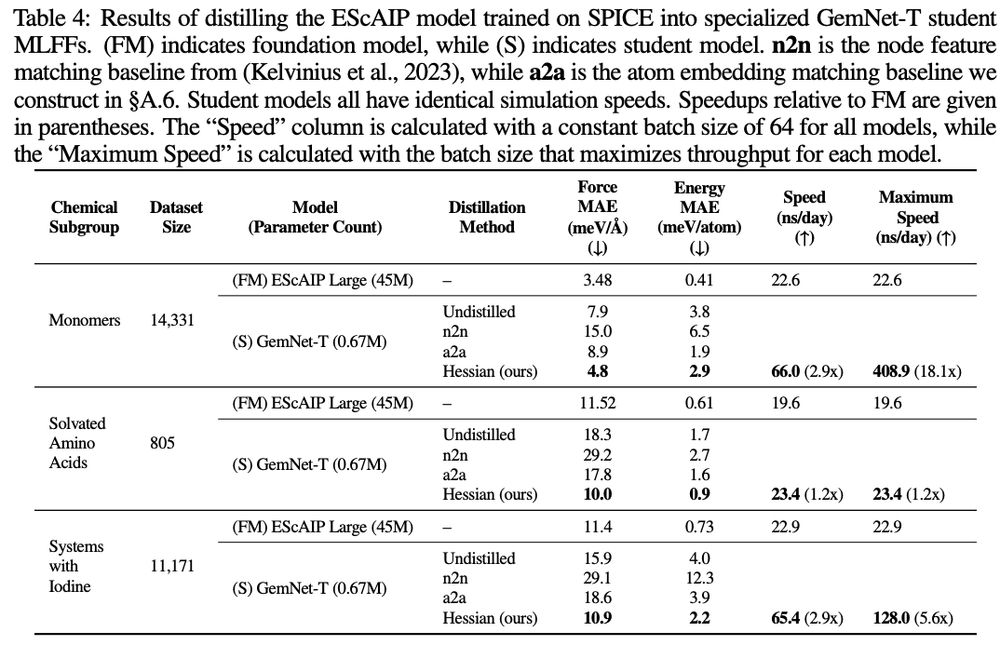
4/ Smaller, specialized MLFFs distilled from the large-scale model are more accurate than training from scratch on the same subset of data: the representations from the large-scale model help boost performance, while the smaller models are much faster to run
13.03.2025 15:06 — 👍 0 🔁 0 💬 1 📌 0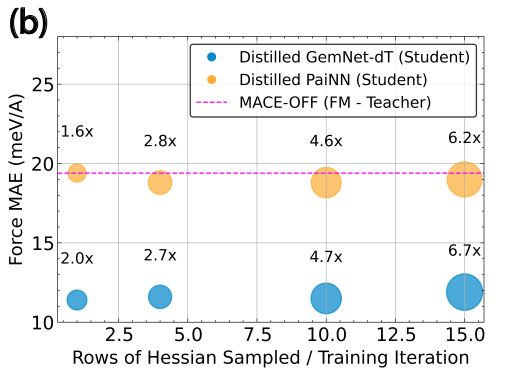
3/ We formulate our distillation procedure as the smaller MLFF is trained to match Hessians of the energy predictions of the large-scale model (using subsampling methods to improve efficiency). This works better than distillation methods to try to match features.
13.03.2025 15:06 — 👍 1 🔁 0 💬 1 📌 02/ Model distillation involves transferring the general-purpose representations learned by a large-scale model into smaller, faster models: in our case, specialized to specific regions of chemical space. We can use these faster MLFFs for a variety of downstream tasks.
13.03.2025 15:06 — 👍 1 🔁 0 💬 1 📌 0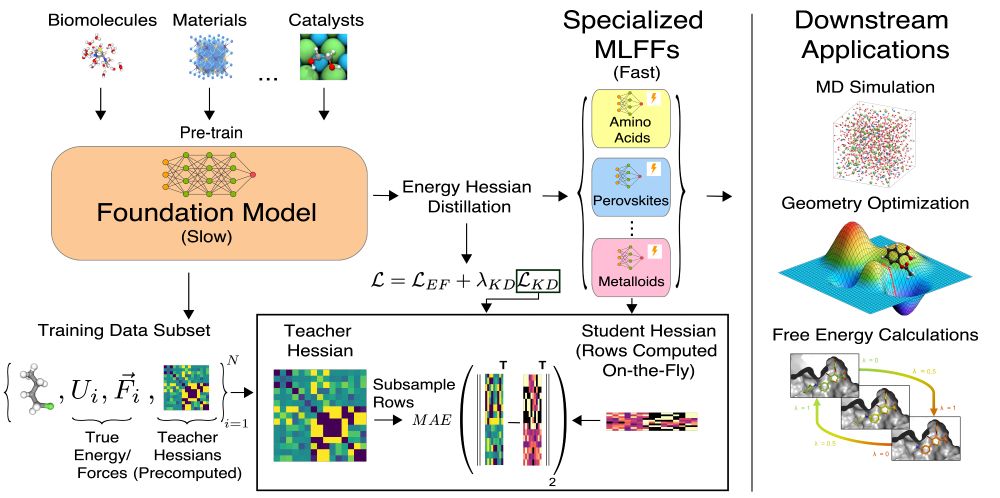
1/ Machine learning force fields are hot right now 🔥: models are getting bigger + being trained on more data. But how do we balance size, speed, and specificity? We introduce a method for doing model distillation on large-scale MLFFs into fast, specialized MLFFs! More details below:
#ICLR2025
😃
16.11.2024 16:47 — 👍 2 🔁 0 💬 0 📌 0Would also appreciate being added, thanks!
16.11.2024 16:46 — 👍 2 🔁 0 💬 1 📌 0


















