SWE-bench Leaderboards
Full leaderboard ("bash only"): www.swebench.com (about to be updated)
19.11.2025 15:36 — 👍 0 🔁 0 💬 1 📌 0
Docent
AI-powered evaluation framework
You can browse all agent trajectories/logs in the webbrowser here: docent.transluce.org/dashboard/36...
19.11.2025 15:36 — 👍 0 🔁 0 💬 1 📌 0

By varying the maximum steps you allow your agent, you can trade resolution rate vs cost. Gemini 3 is more cost-efficient than Sonnet 4.5, but much less than gpt-5 (or gpt-5-mini)
19.11.2025 15:36 — 👍 0 🔁 0 💬 1 📌 0

Gemini takes exceptionally many steps to iterate on a task, more than even Sonnet 4.5, only flattening at > 100 steps. Median steps (50ish) also very high.
19.11.2025 15:36 — 👍 0 🔁 0 💬 1 📌 0

Gemini 3 Pro sets new record on SWE-bench verified: 74%! (evaluated with minimal agent) Costs are 1.6x of GPT-5, but still cheaper than Sonnet 4.5. Gemini iterates longer than everyone; run your agent with a step limit of >100 for max performance. Details & full agent logs in 🧵
19.11.2025 15:36 — 👍 0 🔁 0 💬 1 📌 0
Docent
AI-powered evaluation framework
You can find all of the trajectories here: klieret.short.gy/mini-traject...
30.09.2025 14:49 — 👍 0 🔁 0 💬 1 📌 0

By varying the agent step limit, you can get some control over the cost, giving you a curve of average cost vs SWE-bench score. But clearly it's quite expensive even with conservative limits.
30.09.2025 14:49 — 👍 0 🔁 0 💬 1 📌 0

Sonnet 4.5 takes significantly more steps to solve instances than Sonnet 4, making it more expensive to run in practice
30.09.2025 14:49 — 👍 0 🔁 0 💬 1 📌 0

We evaluated Anthropic's Sonnet 4.5 with our minimal agent. New record on SWE-bench verified: 70.6%! Same price/token as Sonnet 4, but takes more steps, ending up being more expensive. Cost analysis details & link to full trajectories in 🧵
30.09.2025 14:49 — 👍 0 🔁 0 💬 1 📌 0

Massively Parallel Agentic Simulations with Ray | Anyscale
Powered by Ray, Anyscale empowers AI builders to run and scale all ML and AI workloads on any cloud and on-prem.
Very cool to see anyscale use mini-swe-agent in their large scale agent runs " because it is extremely simple and hackable and also gives good performance on software engineering problems without extra complexity" www.anyscale.com/blog/massive...
11.09.2025 03:05 — 👍 1 🔁 0 💬 1 📌 0
SWE-bench Leaderboards
You can find lots of other models evaluated under the same settings at swebench.com (bash-only leaderboard). You can find our agent implementation at github.com/SWE-agent/mi...
21.08.2025 22:34 — 👍 0 🔁 0 💬 0 📌 0
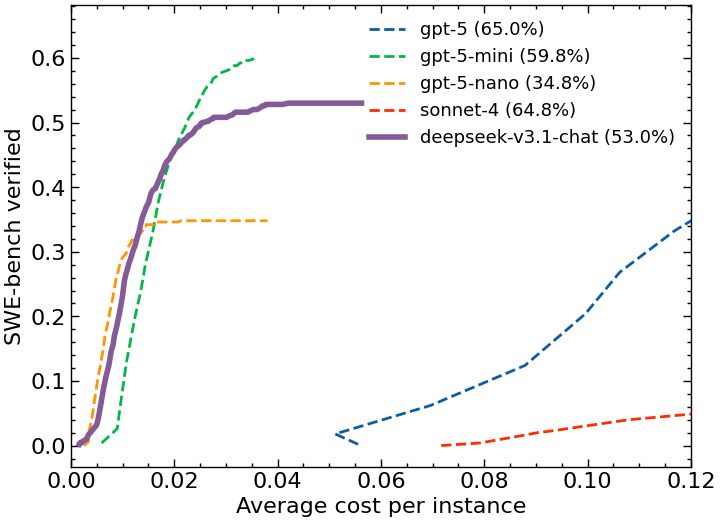
The effective cost per instance comes somewhat close to gpt-5-mini. Will have more thorough comparison soon.
21.08.2025 22:34 — 👍 0 🔁 0 💬 1 📌 0
Evaluating on the 500 SWE-bench verified instances cost around $18. With respect to the steps taken to solve a problem, deepseek v3.1 chat maxes out later than other models
21.08.2025 22:34 — 👍 0 🔁 0 💬 1 📌 0

Deepseek v3.1 chat scores 53.8% on SWE-bench verified with mini-SWE-agent. Tends to take more steps to solve problems than others (flattens out after some 125 steps). As a result effective cost is somewhere near GPT-5 mini. Details in 🧵
21.08.2025 22:34 — 👍 0 🔁 0 💬 1 📌 0

What if your agent uses a different LM at every turn? We let mini-SWE-agent randomly switch between GPT-5 and Sonnet 4 and it scored higher on SWE-bench than with either model separately. Read more in the SWE-bench blog 🧵
20.08.2025 18:02 — 👍 0 🔁 0 💬 1 📌 0
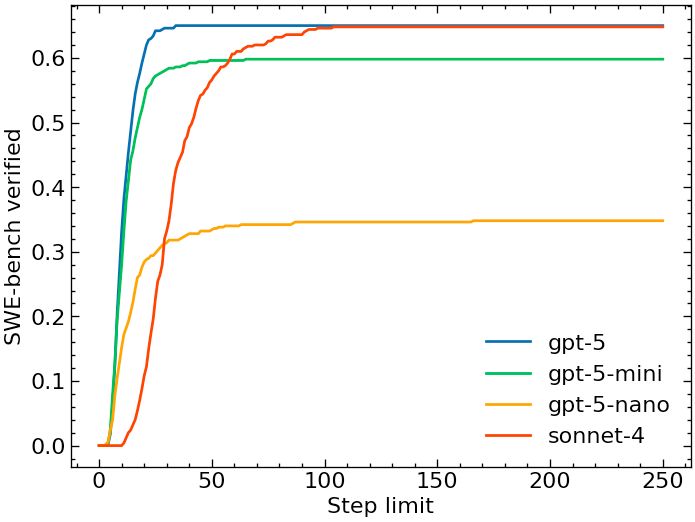
GPT-5-* is also much faster at getting to its peak, so definitely don't let it run longer than 50 steps for cost efficiency.
08.08.2025 15:20 — 👍 1 🔁 0 💬 1 📌 0

Agents succeed fast, but fail slowly, so the average cost per instance depends on the step limits. But one thing is clear: GPT-5 is cheaper than Sonnet 4, and GPT-5 mini is incredibly cost efficient!
08.08.2025 15:20 — 👍 0 🔁 0 💬 1 📌 0
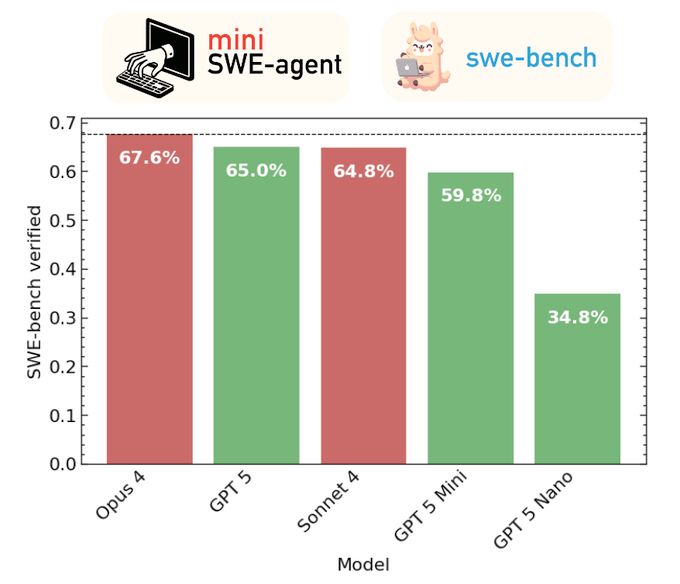
SWE-bench scores (same as text)
We evaluated the new GPT models with a minimal agent on SWE-bench verified. GPT-5 scores 65%, mini 60%, nano 35%. Still behind Opus 5 (68%), on par with Sonnet 4 (65%). But a lot cheaper, especially mini! Complete cost breakdown + details in 🧵
08.08.2025 15:20 — 👍 0 🔁 1 💬 1 📌 0
gpt-5-mini delivers software engineering for very cheap! We're seeing 60% on SWE-bench verified with just $18 total using our bare-bones 100 line agent. That's for solving 299/500 GitHub issues! Very fast, too! (1.5h total with 10 workers)
08.08.2025 04:13 — 👍 0 🔁 0 💬 1 📌 0
We also made some adjustments to our prompt, in particular the following line: "This workflows should be done step-by-step so that you can iterate on your changes and any possible problems." Without it, gpt-5 often tries to solve everything in one step, then quits.
07.08.2025 21:22 — 👍 0 🔁 0 💬 1 📌 0
Quick start - mini-SWE-agent documentation
Guide to running with gpt-5: mini-swe-agent.com/latest/quick... The extra step is necessary because gpt-5 prices aren't registered in litellm yet. Also expect long run times (the 5 steps above took more than 5 minutes).
07.08.2025 21:22 — 👍 0 🔁 0 💬 1 📌 0
Research Scientist at Meta • ex Cohere, Google DeepMind • https://www.ruder.io/
Assistant Professor @Mila-Quebec.bsky.social
Co-Director @McGill-NLP.bsky.social
Researcher @ServiceNow.bsky.social
Alumni: @StanfordNLP.bsky.social, EdinburghNLP
Natural Language Processor #NLProc
Professor of Natural and Artificial Intelligence @Stanford. Safety and alignment @GoogleDeepMind.
Cofounder CEO, Perplexity.ai
Research Scientist at FAIR, Meta. 💬 My opinions are my own.
Software and AI Engineer
I write at danielcorin.com
Author of Tomo, an ambient chat app and Delta, an open source tool for conversation branching with LLMs
https://www.wvlen.llc/apps/tomo
https://github.com/danielcorin/delta
Distinguished Scientist at Google. Computational Imaging, Machine Learning, and Vision. Posts are personal opinions. May change or disappear over time.
http://milanfar.org
research scientist at google deepmind.
phd in neural nonsense from stanford.
poolio.github.io
prev: @BrownUniversity, @uwcse/@uw_wail phd, ex-@cruise, RS @waymo. 0.1x engineer, 10x friend.
spondyloarthritis, cars ruin cities, open source
I work on AI at OpenAI.
Former VP AI and Distinguished Scientist at Microsoft.
Compute @ Anthropic | Formerly AI strategy @ Google and tech equity research @ Bernstein Research
Gemini Thinking @ Google DeepMind. Previously @ Google Brain. Previously @ DeepMind. Intelligent Agents
I do SciML + open source!
🧪 ML+proteins @ http://Cradle.bio
📚 Neural ODEs: http://arxiv.org/abs/2202.02435
🤖 JAX ecosystem: http://github.com/patrick-kidger
🧑💻 Prev. Google, Oxford
📍 Zürich, Switzerland
Researcher at Meta, working on radiance fields and view-synthesis. Pixels in, pixels out!
I develop tough benchmarks for LMs and then I build agents to try and beat those benchmarks. Postdoc @ Princeton University.
https://ofir.io/about
official Bluesky account (check username👆)
Bugs, feature requests, feedback: support@bsky.app
























