Original post on sigmoid.social
The image is in this article: https://nos.nl/artikel/2578327-discriminatie-nl-en-moslimorganisaties-doen-aangifte-tegen-wilders-om-tweet
Second, if the case ends up revolving around the intent behind the image, we may see the first time a prompt is used to establish that.
I just hope the […]
11.08.2025 16:48 — 👍 0 🔁 0 💬 0 📌 0
Original post on sigmoid.social
Geert Wilders posted an islamophic image in a tweet a few days ago and is now being sued for it.
The thing is, the image is clearly AI generated. This means that the prompt for it is still around somewhere.
Under US discovery, that prompt would certainly be made public; possibly in the Dutch […]
11.08.2025 16:46 — 👍 0 🔁 1 💬 1 📌 0
Original post on cyberplace.social
There’s an eye opening article in FT quoting Morgan Stanley about the size of the generative AI bubble developing.
https://www.ft.com/content/7052c560-4f31-4f45-bed0-cbc84453b3ce
“Hyperscaler funding of $300bn to $400bn a year compares with annual capex last year for all S&P 500 companies of […]
06.08.2025 14:18 — 👍 13 🔁 2 💬 0 📌 0
Original post on sigmoid.social
Making avatars of dead people without their consent is obscene. It was obscene when people did it before GenAI, and it's still obscene now that it's been made easier, cheaper and and more unsettling by a less suitable technology […]
05.08.2025 07:10 — 👍 0 🔁 0 💬 0 📌 0
Original post on sigmoid.social
It feels like booking.com is in it's last-days-of-rome phase and all the competitors can do is copy its mistakes.
If somebody made a simple-well-functioning search engine for hotels without a profit motive, most people would switch in a second, and the hotels would ditch booking.com without a […]
04.08.2025 07:45 — 👍 0 🔁 0 💬 0 📌 0
Original post on mastodon.nl
Je hebt van die wetten waar je nooit van hoort als je er niet mee te maken hebt.
De "Wet op de strandvonderij" is daarvan een mooi voorbeeld dat ik tegen kwam in een stuk in de @DeGroene over strandjutten.
https://www.groene.nl/artikel/een-kippenhok-met-een-patrijspoort […]
04.08.2025 07:08 — 👍 1 🔁 1 💬 1 📌 0
I like the idea of spring systems as metaphor-explanations for complex algorithms. We have good intuitions for some physical systems that allow us to grasp their behavior naturally.
I came up with one for EM/k-means a few years back https://mlvu.github.io/lecture08/#video-069
03.08.2025 10:10 — 👍 1 🔁 0 💬 0 📌 0
#til about Braess' paradox. The idea that adding roads to a traffic network can make it less efficient.
It has an interesting physical analogue in a weight hanging from a system of springs and wires. Cutting one of the wires lifts the weight.
https://www.youtube.com/watch?v=nMrYlspifuo
03.08.2025 10:07 — 👍 0 🔁 0 💬 1 📌 0
GitHub - dkamm/pr-quiz: A GitHub Action that uses AI to generate a quiz from your pull request
A GitHub Action that uses AI to generate a quiz from your pull request - dkamm/pr-quiz
AI generated github quizzes to validate pull requests. https://github.com/dkamm/pr-quiz
It's a clever idea, but I have a horrible sinking feeling that in two years we're going to be living in an Escher-like maze of Captchas and counter-captchas and infinite recursions of AI based arms races.
29.07.2025 18:44 — 👍 0 🔁 0 💬 0 📌 0
Original post on sigmoid.social
There aren't many worldviews that do and agree with the pretraining data, which is mostly Wikipedia, non-fiction books, stackexchange and academic articles. I.e. secular, academic consensus-reality.
Not that academics have an entirely coherent worldview, but there's method commitment to truth […]
29.07.2025 18:35 — 👍 0 🔁 0 💬 0 📌 0
Original post on sigmoid.social
I can't imagine OpenAI is going to Trumpify GPT. I'm pretty sure they've spent more on instruction tuning than they have on model training.
Even if they wanted to throw all that out and start again, you'd need to build a coherent image of what the bot should do in any given situation. The MAGA […]
29.07.2025 18:32 — 👍 0 🔁 0 💬 1 📌 0
@timkellogg.me This feels like our LK-99...
27.07.2025 16:25 — 👍 2 🔁 0 💬 1 📌 0
@timkellogg.me This seems mad... 27M params and no inductive bias for grids. In 1K examples, it figures the grid structure out first, and then the manifold different problem styles in ARC?
27.07.2025 16:14 — 👍 1 🔁 0 💬 2 📌 0
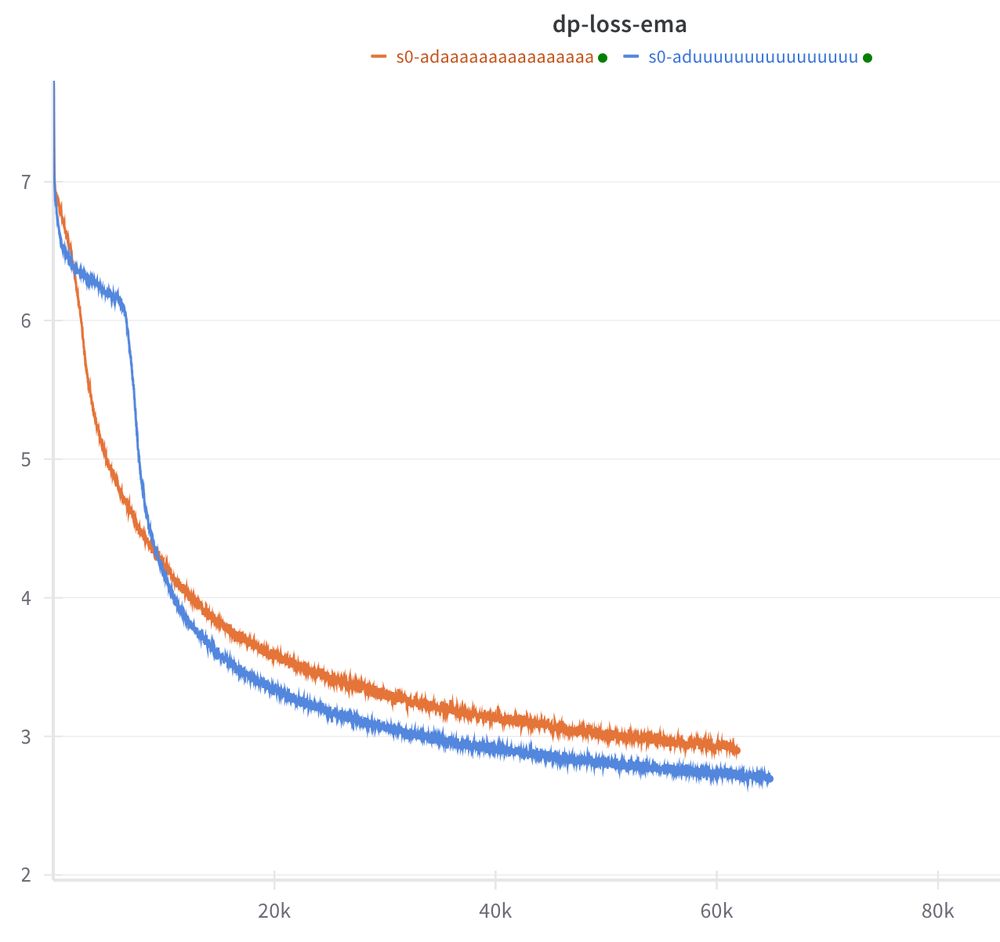
Two loss curves from a transformer training experiment. One, in blue, has a slight bump and a quick drop. The other, in orange, drops more directly, but ends up about 0.2 nats above the blue one.
Here's an odd effect (stumbled on by accident). The blue loss curve is from a well-tuned BERT baseline (from the "cramming"paper).
The only thing I changed for the orange is to put a residual connection around each transformer block and to multiplier the […]
[Original post on sigmoid.social]
27.07.2025 15:10 — 👍 1 🔁 0 💬 0 📌 0
I think most people on the left would be more than happy for Clinton to be pushed under the Epstein bus along with Trump.
25.07.2025 18:23 — 👍 0 🔁 0 💬 0 📌 0
I'm centrists on lots of AI, but self-driving cars cannot be made to work with current technology and anybody who says they can is deluded and frankly an idiot.
I trust modern AI to help me with literature research, not to accelerate 2 metric tons of steel to 100 kph.
24.07.2025 14:44 — 👍 1 🔁 0 💬 1 📌 0
![Musk told investors that he expected the company's sales in Europe to increase once customers there are allowed to use the firm's self-driving software.
He said he expected the first approval to come in the Netherlands but that the firm also hoped to win sign-off from the European Union, despite it having a "kafkaesque" bureaucracy.
"Autonomy is the story," Musk said. "Autonomy is what amplifies the value [of the company] to stratospheric levels."](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:tg2ausiezysjhmoo2hynz7d2/bafkreidtqgzpl4cmt22w4ddapvfcsf5gnoimyv4p6nhcjne6wmdyv4j3mu@jpeg)
Musk told investors that he expected the company's sales in Europe to increase once customers there are allowed to use the firm's self-driving software.
He said he expected the first approval to come in the Netherlands but that the firm also hoped to win sign-off from the European Union, despite it having a "kafkaesque" bureaucracy.
"Autonomy is the story," Musk said. "Autonomy is what amplifies the value [of the company] to stratospheric levels."
Oh, come on...
Can we please not make our cyclist-ridden country full of strange and untypical streets the testing ground for a manchild's misguided attempts at creating a technology he doesn't understand with a vast societal risk he doesn't respect.
24.07.2025 14:41 — 👍 0 🔁 0 💬 1 📌 0

🍇Happy to share GRAPES 🍇
Make GNNs work on large graphs by learning an expressive and adaptive sampler 🚀
Excellent work led by Taraneh Younesian now in TMLR!
openreview.net/forum?id=QI0...
23.07.2025 11:36 — 👍 13 🔁 4 💬 0 📌 0

Black-and-white photo of The Beatles in the early 60s.

Photo of Mötley Crüe in the 80s
We need an article about the phenomenon where a social controversy—eg about “long-haired male rock stars”—maintains constant intensity, while the actual boundary is moving so fast that the original provocation is normative 10 years later.
Something like this is happening with machine learning. +
04.06.2025 12:08 — 👍 50 🔁 11 💬 1 📌 0
A link for the vibe coders in your life: https://en.wikipedia.org/wiki/Automation_bias#Automation-induced_complacency
21.07.2025 08:45 — 👍 0 🔁 0 💬 0 📌 0
Original post on sigmoid.social
I wonder if this is some property of most processes so far, that things either fail 1 in 10 or 1 in 1000, but rarely if ever in between.
It's probably a selection thing, where usually we don't allow anything with that kind of failure rate into the world, but somehow rolling AI out into […]
20.07.2025 16:02 — 👍 0 🔁 0 💬 1 📌 0
Original post on sigmoid.social
The proportion of times that LLMs suddenly fail at something they've done well before seems tailor-made to screw up human reasoning about reliability. If it was 1 in 10 we would know, and be reminded often, to babysit them permanently.
If it was 1 in 1000, we'd rely on them with occasional […]
20.07.2025 15:59 — 👍 1 🔁 0 💬 1 📌 0
@zachweinersmith.bsky.social
I think detective stories have this vibe occasionally. Probably starting with the Hound of the Baskervilles. Jonathan Creek did this pretty much every episode.
20.07.2025 10:31 — 👍 0 🔁 0 💬 0 📌 0
You would think that by now, Trump would have learned about the process of discovery in court cases and how much stuff gets made public in that process.
19.07.2025 23:35 — 👍 1 🔁 0 💬 0 📌 0
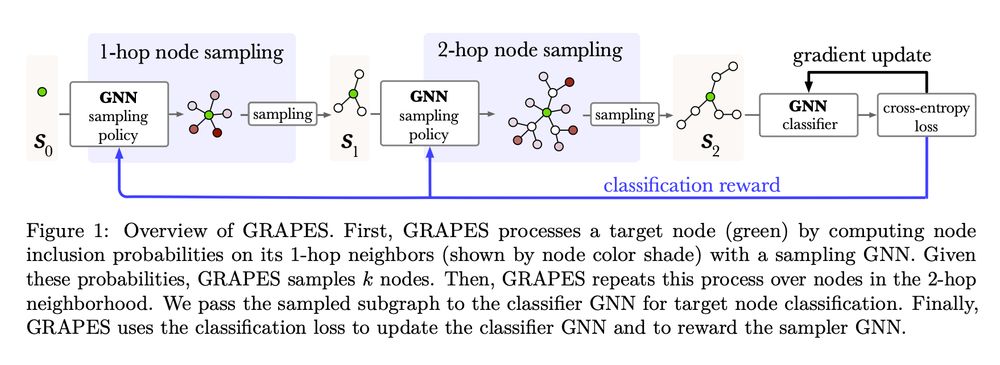
A diagram of the GRAPES pipeline. It shows a subgraph being sampled in two steps and being fed to a GNN, with a blue line showing the learning signal. The caption reads Figure 1: Overview of GRAPES. First, GRAPES processes a target node (green) by computing node inclusion probabilities on its 1-hop neighbors (shown by node color shade) with a sampling GNN. Given these probabilities, GRAPES samples k nodes. Then, GRAPES repeats this process over nodes in the 2-hop neighborhood. We pass the sampled subgraph to the classifier GNN for target node classification. Finally, GRAPES uses the classification loss to update the classifier GNN and to reward the sampler GNN.
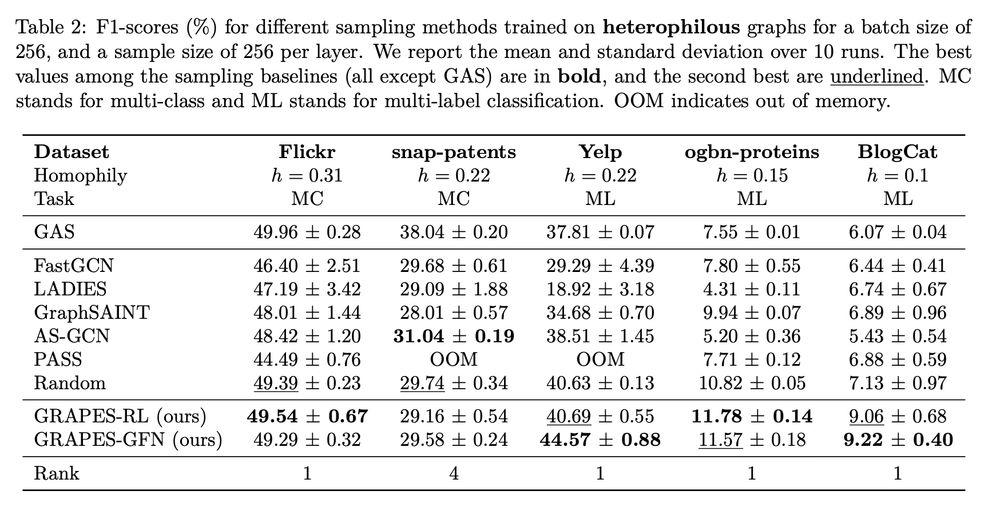
A results table for node classification on heterophilious graphs. Table 2: F1-scores (%) for different sampling methods trained on heterophilous graphs for a batch size of 256, and a sample size of 256 per layer. We report the mean and standard deviation over 10 runs. The best values among the sampling baselines (all except GAS) are in bold, and the second best are underlined. MC stands for multi-class and ML stands for multi-label classification. OOM indicates out of memory.
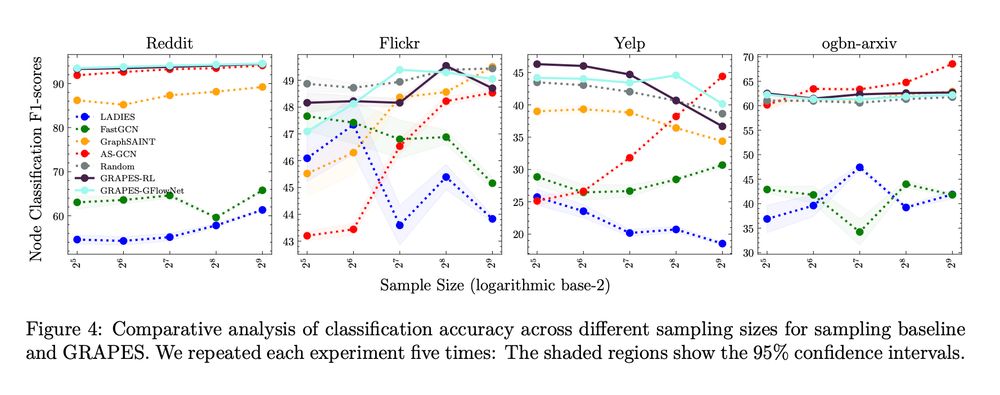
Performance of samples vs sampling size showing that GRAPES generally performs well across sample sizes, while other samplers often show more variance across sample sizes. The caption reads Figure 4: Comparative analysis of classification accuracy across different sampling sizes for sampling baseline
and GRAPES. We repeated each experiment five times: The shaded regions show the 95% confidence intervals.
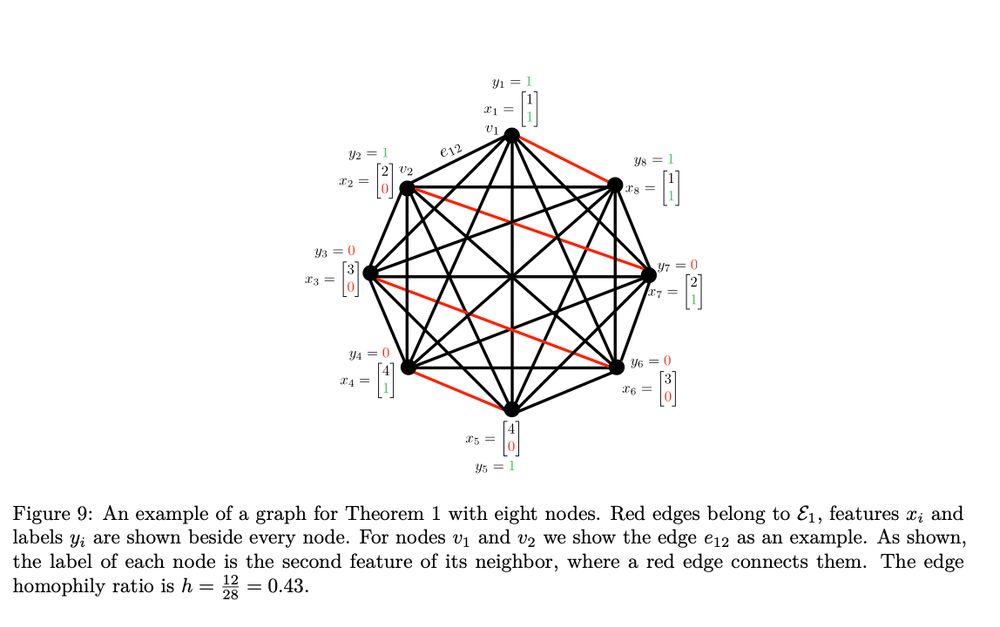
A diagrammatic illustration of a graph classification task used in one of the theorems. The caption reads Figure 9: An example of a graph for Theorem 1 with eight nodes. Red edges belong to E1, features xi and labels yi are shown beside every node. For nodes v1 and v2 we show the edge e12 as an example. As shown, the label of each node is the second feature of its neighbor, where a red edge connects them. The edge homophily ratio is h=12/28 = 0.43.
Now out in# TMLR:
🍇 GRAPES: Learning to Sample Graphs for Scalable Graph Neural Networks 🍇
There's lots of work on sampling subgraphs for GNNs, but relatively little on making this sampling process _adaptive_. That is, learning to select the data from the […]
[Original post on sigmoid.social]
18.07.2025 09:25 — 👍 2 🔁 0 💬 0 📌 0
Original post on sigmoid.social
It feels like Trump is running into the inherent problems of international diplomacy among a world order of autocrats.
He tells Putin to stop bombing Ukraine, Putin says yes and does no. He tells Netanyahu to stop attacking Syria, Netanyahu says yes and does no.
Their nature as autocrats is […]
16.07.2025 15:27 — 👍 0 🔁 0 💬 0 📌 0
@tedunderwood.me True, but the people making AI don't seem to me to be overly worried about crossing that threshold.
I bet Zuckerberg would give his kidney for the chance to be the first to a fully enslaved real consciousness.
12.07.2025 17:32 — 👍 1 🔁 0 💬 0 📌 0
Post-doc @ VU Amsterdam, prev University of Edinburgh.
Neurosymbolic Machine Learning, Generative Models, commonsense reasoning
https://www.emilevankrieken.com/
PhD candidate CLTL VU Amsterdam
Prev. Research Intern Huawei
stefanfs.me
NOT SPAM. But I was reported and nothing I can do. So this account will be inactive: find me on LinkedIn, the only platform working well.
At least the bots can flourish here. Sigh.
Director General/
Natural Resources Canada
Philosophy lover. Husband, father. Computer scientist. 🇳🇿
I'm mainly active at Mastodon as @BenjaminHan@sigmoid.social but you can interact with my bridged account here at @BenjaminHan.sigmoid.social.ap.brid.gy .
socialist. federalist. supports democratic socialism, universal healthcare & universal basic income. he/him. pro-choice. pro-democracy. anti-war. anti-racist. anti-authoritarian. LGBTQ+ ally. PNW(WA), tech junkie, casual gamer, policy nerd, twitter refugee
(she/her) Full Professor of Explainable AI, University of Maastricht, NL. Lab director of the lab on trustworthy AI in Media (TAIM). Director of Research at the Department of Advanced Computing Sciences. IPN board member (incoming 2026). navatintarev.com
Professor of Ethics & Technology @ Hertie School, Berlin. Interests: Artificial & Natural Intelligence; Behavioural Ecology; Cooperation; Digital Governance. Social media policy: https://joanna-bryson.blogspot.com/2024/10/guidance-to-my-social-media.html
Taiwan-based anthropologist.
人類學家與台灣新住民。
https://kerim.one
My Triptych newsletter:
https://triptych.oxus.net/
Computational Neuroimaging Researcher based in Amsterdam
Doing Bayesian stuff in #rustlang and #julialang. Seattle
Software engineer 🖥️ |
Former neuroscientist 🧪🧠🐭 |
Southerner pretending to be a Geordie |
Blog: https://arun-niranjan.github.io/
Student Researcher @ Google
MSc CS @ ETH Zurich (@ethzurich.bsky.social)
Visual computing, 3D computer vision, Spatial AI, ML, and robotics perception.
📍Zurich, Switzerland
MS AI @ VU Amsterdam - Interested in Geometrical Deep Learning | Topological Deep Learning | Graphs
Chief Clinical Informatics @ BIDMC & Faculty Harvard Medical School, Chief of @DCINetwork.org #MedicalInformatics #AI #DigitalHealth #MobileHealth #LearningHealthSystems
https://www.LinkedIn.com/in/yuriquintana
http://www.yuriquintana.com
I like databases and boats. Co-creator of @duckdb.org, Co-Founder and CEO DuckDB Labs. Professor of Data Engineering at Radboud Universiteit.
Assistant Professor in AI (Information Retrieval and NLP) at ILLC, @uva.nl & ICAI @opengov.nl Lab Manager | PhD from @irlab-amsterdam.bsky.social | Treasurer @setuputrecht.bsky.social | Commissie Persoonsgegevens Amsterdam | https://www.graus.nu