
Andalucía anuncia JuntaGPT: la IA llega a la administración pública de la mano de Google y Gemma 3
Blog sobre informática, tecnología y seguridad con manuales, tutoriales y documentación sobre herramientas y programas
La Junta de Andalucía ha lanzado un chatbot con RAG, precargado con documentación de la administración, para uso interno de los funcionarios públicos.
Está basado en Gemma-3-27B y se ejecuta en la nube privada de la administración, en el supercomputador Hércules.
17.06.2025 19:33 — 👍 3 🔁 1 💬 1 📌 1
Qwen3 está muy bien, pero es DEMASIADO verboso para usarlo como agente, 10 minutos escupiendo a 90 tokens/s y no acaba.
06.06.2025 08:29 — 👍 0 🔁 0 💬 0 📌 0

Los modelos saben cuando están siendo evaluados, lo cual implica que las evaluaciones de seguridad podrían no ser efectivas.
Podrían 'finjir' estar correctamente alineados, porque es lo que se espera de ellos.
05.06.2025 22:57 — 👍 1 🔁 1 💬 0 📌 0
Por último, ya que estamos, Qwen-3 ha sido bastante decepcionante en general, pero el modelo 30B-A3 es muy interesante por su rapidez, da gusto verlo escupir tokens.
19.05.2025 20:02 — 👍 0 🔁 0 💬 0 📌 0
Mistral-Small-3.1 en cambio ha sido una decepción tras usarlo más en profundidad. Es un modelo muy rígido, bueno para seguir instrucciones, similar en ese aspecto a Llama-3, pero sin ninguna 'chispa'.
19.05.2025 19:59 — 👍 0 🔁 0 💬 0 📌 0
Mi decepción inicial se basaba en algunos casos concretos de seguimiendo de instrucciones y formato, en los que Llama-3 sobresalía, pero gemma es un modelo mucho más versátil y 'avispado'.
Especialmente, su habilidad para usar herramientas lo hace muy interesante para algunos casos.
19.05.2025 19:57 — 👍 0 🔁 0 💬 0 📌 0
Reactivo esta cuenta después de mucho tiempo para desdecirme de mi último post (ya borrado): Gemma-3 es de hecho un muy buen modelo, de lo mejor en sus respectivas categorías como modelo de propósito general.
19.05.2025 19:57 — 👍 0 🔁 0 💬 1 📌 0
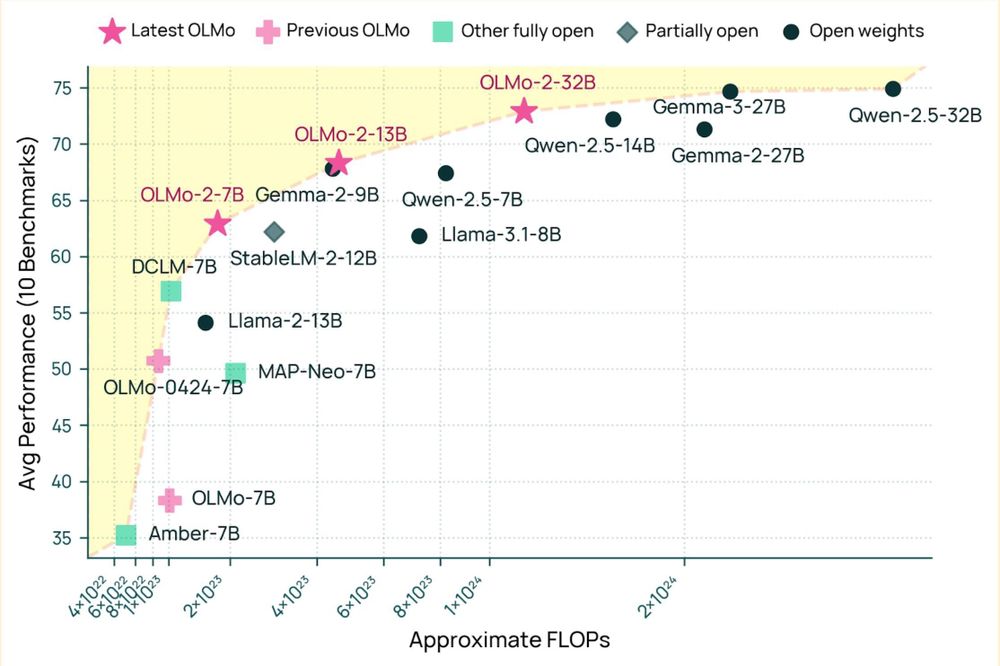
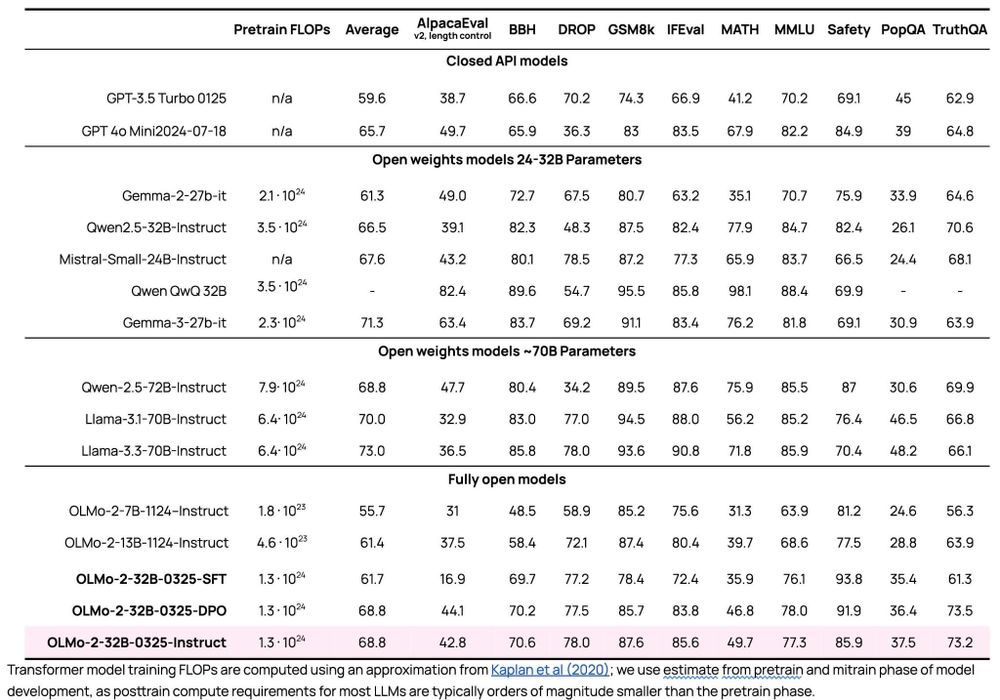
A very exciting day for open-source AI! We're releasing our biggest open source model yet -- OLMo 2 32B -- and it beats the latest GPT 3.5, GPT 4o mini, and leading open weight models like Qwen and Mistral. As usual, all data, weights, code, etc. are available.
13.03.2025 18:16 — 👍 141 🔁 37 💬 5 📌 3
How can robots reliably place objects in diverse real-world tasks?
🤖🔍 Placement is hard! - objects vary in shape & placement modes (such as stacking, hanging, insertion)
AnyPlace predicts placement poses of unseen objects in real-world with ony using synthetic training data!
Read on👇
24.02.2025 22:11 — 👍 10 🔁 4 💬 1 📌 1
Además, las preguntas con opciones de 'todas' o 'ninguna' también son mucho más difíciles para los humanos, por motivos similares.
20.02.2025 18:29 — 👍 0 🔁 0 💬 0 📌 0
Este es un comportamiento esperable dado como funcionan los modelos, por una suerte de asociación entre palabras. Es más fácil asociar el enunciado a su solución que a 'ninguna', un concepto completamente genérico.
20.02.2025 18:29 — 👍 0 🔁 0 💬 1 📌 0
Tal como señalan en las conclusiones, esto indicaría que los modelos dependen de la memorización, más que del razonamiento o en la comprensión.
20.02.2025 18:29 — 👍 0 🔁 0 💬 1 📌 0
El paper:
20.02.2025 18:15 — 👍 0 🔁 0 💬 1 📌 0

También, como se ve en el gráfico, los han evaluado en el MMLU traducido al español.
Llama la atención que en el examen de la UNED sacan mejor nota en español (el original)
Eso podría indicar que las diferencias entre idiomas se deben a contaminación (como apuntan) o problemas de traducción.
20.02.2025 18:15 — 👍 0 🔁 0 💬 1 📌 0

Un grupo de investigadores de la @uneduniv.bsky.social ha evaluado varios modelos en el clásico benchmark MMLU y en un examen de la UNED (nunca publicado), pero cambiando la respuesta correcta por "ninguna de las anteriores" (noto)
Los resultados caen drásticamente en todos los casos!
20.02.2025 18:15 — 👍 0 🔁 1 💬 1 📌 1

I'm very happy to announce a strategic partnership between @wikimediafoundation.org enterprise and Pleias for open, ethical and trustworthy AI innovation. enterprise.wikimedia.com/blog/pleias-...
18.02.2025 16:16 — 👍 52 🔁 19 💬 1 📌 1

We're looking for testers for our closed Beta before launching on the Google Play Store! 🚀
If you're interested in manage your followers and unfollows, send us a DM with your Gmail address, and we'll send you the instructions to join and download the app
(Android only for now!)
13.02.2025 22:08 — 👍 1 🔁 1 💬 0 📌 1
hahaha I love that. I have used R1 (web version) quite few times but I never found so "sparky" responses. It is a very good model for sure, I like it, but I still find Sonnet much more useful and fun to talk with.
14.02.2025 17:23 — 👍 0 🔁 0 💬 0 📌 0
btw, is it Sonnet? Opus? or maybe Haiku? (as they are comparing to o3-mini)
14.02.2025 16:57 — 👍 0 🔁 0 💬 0 📌 0
I'm still not confident what the future of "reasoning" on LLMs is because, while they have shown impressive capabilities on some tasks, they still feel weird and lacking of "spark". No one has truly beaten Sonnet 3.5 yet despite months of hard efforts.
I hope Claude 4 will clarify this soon.
14.02.2025 16:57 — 👍 0 🔁 0 💬 2 📌 0
Depending on the case, I tried R1 7-8B distills and they were disappointing. 32B is good though
14.02.2025 15:48 — 👍 2 🔁 0 💬 1 📌 0
In case it interest anyone: I went through all the competing definitions of "open source ai" in a short blog post. And the ongoing clarification process. pleias.fr/blog/blogwha...
13.02.2025 18:08 — 👍 18 🔁 6 💬 2 📌 0

Data Governance in Open Source AI
Data Governance in Open Source AI
The development of AI systems offers a crucial perspective for thinking about data, as it provides a strong case for creating value using publicly available data. https://opensource.org/datagovernance #opensourceai
13.02.2025 18:42 — 👍 4 🔁 1 💬 0 📌 0

Mistral small seems confused
11.02.2025 00:07 — 👍 0 🔁 0 💬 0 📌 0
Me confirman fuentes con conocimiento que lo de los Goya NO fue traducción automática.
Había un intérprete trauduciendo para los asistentes y una estenotipista transcribiendo al intérprete para los subtítulos de la TV. #Goya2025
09.02.2025 14:37 — 👍 0 🔁 1 💬 0 📌 0
YouTube video by zurnavi
Los Simpsons Mocasines Saltarines
Las canciones te las podrá traducir, pero las traducciones de canciones no suelen tener sentido, siempre hay que adaptarlas al contexto y la musicalidad del otro idioma (véase como lo hacían en Los Simpson magistralmente)
08.02.2025 15:15 — 👍 0 🔁 0 💬 0 📌 0
La interpretación simultánea siempre lleva retardo (la humana también), tienes que esperar a que el orador termine la frase para poder traducirla correctamente.
Dicen que es robusto al ruido, a multiples voces no sé, eso es complicado incluso offline (yo no puedo probarlo porque no sé francés 😆)
08.02.2025 15:15 — 👍 0 🔁 0 💬 1 📌 0

Hibiki Samples - a Hugging Face Space by kyutai
Discover amazing ML apps made by the community
Kyutai fueron también los autores de Moshi, el primer modelo de lenguaje conversacional speech-to-speech de código abierto, full duplex y en tiempo real. Un actor muy a tener en cuenta en este espacio.
08.02.2025 14:10 — 👍 1 🔁 0 💬 0 📌 0
En el panorama de la IA europeo también se están haciendo algunos desarrollos muy interesantes, como esto de Kyutai (🇫🇷)
Un modelo de interpretación simultánea (real-time), capaz hasta de reproducir el acento del orador, ¡y corre en un móvil!
De momento solo francés->inglés, pero muy prometedor:
08.02.2025 14:04 — 👍 0 🔁 1 💬 1 📌 1
Corrijo también sobre 4o, no sé por qué puse 600B, mi estimación era 400B, en cualquier caso más pequeño que Sonnet.
08.02.2025 13:51 — 👍 0 🔁 0 💬 0 📌 0
Exfluencer de vocación, intentando entender el mundo y reírme en el proceso.
Foundation Models for Generalizable Autonomy.
Assistant Professor in AI Robotics, Georgia Tech
prev Berkeley, Stanford, Toronto, Nvidia
🤗 LLM whisperer @huggingface
📖 Co-author of "NLP with Transformers" book
💥 Ex-particle physicist
🤘 Occasional guitarist
🇦🇺 in 🇨🇭
Passionate about AI & Journalism / Previously @hf.co @radiocanadainfo @ledevoir & others
Researcher trying to shape AI towards positive outcomes. ML & Ethics +birds. Generally trying to do the right thing. TIME 100 | TED speaker | Senate testimony provider | Navigating public life as a recluse.
Former: Google, Microsoft; Current: Hugging Face
Building Argilla @ Hugging Face 🤗. Linguist at heart. En ocasiones escribo en castellano.
I’m a people person who supports our team as they work to democratize AI at Hugging Face 🤗 I live in Sacramento, by way of Brooklyn. Winter is better here.
Machine Learning, Natural Language Processing, LLM, transformers, macOS, NixOS, Rust, C++, Python, Cycling.
Working on inference at Hugging Face 🤗. Open source ML 🚀.
Machine Learning Librarian at @hf.co
Software @ Apple AIML, previously Hugging Face
nsarrazin.com
all skeets are wrong, but some are useful // backend + ethics enabler at huggingface
Feeding LLMs @ Hugging Face
I build tools that propel communities forward
Technical Lead on Accelerate @ Hugging Face | Passionate about Open Source | https://muellerzr.github.io
Penguin of great renown.
The penguin revolution is nigh, only the feathered and the tuxedoed will be spared.
Except for seagulls, they can get fucked.
https://pngwn.at
Philosopher in tech, currently at Mistral AI. Doctor of talking machines, now teaching them good behavior.
ml art engineer @ huggingface, artist and umas coisinhas mais























