Tubingen just got ultra-exciting :D
06.08.2025 15:49 — 👍 3 🔁 0 💬 0 📌 0
Submit your latest and greatest papers to the hottest workshop on the block---on cognitive interpretability! 🔥
16.07.2025 14:12 — 👍 8 🔁 1 💬 0 📌 0
Home
First Workshop on Interpreting Cognition in Deep Learning Models (NeurIPS 2025)
Excited to announce the first workshop on CogInterp: Interpreting Cognition in Deep Learning Models @ NeurIPS 2025! 📣
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 coginterp.github.io/neurips2025/
1/4
16.07.2025 13:08 — 👍 58 🔁 19 💬 1 📌 3
I'll be at ICML beginning this Monday---hit me up if you'd like to chat!
12.07.2025 00:33 — 👍 3 🔁 0 💬 0 📌 0

In-Context Learning Strategies Emerge Rationally
Recent work analyzing in-context learning (ICL) has identified a broad set of strategies that describe model behavior in different experimental conditions. We aim to unify these findings by asking why...
Our recent paper may be relevant (arxiv.org/abs/2506.17859)! We take a rational analysis lens to argue that beyond simplicity bias, we must model how well a hypothesis explains the data to yield a *predictive* account of behavior in neural nets! This helps explain learning of more complex functions.
08.07.2025 15:39 — 👍 3 🔁 0 💬 0 📌 0
I am definitely not biased :)
28.06.2025 04:49 — 👍 1 🔁 0 💬 0 📌 0
Check out one of the most exciting papers of the year! :D
28.06.2025 04:49 — 👍 2 🔁 0 💬 1 📌 0
I'll be attending NAACL at New Mexico beginning today---hit me up if you'd like to chat!
29.04.2025 14:10 — 👍 1 🔁 0 💬 0 📌 0
Check out our new work on the duality between SAEs and how concepts are organized in model representations!
07.03.2025 02:56 — 👍 2 🔁 0 💬 0 📌 0
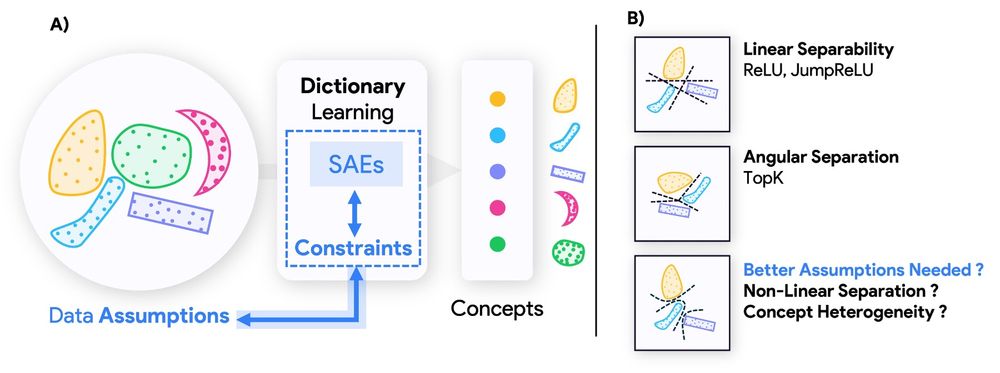
New preprint alert!
Do Sparse Autoencoders (SAEs) reveal all concepts a model relies on? Or do they impose hidden biases that shape what we can even detect?
We uncover a fundamental duality between SAE architectures and concepts they can recover.
Link: arxiv.org/abs/2503.01822
07.03.2025 02:48 — 👍 14 🔁 2 💬 1 📌 2
Oh god, I had no clue this happened. :/
Does bsky not do GIFs?
17.02.2025 14:35 — 👍 0 🔁 0 💬 1 📌 0
Very nice paper; quite aligned with the ideas in our recent perspective on the broader spectrum of ICL. In large models, there's probably a complicated, context dependent mixture of strategies that get learned, not a single ability.
16.02.2025 19:22 — 👍 17 🔁 2 💬 1 📌 0
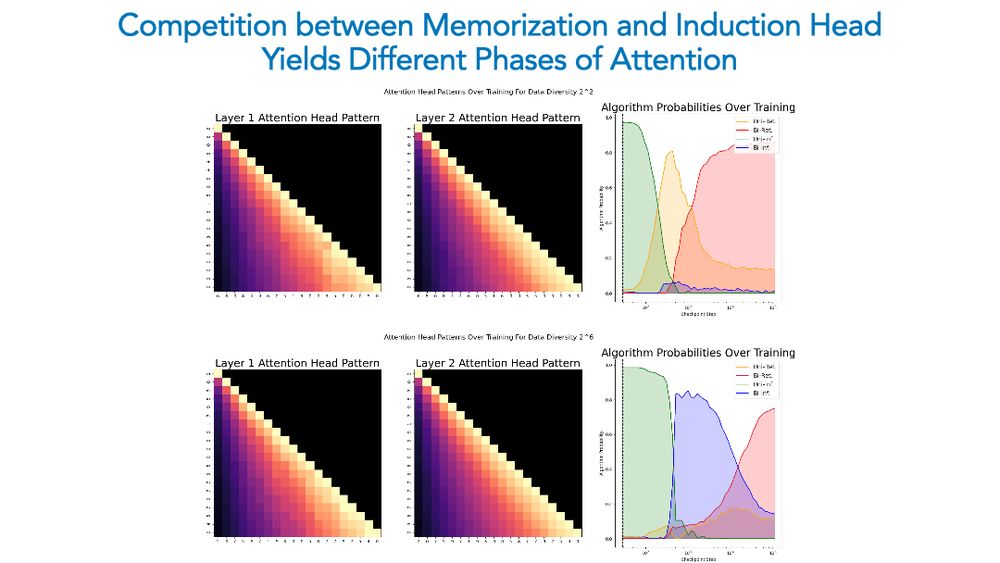
Dynamics of attention maps is particularly striking in this competition: e.g., with high diversity, we see a bigram counter forming, but memorization eventually occurs and the pattern becomes uniform! This means models can remove learned components if they are not useful anymore!
16.02.2025 18:57 — 👍 3 🔁 0 💬 1 📌 0
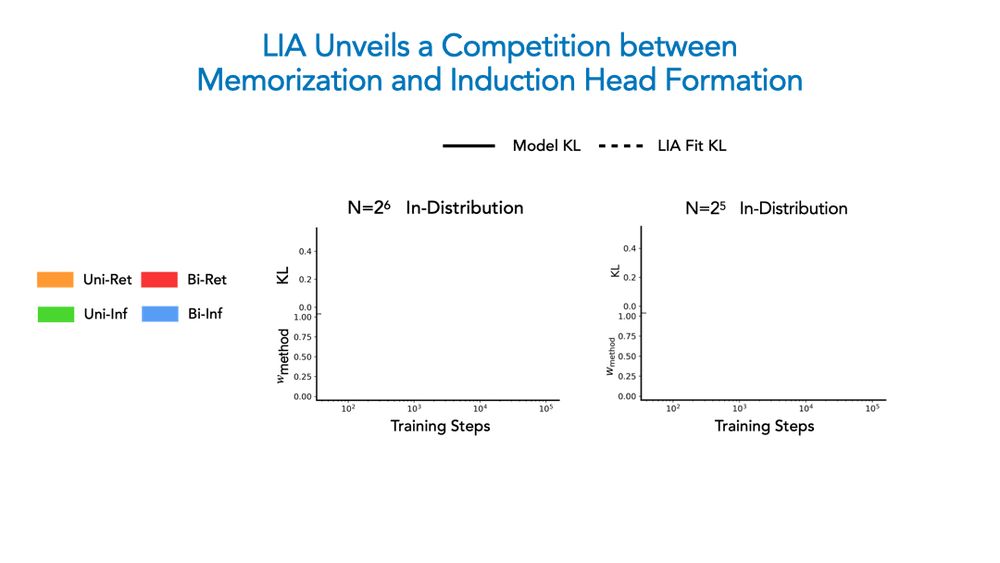
Beyond corroborating our phase diagram, LIA confirms a persistent competition underlies ICL: once the induction head forms, with enough diversity bigram-based inference takes over; under low diversity, memorization occurs faster, yielding a bigram-based retrieval solution!
16.02.2025 18:57 — 👍 1 🔁 0 💬 1 📌 0

Given optimization and data diversity are independent axes, we then ask if these forces race against each other to yield our observed algorithmic phases. We propose a tool called LIA (linear interpolation of algorithms) for this analysis.
16.02.2025 18:57 — 👍 2 🔁 0 💬 1 📌 0

The tests check out! We see before/after a critical # of train steps are met (where induction head emerges), the model relies on unigram/bigram stats. With few chains (less diversity), there is retrieval behavior: we can literally reconstruct transition matrices from MLP neurons!
16.02.2025 18:57 — 👍 1 🔁 0 💬 1 📌 0

To test the above claim, we compute the effect of shuffling a sequence on next-token probs: this breaks bigram stats, but preserves unigrams. We check how “retrieval-like” or memorization-based model behavior is by comparing predicted transitions’ KL to a random set of chains.
16.02.2025 18:57 — 👍 2 🔁 0 💬 1 📌 0

We claim four algorithms explain the model’s behavior in diff. train/test settings. These algos compute uni-/bi- gram frequency statistics of an input to either *retrieve* a memorized chain or to in-context *infer* the chain used to define the input: latter performs better OOD!
16.02.2025 18:57 — 👍 2 🔁 0 💬 1 📌 0

We analyze models trained on a fairly simple task: learning to simulate a *finite mixture* of Markov chains. The sequence modeling nature of this task makes it a better abstraction for studying ICL abilities in LMs, (compared to abstractions of few-shot learning like linear reg.)
16.02.2025 18:57 — 👍 3 🔁 0 💬 1 📌 0
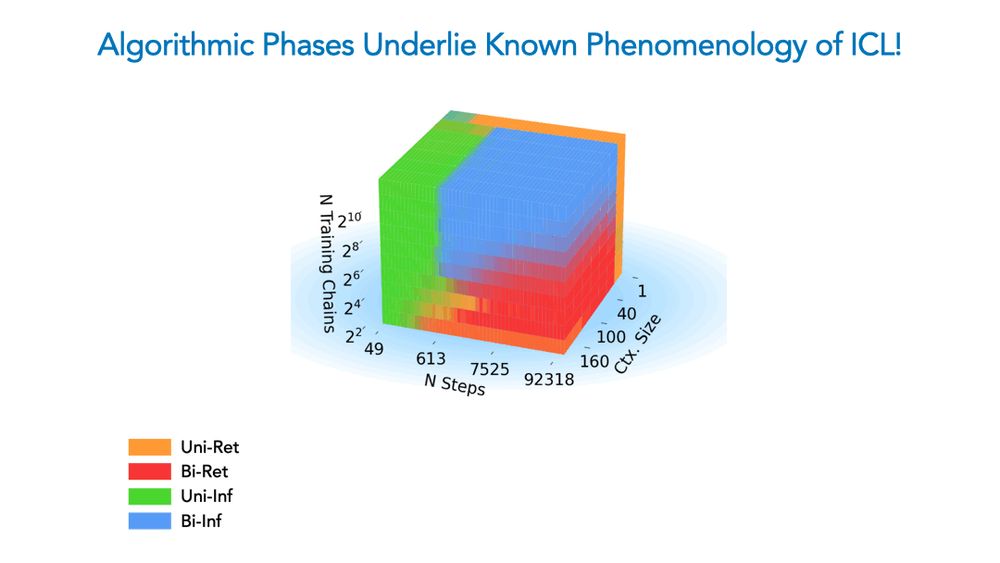
New paper–accepted as *spotlight* at #ICLR2025! 🧵👇
We show a competition dynamic between several algorithms splits a toy model’s ICL abilities into four broad phases of train/test settings! This means ICL is akin to a mixture of different algorithms, not a monolithic ability.
16.02.2025 18:57 — 👍 32 🔁 5 💬 2 📌 1
bsky.app/profile/ajyl...
12.02.2025 16:30 — 👍 1 🔁 0 💬 1 📌 0
Some threads about recent works ;-)
bsky.app/profile/ekde...
12.02.2025 16:30 — 👍 0 🔁 0 💬 1 📌 0
CareerPortal
Our group, funded by NTT Research, Inc., uniquely bridges industry and academia. We integrate approaches from physics, neuroscience, and psychology while grounding our work in empirical AI research.
Apply from "Physics of AI Group Research Intern": careers.ntt-research.com
12.02.2025 16:30 — 👍 0 🔁 0 💬 1 📌 0

There's never been a more exciting time to explore the science of intelligence! 🧠
What can ideas and approaches from science tell us about how AI works?
What might superhuman AI reveal about human cognition?
Join us for an internship at Harvard to explore together!
1/
12.02.2025 16:30 — 👍 2 🔁 1 💬 1 📌 0
Are those... bats?
30.01.2025 02:42 — 👍 1 🔁 0 💬 1 📌 0
Now accepted at NAACL! This would be my first time presenting at an ACL conference---I've got almost first-year grad school level of excitement! :P
23.01.2025 07:15 — 👍 4 🔁 0 💬 0 📌 0
New paper! “In-Context Learning of Representations”
What happens to an LLM’s internal representations in the large context limit?
We find that LLMs form “in-context representations” to match the structure of the task given in context!
05.01.2025 16:02 — 👍 7 🔁 2 💬 1 📌 0
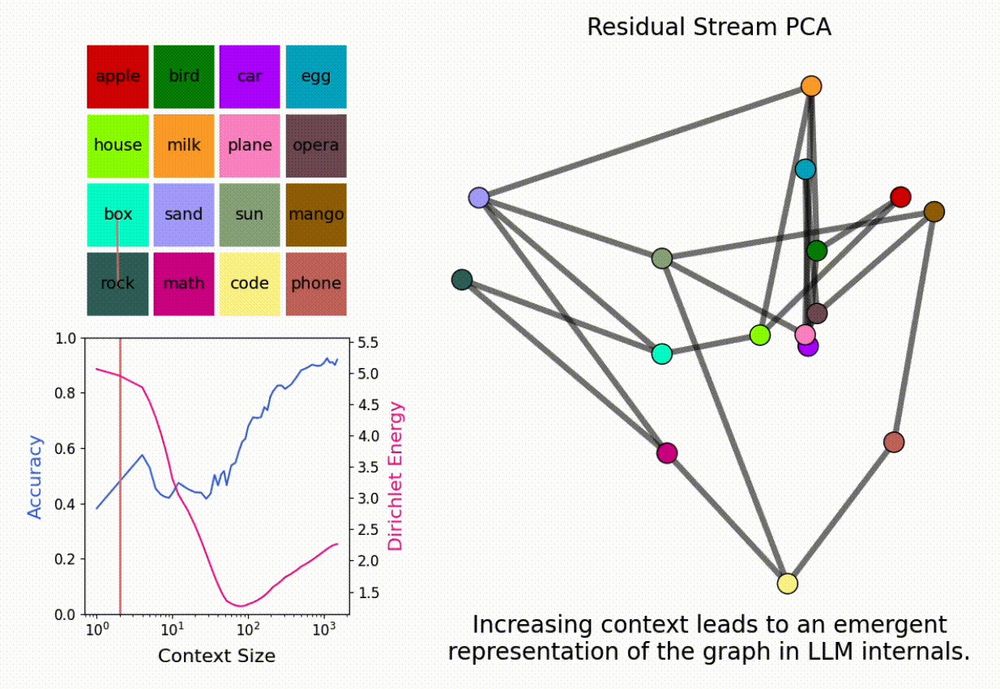
New paper <3
Interested in inference-time scaling? In-context Learning? Mech Interp?
LMs can solve novel in-context tasks, with sufficient examples (longer contexts). Why? Bc they dynamically form *in-context representations*!
1/N
05.01.2025 15:49 — 👍 53 🔁 16 💬 2 📌 1
PhD @Stanford studying cognitive science & AI
Prev: Pre-doc Fellow @Harvard, Econ & CS research with Paul Romer, Stats & ML @UniofOxford, Econ @Columbia
Applied math at Harvard
☕ wlt.coffee
PhD student in psychology at Harvard, research fellow at Goodfire AI
AI interpretability + computational cognitive science
🧠 Researcher: noorsajid.com
PhD @stanfordnlp.bsky.social
Postdoc at Harvard and MIT.
PhD @Stanford working w @noahdgoodman and research fellow @GoodfireAI
Studying in-context learning and reasoning in humans and machines
Prev. @UofT CS & Psych
Writing about robots https://itcanthink.substack.com/
RoboPapers podcast https://robopapers.substack.com/
All opinions my own
PhD student at Brown interested in deep learning + cog sci, but more interested in playing guitar.
CS PhD student at UT Austin in #NLP
Interested in language, reasoning, semantics and cognitive science. One day we'll have more efficient, interpretable and robust models!
Other interests: math, philosophy, cinema
https://www.juandiego-rodriguez.com/
The official account of the Amsterdam Machine Learning Lab (AMLab) at UvA, co-directed by Max Welling and Jan-Willem van de Meent.
AMLab, Informatics Institute, University of Amsterdam. ELLIS Scholar. Geometry-Grounded Representation Learning. Equivariant Deep Learning.
ML Scientist @CuspAI | Innovating for a greener future 🌱
Postdoctoral Fellow at Harvard Kempner Institute. Trying to bring natural structure to artificial neural representations. Prev: PhD at UvA. Intern @ Apple MLR, Work @ Intel Nervana
Assistant prof in the Amsterdam Machine Learning Lab at the University of Amsterdam | ELLIS scholar | #causality #causalML anything #causal | 🇮🇹🇸🇮 in 🇳🇱
#UAI2026 general chair
https://saramagliacane.github.io/
Sr. Principal Research Manager at Microsoft Research, NYC // Machine Learning, Responsible AI, Transparency, Intelligibility, Human-AI Interaction // WiML Co-founder // Former NeurIPS & current FAccT Program Co-chair // Brooklyn, NY // http://jennwv.com
Secular Bayesian.
Professor of Machine Learning at Cambridge Computer Lab
Talent aficionado at http://airetreat.org
Alum of Twitter, Magic Pony and Balderton Capital
Machine learning researcher. Professor in ML department at CMU.
Foundations of AI. I like simple and minimal examples and creative ideas. I also like thinking about the next token 🧮🧸
Google | PhD, CMU |
https://arxiv.org/abs/2504.15266 | https://arxiv.org/abs/2403.06963
vaishnavh.github.io
AGI research @DeepMind.
Ex cofounder & CTO Vicarious AI (acqd by Alphabet),
Cofounder Numenta
Triply EE (BTech IIT-Mumbai, MS&PhD Stanford). #AGIComics
blog.dileeplearning.com























