
I used to focus on left versus right. Now I’m much more worried about the money at the top. But while it might seem strange to say it, I think this is a hopeful way of looking at the world that opens the door to coalitions that seemed impossible before. My first for the @newrepublic.com:
15.10.2025 14:19 — 👍 81 🔁 33 💬 7 📌 5

"Bias Delayed is Bias Denied? Assessing the Effect of Reporting Delays on Disparity Assessments"
Conducting disparity assessments at regular time intervals is critical for surfacing potential biases in decision-making and improving outcomes across demographic groups. Because disparity assessments fundamentally depend on the availability of demographic information, their efficacy is limited by the availability and consistency of available demographic identifiers. While prior work has considered the impact of missing data on fairness, little attention has been paid to the role of delayed demographic data. Delayed data, while eventually observed, might be missing at the critical point of monitoring and action -- and delays may be unequally distributed across groups in ways that distort disparity assessments. We characterize such impacts in healthcare, using electronic health records of over 5M patients across primary care practices in all 50 states. Our contributions are threefold. First, we document the high rate of race and ethnicity reporting delays in a healthcare setting and demonstrate widespread variation in rates at which demographics are reported across different groups. Second, through a set of retrospective analyses using real data, we find that such delays impact disparity assessments and hence conclusions made across a range of consequential healthcare outcomes, particularly at more granular levels of state-level and practice-level assessments. Third, we find limited ability of conventional methods that impute missing race in mitigating the effects of reporting delays on the accuracy of timely disparity assessments. Our insights and methods generalize to many domains of algorithmic fairness where delays in the availability of sensitive information may confound audits, thus deserving closer attention within a pipeline-aware machine learning framework.
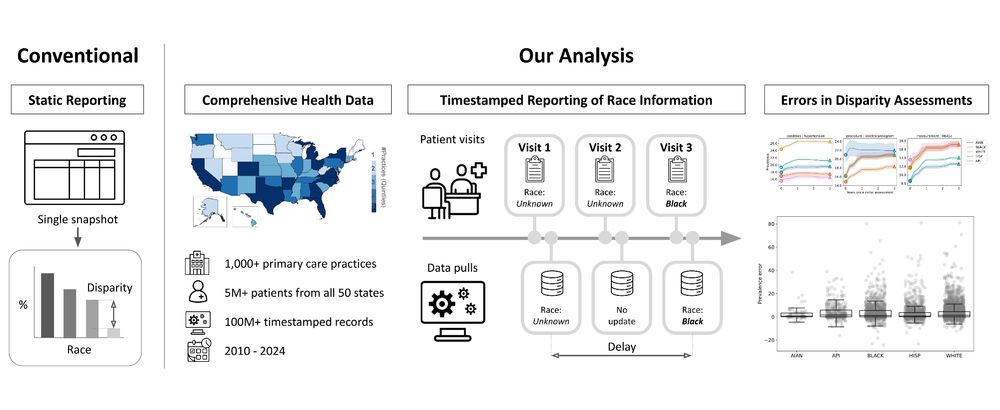
Figure contrasting a conventional approach to conducting disparity assessments, which is static, to the analysis we conduct in this paper. Our analysis (1) uses comprehensive health data from over 1,000 primary care practices and 5 million patients across the U.S., (2) timestamped information on the reporting of race to measure delay, and (3) retrospective analyses of disparity assessments under varying levels of delay.
I am presenting a new 📝 “Bias Delayed is Bias Denied? Assessing the Effect of Reporting Delays on Disparity Assessments” at @facct.bsky.social on Thursday, with @aparnabee.bsky.social, Derek Ouyang, @allisonkoe.bsky.social, @marzyehghassemi.bsky.social, and Dan Ho. 🔗: arxiv.org/abs/2506.13735
(1/n)
24.06.2025 14:51 — 👍 13 🔁 4 💬 1 📌 3

A screenshot of our paper's:
Title: A Framework for Auditing Chatbots for Dialect-Based Quality-of-Service Harms
Authors: Emma Harvey, Rene Kizilcec, Allison Koenecke
Abstract: Increasingly, individuals who engage in online activities are expected to interact with large language model (LLM)-based chatbots. Prior work has shown that LLMs can display dialect bias, which occurs when they produce harmful responses when prompted with text written in minoritized dialects. However, whether and how this bias propagates to systems built on top of LLMs, such as chatbots, is still unclear. We conduct a review of existing approaches for auditing LLMs for dialect bias and show that they cannot be straightforwardly adapted to audit LLM-based chatbots due to issues of substantive and ecological validity. To address this, we present a framework for auditing LLM-based chatbots for dialect bias by measuring the extent to which they produce quality-of-service harms, which occur when systems do not work equally well for different people. Our framework has three key characteristics that make it useful in practice. First, by leveraging dynamically generated instead of pre-existing text, our framework enables testing over any dialect, facilitates multi-turn conversations, and represents how users are likely to interact with chatbots in the real world. Second, by measuring quality-of-service harms, our framework aligns audit results with the real-world outcomes of chatbot use. Third, our framework requires only query access to an LLM-based chatbot, meaning that it can be leveraged equally effectively by internal auditors, external auditors, and even individual users in order to promote accountability. To demonstrate the efficacy of our framework, we conduct a case study audit of Amazon Rufus, a widely-used LLM-based chatbot in the customer service domain. Our results reveal that Rufus produces lower-quality responses to prompts written in minoritized English dialects.
I am so excited to be in 🇬🇷Athens🇬🇷 to present "A Framework for Auditing Chatbots for Dialect-Based Quality-of-Service Harms" by me, @kizilcec.bsky.social, and @allisonkoe.bsky.social, at #FAccT2025!!
🔗: arxiv.org/pdf/2506.04419
23.06.2025 14:44 — 👍 31 🔁 10 💬 1 📌 2
Worth noting today that the entire budget of the NEH is about $200M.
10.06.2025 15:48 — 👍 420 🔁 229 💬 6 📌 5

Wisconsin-Madison's tree-filled campus, next to a big shiny lake

A computer render of the interior of the new computer science, information science, and statistics building. A staircase crosses an open atrium with visibility across multiple floors
I'm joining Wisconsin CS as an assistant professor in fall 2026!! There, I'll continue working on language models, computational social science, & responsible AI. 🌲🧀🚣🏻♀️ Apply to be my PhD student!
Before then, I'll postdoc for a year in the NLP group at another UW 🏔️ in the Pacific Northwest
05.05.2025 19:54 — 👍 145 🔁 14 💬 16 📌 3
Slightly paraphrasing @oms279.bsky.social during his talk at #COMPTEXT2025:
"The single most important use case for LLMs in sociology is turning unstructured data into structured data."
Discussing his recent work on codebooks, prompts, and information extraction: osf.io/preprints/so...
25.04.2025 14:16 — 👍 29 🔁 5 💬 2 📌 0
China is a nation with over a hundred minority languages and many ethnic groups. What does this say about China’s 21st century AI policy?
09.04.2025 20:27 — 👍 1 🔁 0 💬 0 📌 0
This suggests a break from China’s past stance of using inclusive language policy as a way to build a multiethnic nation. We see no evidence of socio-political pressure or carrots for Chinese AI groups to dedicate resources for linguistic inclusivity.
09.04.2025 20:27 — 👍 1 🔁 0 💬 1 📌 0

In fact, many LLMs from China fail to even recognize some lower resource Chinese languages such as Uyghur.
09.04.2025 20:27 — 👍 1 🔁 0 💬 1 📌 0

LLMs from China are highly correlated with Western LLMs in multilingual performance (0.93 - 9.99) on tasks such as reading comprehension.
09.04.2025 20:27 — 👍 2 🔁 0 💬 1 📌 0
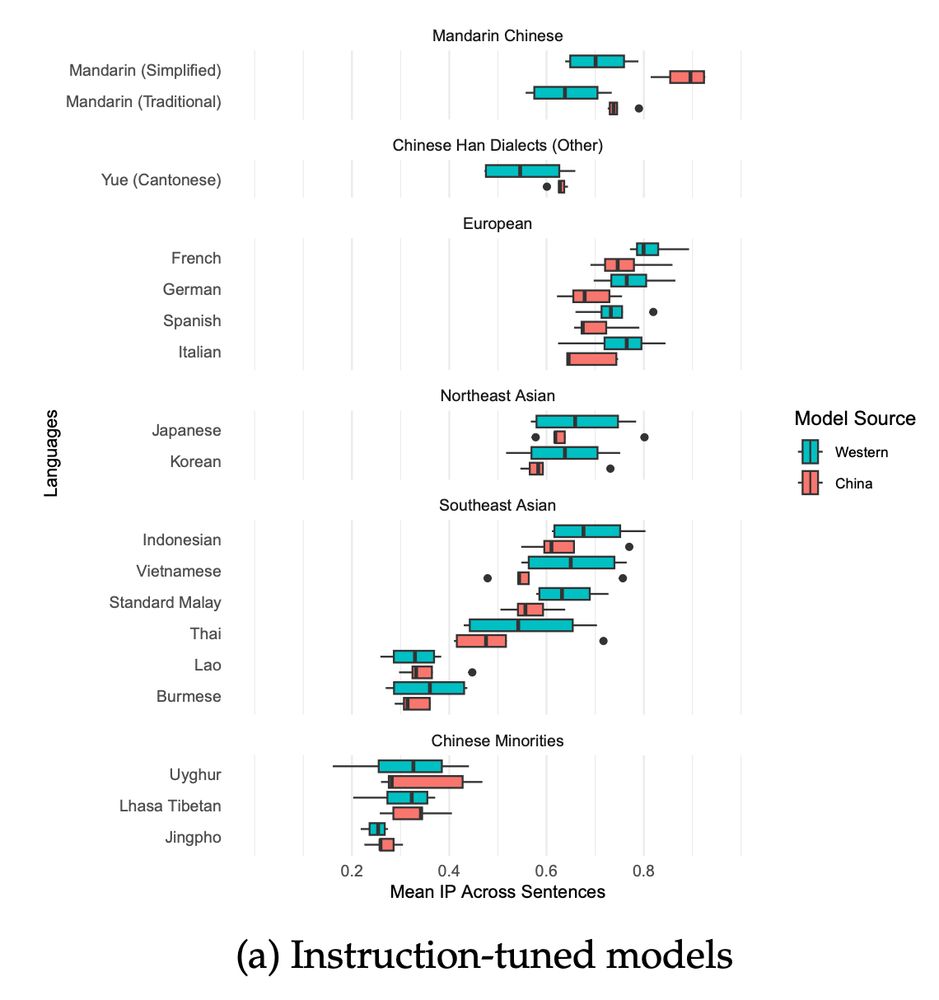
[New preprint!] Do Chinese AI Models Speak Chinese Languages? Not really. Chinese LLMs like DeepSeek are better at French than Cantonese. Joint work with
Unso Jo and @dmimno.bsky.social . Link to paper: arxiv.org/pdf/2504.00289
🧵
09.04.2025 20:27 — 👍 25 🔁 6 💬 1 📌 0
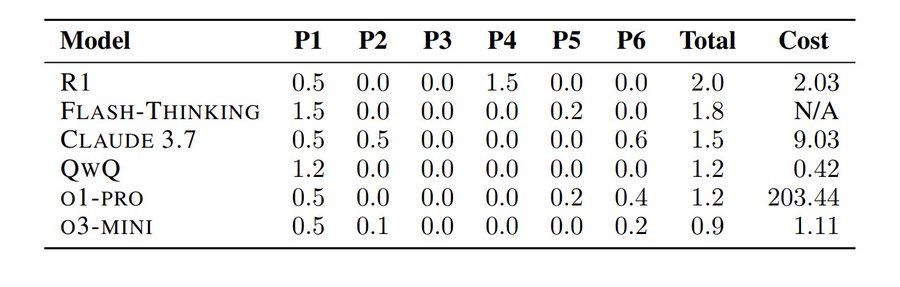
You’ve probably heard about how AI/LLMs can solve Math Olympiad problems ( deepmind.google/discover/blo... ).
So naturally, some people put it to the test — hours after the 2025 US Math Olympiad problems were released.
The result: They all sucked!
31.03.2025 20:33 — 👍 174 🔁 50 💬 9 📌 12
*NEW DATASET AND PAPER* (CHI2025): How are online communities responding to AI-generated content (AIGC)? We study this by collecting and analyzing the public rules of 300,000+ subreddits in 2023 and 2024. 1/
26.03.2025 17:17 — 👍 16 🔁 5 💬 1 📌 2
hey it's that time of year again, when people start to wonder whether AIES is actually happening and when this year’s paper deadline might be if so! anyone know anything about the ACM/AAAI conference on AI Ethics & Society for 2025?
(I used to ask about this every year on Twitter haha.)
19.03.2025 19:00 — 👍 21 🔁 6 💬 1 📌 1
Best Student Paper at #AIES 2024 went to @andreawwenyi.bsky.social! Annotating gender-biased narratives in the courtroom is a complex, nuanced task with frequent subjective decision-making by legal experts. We asked: What do experts desire from a language model in this annotation process?
11.11.2024 15:49 — 👍 19 🔁 4 💬 1 📌 1
Hi! Yess! Paper is here — aclanthology.org/2023.emnlp-m...
28.03.2024 02:49 — 👍 1 🔁 0 💬 1 📌 0
Link to paper: aclanthology.org/2023.emnlp-m...
21.02.2024 15:59 — 👍 0 🔁 0 💬 0 📌 0
Lots of exciting open questions from this work, e.g. 1) The effect of pre-training and model architectures on representations of languages and 2) The applications of cross-lingual representations embedded in language models.
21.02.2024 15:59 — 👍 0 🔁 0 💬 1 📌 0

Embedding geometries are similar across model families and scales, as measured by canonical angles. XLM-R models are extremely similar to each other, as well as mT5-small and base. All models are far from random (0.14–0.27).
21.02.2024 15:59 — 👍 0 🔁 0 💬 1 📌 0

The diversity of neighborhoods in mT5 varies by category. For tokens in two Japanese writing systems: KATAKANA, for words of foreign origin, has more diverse neighbors than HIRAGANA, used for native Japanese words.
21.02.2024 15:59 — 👍 2 🔁 0 💬 1 📌 0

The nearest neighbors of mT5 tokens are often translations. NLP spent 10 years trying to make word embeddings align across languages. mT5 embeddings find cross-lingual semantic alignment without even being asked!
21.02.2024 15:58 — 👍 4 🔁 0 💬 1 📌 1

mT5 embeddings neighborhoods are more linguistically diverse: the 50 nearest neighbors for any token represent an average of 7.61 writing systems, compared to 1.64 with XLM-R embedding.
21.02.2024 15:58 — 👍 0 🔁 0 💬 1 📌 0

Tokens in different writing systems can be linearly separated with an average of 99.2 % accuracy for XLM. Even in high-dimensional space, mT5 embeddings are less separable.
21.02.2024 15:57 — 👍 0 🔁 1 💬 1 📌 0

XLM-R embeddings partition by language, while mT5 has more overlap. Since it's hard to identify the language of BPE tokens, we use Unicode writing systems instead. Both plots contain points for the intersection of the two models' vocabularies.
21.02.2024 15:57 — 👍 0 🔁 0 💬 1 📌 0

How do LLMs represent relationships between languages? By studying the embedding layers of XLM-R and mT5, we find they are highly interpretable. LLMs can find semantic alignment as an emergent property! Joint work with @dmimno.bsky.social. 🧵
21.02.2024 15:57 — 👍 26 🔁 4 💬 2 📌 0
For the little guy. Former FTC commissioner. Current Bad Bunny stan
past: circus performer; historian of science; librarian; chief data officer at NEH.
present: dad; resident scholar at dartmouth; chief technology officer at the library of virginia.
personal account; views solely my own.
https://scottbot.github.io
ELLIS PhD Fellow @belongielab.org | @aicentre.dk | University of Copenhagen | @amsterdamnlp.bsky.social | @ellis.eu
Multi-modal ML | Alignment | Culture | Evaluations & Safety| AI & Society
Web: https://www.srishti.dev/
Incoming Assistant Professor @cornellbowers.bsky.social
Researcher @togetherai.bsky.social
Previously @stanfordnlp.bsky.social @ai2.bsky.social @msftresearch.bsky.social
https://katezhou.github.io/
PhDing at LTI, CMU
Prev: Ai2, Google Research, MSR
Evaluating language technologies, regularly ranting, and probably procrastinating.
https://sites.google.com/view/shailybhatt/
Princeton Sociology Prof; ethnographer of NASA; tech policy; digitalSTS; ethics and critical technical practice; mobile Linux. Conscientious objector to personal data economy.
https://janet.vertesi.com
https://www.optoutproject.net
@cyberlyra@hachyderm.io
Assistant Professor of Sociology at Northwestern
Culture, political sociology, NLP, social networks, computational social science
oscarstuhler.org
PhD student @mainlp.bsky.social (@cislmu.bsky.social, LMU Munich). Interested in language variation & change, currently working on NLP for dialects and low-resource languages.
verenablaschke.github.io
Research collaboration among 5 universities in Denmark: Aalborg University, IT University of Copenhagen, University of Aarhus, Technical University of Denmark, and the University of Copenhagen.
https://www.aicentre.dk/
Assoc. Prof of IEng, CS & Eng @ PSU #CogSci, #AI, Critical Black Studies, Hum. Factors. AfAm. 1stGen. THiCC lab PI (https://sites.psu.edu/thicc). Incoming Co-Director @digblk.bsky.social. Co-lead at AI-SDM (https://www.cmu.edu/ai-sdm/). All opinions my own
Information Science PhD student at Cornell
Former: AI Research Scientist at Intel Labs, Postdoc at Princeton, DPhil at Oxford
Professor, University Of Copenhagen 🇩🇰 PI @belongielab.org 🕵️♂️ Director @aicentre.dk 🤖 Board member @ellis.eu 🇪🇺 Formerly: Cornell, Google, UCSD
#ComputerVision #MachineLearning
Book: https://thecon.ai
Web: https://faculty.washington.edu/ebender
AI is not inevitable. We DAIR to imagine, build & use AI deliberately.
Website: http://dair-institute.org
Mastodon: @DAIR@dair-community.social
LinkedIn: https://www.linkedin.com/company/dair-institute/
Surprised historian, not surprised eels.
Doctor of medieval things. Talkin’ eels, history, and maps. Spaniel mourner. Alt-text artist.
I draw custom maps and artwork on commission:
https://surprisedeelmaps.com/
Support me here: patreon.com/SurprisedEel
Human-centered AI #HCAI, NLP & ML. Director TRAILS (Trustworthy AI in Law & Society) and AIM (AI Interdisciplinary Institute at Maryland). Formerly Microsoft Research NYC. Fun: 🧗🧑🍳🧘⛷️🏕️. he/him.
Studying NLP, CSS, and Human-AI interaction. PhD student @MIT. Previously at Microsoft FATE + CSS, Oxford Internet Institute, Stanford Symbolic Systems
hopeschroeder.com






















