As a way of evaluating the model (rather than the variational family or inference method)
06.07.2025 11:03 — 👍 1 🔁 0 💬 0 📌 0
By contrast, of course, a good VI method should give good posteriors. If better posteriors give worse predictions, it's the model's fault, not the VI method's
06.07.2025 10:45 — 👍 1 🔁 0 💬 1 📌 0
Yes, I agree... It's a very (non-Bayesian) ML-inflected way of looking at things, where the whole game is to maximize predictive accuracy on new data, and the training data D is just instrumental to this goal.
06.07.2025 10:45 — 👍 1 🔁 0 💬 1 📌 0
Right, I think if you're trying to estimate P*, it's okay that Method 2 is inconsistent. The way you "spend more compute" in Method 2 is by choosing a bigger/more expressive variational family q, not taking more samples from a fixed variational family. So consistency isn't quite the right property
06.07.2025 10:29 — 👍 0 🔁 0 💬 1 📌 0
Oh -- I agree it doesn't make sense to choose q1 or q2 based on the quantity! Or at least, if you do that, you're just fitting the model q(θ)p(D'|θ) to the held-out data D', not doing posterior inference anymore.
06.07.2025 10:27 — 👍 1 🔁 0 💬 1 📌 0
(Though even if you use approach 2, it is probably better to use q as a proposal within IS, rather than using it directly to substitute the posterior)
05.07.2025 11:38 — 👍 1 🔁 0 💬 1 📌 0
We can't sample p(θ|D) exactly, so consider two procedures for sampling θ from distributions _close_ to p(θ|D):
1 - run MCMC / SMC / etc. targeting p(θ|D)
2 - run VI to obtain q(θ) then draw independent θs from q via simple MC
Not obvious that Method 1 always wins (for a given computational budget)
05.07.2025 11:36 — 👍 1 🔁 0 💬 1 📌 0

not sure how to get this across to non-academics but here goes,
Imagine if you were suddenly told 'we decided not to pay your salary', that's kind of what the grant cuts felt like.
Now imagine if you were suddenly told 'we are going to set your dog on fire', that's what this feels like:
22.05.2025 18:35 — 👍 363 🔁 91 💬 18 📌 5
Want to use AWRS SMC?
Check out the GenLM control library: github.com/genlm/genlm-...
GenLM supports not only grammars, but arbitrary programmable constraints from type systems to simulators.
If you can write a Python function, you can control your language model!
13.05.2025 14:22 — 👍 6 🔁 1 💬 1 📌 0
Many LM applications may be formulated as text generation conditional on some (Boolean) constraint.
Generate a…
- Python program that passes a test suite.
- PDDL plan that satisfies a goal.
- CoT trajectory that yields a positive reward.
The list goes on…
How can we efficiently satisfy these? 🧵👇
13.05.2025 14:22 — 👍 12 🔁 6 💬 2 📌 0
#ICLR2025 Oral
How can we control LMs using diverse signals such as static analyses, test cases, and simulations?
In our paper “Syntactic and Semantic Control of Large Language Models via Sequential Monte Carlo” (w/ @benlipkin.bsky.social,
@alexlew.bsky.social, @xtimv.bsky.social) we:
25.04.2025 19:33 — 👍 7 🔁 6 💬 1 📌 0
I'd love to see these ideas migrated to Gen.jl! But there are some technical questions about how best to make that work.
25.02.2025 16:26 — 👍 0 🔁 0 💬 0 📌 0
Hi, thanks for your interest! The pedagogical implementations can be found at:
Julia: github.com/probcomp/ADE...
Haskell: github.com/probcomp/ade...
The (less pedagogical, more performant) JAX implementation is still under active development, led by McCoy Becker.
25.02.2025 16:26 — 👍 2 🔁 0 💬 1 📌 0
- Daphne Koller had arguably the first PPL paper about inference-in-Bayesian-models-cast-as-programs
- Alexandra Silva has great work on semantics, static analysis, and verification of probabilistic & non-det. progs
- Annabelle McIver does too
- Nada Amin has cool recent papers on PPL semantics
10.02.2025 07:00 — 👍 10 🔁 1 💬 0 📌 0

trl/trl/trainer/grpo_trainer.py at 55e680e142d88e090dcbf5a469eab1ebba28ddef · huggingface/trl
Train transformer language models with reinforcement learning. - huggingface/trl
DeepSeek's implementation isn't public, and maybe I'm misinterpreting their paper. But the TRL reimplementation does appear to follow this logic. github.com/huggingface/...
Curious what people think we should make of this!
8/8
10.02.2025 04:32 — 👍 3 🔁 0 💬 0 📌 0
The usual KL penalty says: try not to wander outside the realm of sensible generations [as judged by our pretrained model].
This penalty says: try not to lose any of the behaviors present in the pretrained model.
Which is a bit strange as a fine-tuning objective.
7/
10.02.2025 04:32 — 👍 7 🔁 1 💬 2 📌 1
![**Mathematical formulation of an alternative KL estimator and its gradient.**
The alternative KL estimator is defined as:
\[
\widehat{KL}_\theta(x) := \frac{\pi_{\text{ref}}(x)}{\pi_\theta(x)} + \log \pi_\theta(x) - \log \pi_{\text{ref}}(x) - 1
\]
From this, it follows that:
\[
\mathbb{E}_{x \sim \pi_{\text{old}}} [\nabla_\theta \widehat{KL}_\theta(x)] = \nabla_\theta \mathbb{E}_{x \sim \pi_{\text{old}}} \left[ \frac{\pi_{\text{ref}}(x)}{\pi_\theta(x)} + \log \pi_\theta(x) \right]
\]
Approximating when \(\pi_{\text{old}} \approx \pi_\theta\), we get:
\[
\approx \nabla_\theta \mathbb{E}_{x \sim \pi_{\text{ref}}} [-\log \pi_\theta(x)] + \nabla_\theta \mathbb{E}_{x \sim \pi_{\text{old}}} [\log \pi_\theta(x)]
\]
The annotated explanation in purple states that this results in:
\[
\text{CrossEnt}(\pi_{\text{ref}}, \pi_\theta) - \text{CrossEnt}(\pi_{\text{old}}, \pi_\theta)
\]
where \(\text{CrossEnt}(\cdot, \cdot)\) denotes cross-entropy.
----
alt text generated by ChatGPT](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:qcllgepvb7hg5gsxvkgoe37i/bafkreie24fwpuxelcccq3gj42af2tlh27dujfqagohzsslelof25g5u5cm@jpeg)
**Mathematical formulation of an alternative KL estimator and its gradient.**
The alternative KL estimator is defined as:
\[
\widehat{KL}_\theta(x) := \frac{\pi_{\text{ref}}(x)}{\pi_\theta(x)} + \log \pi_\theta(x) - \log \pi_{\text{ref}}(x) - 1
\]
From this, it follows that:
\[
\mathbb{E}_{x \sim \pi_{\text{old}}} [\nabla_\theta \widehat{KL}_\theta(x)] = \nabla_\theta \mathbb{E}_{x \sim \pi_{\text{old}}} \left[ \frac{\pi_{\text{ref}}(x)}{\pi_\theta(x)} + \log \pi_\theta(x) \right]
\]
Approximating when \(\pi_{\text{old}} \approx \pi_\theta\), we get:
\[
\approx \nabla_\theta \mathbb{E}_{x \sim \pi_{\text{ref}}} [-\log \pi_\theta(x)] + \nabla_\theta \mathbb{E}_{x \sim \pi_{\text{old}}} [\log \pi_\theta(x)]
\]
The annotated explanation in purple states that this results in:
\[
\text{CrossEnt}(\pi_{\text{ref}}, \pi_\theta) - \text{CrossEnt}(\pi_{\text{old}}, \pi_\theta)
\]
where \(\text{CrossEnt}(\cdot, \cdot)\) denotes cross-entropy.
----
alt text generated by ChatGPT
When we differentiate their (Schulman's) estimator, pi_ref comes back into the objective, but in a new role.
Now, the objective has a CrossEnt(pi_ref, pi_theta) term. KL(P,Q) = CrossEnt(P,Q) - Entropy(P), so this is related to KL, but note the direction of KL is reversed.
6/
10.02.2025 04:32 — 👍 3 🔁 1 💬 1 📌 0
![**Mathematical explanation of the standard KL estimator and its gradient.**
The standard KL estimator is defined as:
\[
\widehat{KL}_\theta(x) := \log \pi_\theta(x) - \log \pi_{\text{ref}}(x)
\]
From this, it follows that:
\[
\mathbb{E}_{x \sim \pi_{\text{old}}} [\nabla_\theta \widehat{KL}_\theta(x)] = \nabla_\theta \mathbb{E}_{x \sim \pi_{\text{old}}} [\log \pi_\theta(x)]
\]
Annotated explanation in purple states that this term represents the *negative cross-entropy from \(\pi_{\text{old}}\) to \(\pi_\theta\).*
--
alt text automatically generated by ChatGPT](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:qcllgepvb7hg5gsxvkgoe37i/bafkreiarwn5s236xblh76hunn7pkimyhivh2kcsbn6u7impq74ztond23i@jpeg)
**Mathematical explanation of the standard KL estimator and its gradient.**
The standard KL estimator is defined as:
\[
\widehat{KL}_\theta(x) := \log \pi_\theta(x) - \log \pi_{\text{ref}}(x)
\]
From this, it follows that:
\[
\mathbb{E}_{x \sim \pi_{\text{old}}} [\nabla_\theta \widehat{KL}_\theta(x)] = \nabla_\theta \mathbb{E}_{x \sim \pi_{\text{old}}} [\log \pi_\theta(x)]
\]
Annotated explanation in purple states that this term represents the *negative cross-entropy from \(\pi_{\text{old}}\) to \(\pi_\theta\).*
--
alt text automatically generated by ChatGPT
Interestingly, if they were *not* using this estimator, and instead using the standard estimator, pi_ref would not affect the gradient at all!
More evidence that there's something odd about their approach. And maybe one reason they turned to Schulman's estimator.
5/
10.02.2025 04:32 — 👍 3 🔁 0 💬 1 📌 0

Text from the GRPO paper:
And different from the KL penalty term used in (2), we estimate the KL divergence with the following unbiased estimator (Schulman, 2020):
KL(pi_theta || pi_ref) = pi_ref(o_{i,t} | q, o_{i,<t}) / pi_theta(o_{i,t} | q,o_{i,<t}) - log pi_ref(o_{i,t} | q, o_{i,<t}) / pi_theta(o_{i,t} | q,o_{i,<t}) - 1
which is guaranteed to be positive.
This means GRPO is not optimizing the usual objective. What objective *is* it optimizing? Well, it depends on the particular KL estimator they are using.
A few people have noticed that GRPO uses a non-standard KL estimator, from a blog post by Schulman.
4/
10.02.2025 04:32 — 👍 2 🔁 0 💬 1 📌 0
![**Mathematical formulation of the GRPO (Group-Relative Policy Optimization) objective and its gradient.**
The objective function is defined as:
\[
J_{\text{GRPO}}(\theta) = \mathbb{E}_{x \sim \pi_\theta} [R_\theta(x)] - \beta \cdot \mathbb{E}_{x \sim \pi_{\text{old}}} [\widehat{KL}_\theta(x)]
\]
The gradient of this objective is:
\[
\nabla J_{\text{GRPO}}(\theta) = \nabla_\theta \mathbb{E}_{x \sim \pi_\theta} [R_\theta(x)] - \beta \cdot \mathbb{E}_{x \sim \pi_{\text{old}}} [\nabla_\theta \widehat{KL}_\theta(x)]
\]
Annotated explanations in purple indicate that the first term is *unbiasedly estimated via the group-relative policy gradient*, while the second term is *not* the derivative of the KL divergence, even when \(\pi_{\text{old}} = \pi_\theta\).
----
(alt text automatically generated by ChatGPT)](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:qcllgepvb7hg5gsxvkgoe37i/bafkreiclfcpvnd45wnhxldssr6qhzjl35esmkpvyxax4qxlpgs2meaauqa@jpeg)
**Mathematical formulation of the GRPO (Group-Relative Policy Optimization) objective and its gradient.**
The objective function is defined as:
\[
J_{\text{GRPO}}(\theta) = \mathbb{E}_{x \sim \pi_\theta} [R_\theta(x)] - \beta \cdot \mathbb{E}_{x \sim \pi_{\text{old}}} [\widehat{KL}_\theta(x)]
\]
The gradient of this objective is:
\[
\nabla J_{\text{GRPO}}(\theta) = \nabla_\theta \mathbb{E}_{x \sim \pi_\theta} [R_\theta(x)] - \beta \cdot \mathbb{E}_{x \sim \pi_{\text{old}}} [\nabla_\theta \widehat{KL}_\theta(x)]
\]
Annotated explanations in purple indicate that the first term is *unbiasedly estimated via the group-relative policy gradient*, while the second term is *not* the derivative of the KL divergence, even when \(\pi_{\text{old}} = \pi_\theta\).
----
(alt text automatically generated by ChatGPT)
GRPO instead directly differentiates the KL estimator, evaluated on samples taken from pi_old (the LM before this update).
But the point of policy gradient is that you can't just "differentiate the estimator": you need to account for the gradient of the sampling process.
3/
10.02.2025 04:32 — 👍 5 🔁 0 💬 1 📌 0
![**Mathematical expression describing KL-penalized reinforcement learning objective.**
The objective function is given by:
\[
J(\theta) = \mathbb{E}_{x \sim \pi_\theta} [R_\theta(x)] - \beta \cdot D_{\text{KL}}(\pi_\theta, \pi_{\text{ref}})
\]
Rewritten as:
\[
J(\theta) = \mathbb{E}_{x \sim \pi_\theta} [\tilde{R}_\theta(x)]
\]
where:
\[
\tilde{R}_\theta(x) := R_\theta(x) - \beta \cdot \widehat{KL}_\theta(x)
\]
\[
\widehat{KL}_\theta(x) := \log \pi_\theta(x) - \log \pi_{\text{ref}}(x)
\]
Annotations in purple indicate that \( R_\theta(x) \) represents the reward, and \( \widehat{KL}_\theta(x) \) is an unbiased estimator of the KL divergence.
----
(alt text generated by ChatGPT)](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:qcllgepvb7hg5gsxvkgoe37i/bafkreigq27u6ammyhocjpimpn5nlf4j5spts4e6bkzafnftmgxqxalhhj4@jpeg)
**Mathematical expression describing KL-penalized reinforcement learning objective.**
The objective function is given by:
\[
J(\theta) = \mathbb{E}_{x \sim \pi_\theta} [R_\theta(x)] - \beta \cdot D_{\text{KL}}(\pi_\theta, \pi_{\text{ref}})
\]
Rewritten as:
\[
J(\theta) = \mathbb{E}_{x \sim \pi_\theta} [\tilde{R}_\theta(x)]
\]
where:
\[
\tilde{R}_\theta(x) := R_\theta(x) - \beta \cdot \widehat{KL}_\theta(x)
\]
\[
\widehat{KL}_\theta(x) := \log \pi_\theta(x) - \log \pi_{\text{ref}}(x)
\]
Annotations in purple indicate that \( R_\theta(x) \) represents the reward, and \( \widehat{KL}_\theta(x) \) is an unbiased estimator of the KL divergence.
----
(alt text generated by ChatGPT)
RL for LMs often introduces a KL penalty term, to balance the "maximize reward" objective with an incentive to stay close to some reference model.
A way to implement is to modify the reward, so E[R~]=E[R] - KL term. Then you can apply standard RL (e.g. policy gradient).
2/
10.02.2025 04:32 — 👍 5 🔁 0 💬 1 📌 0

Also note that, instead of adding KL penalty in the reward, GRPO regularizes by directly adding the KL divergence between the trained policy and the reference policy to the loss, avoiding complicating the calculation of the advantage.
@xtimv.bsky.social and I were just discussing this interesting comment in the DeepSeek paper introducing GRPO: a different way of setting up the KL loss.
It's a little hard to reason about what this does to the objective. 1/
10.02.2025 04:32 — 👍 50 🔁 10 💬 3 📌 0
Yeah — would be interesting to know if the pattern holds for today’s larger models! (This paper was done 1.5 years ago, in academia, using open models)
30.12.2024 16:04 — 👍 1 🔁 0 💬 0 📌 0
Furthermore, regardless of training procedure, the models are still autoregressive probabilistic sequence models, so they can be understood as optimal “autocompleters” for *some* data distribution.
“If this is our conversation so far, what word would an assistant probably say next?”
30.12.2024 15:52 — 👍 2 🔁 0 💬 0 📌 0

A plot from the Direct Preference Optimization paper, comparing various methods of aligning LMs to preference data.
Hm, I think the base LMs are quite interesting. From the DPO paper: sampling 128 completions from a base model, and then selecting the sample with highest reward under the RLHF reward model, performs similarly to actual RLHF.
30.12.2024 15:49 — 👍 3 🔁 0 💬 2 📌 0

Probabilistic and differentiable programming at Yale — fully funded PhD positions starting Fall 2025! Apply by Dec. 15.
Do a PhD at the rich intersection of programming languages and machine learning.
If you're interested in a PhD at the intersection of machine learning and programming languages, consider applying to Yale CS!
We're exploring new approaches to building software that draws inferences and makes predictions. See alexlew.net for details & apply at gsas.yale.edu/admissions/ by Dec. 15
08.12.2024 16:27 — 👍 71 🔁 22 💬 1 📌 2
Agreed re GMMs, but fitting latent-variable generative models is a fundamental problem in ML, and I suspect variational and adversarial approaches will both be in textbooks many years from now—even if no one uses, e.g., vanilla VAEs for image generation
28.11.2024 14:01 — 👍 7 🔁 1 💬 0 📌 0
Maybe you'd count it as "indirect utility" but most of those papers were written *for* peer review, which likely encouraged authors to do more thorough experiments, be more careful with their claims, read more of the related work, etc. (Of course writing "for review" can also have negative effects.)
25.11.2024 07:35 — 👍 8 🔁 0 💬 0 📌 0
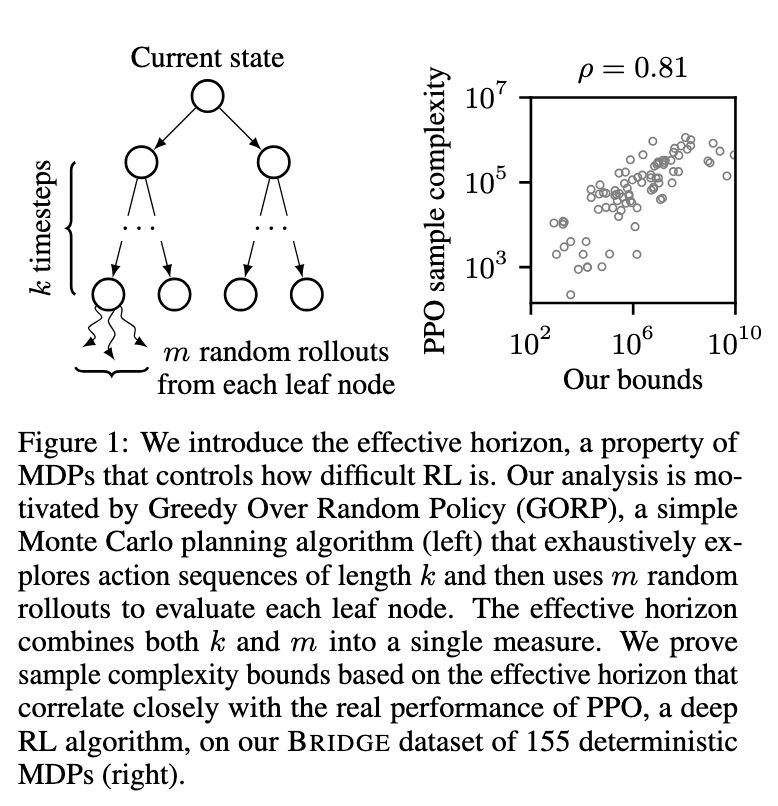
e introduce the effective horizon, a property of
MDPs that controls how difficult RL is. Our analysis is mo-
tivated by Greedy Over Random Policy (GORP), a simple
Monte Carlo planning algorithm (left) that exhaustively ex-
plores action sequences of length k and then uses m random
rollouts to evaluate each leaf node. The effective horizon
combines both k and m into a single measure. We prove
sample complexity bounds based on the effective horizon that
correlate closely with the real performance of PPO, a deep
RL algorithm, on our BRIDGE dataset of 155 deterministic
MDPs (right).
Kind of a broken record here but proceedings.neurips.cc/paper_files/...
is totally fascinating in that it postulates two underlying, measurable structures that you can use to assess if RL will be easy or hard in an environment
23.11.2024 18:18 — 👍 151 🔁 28 💬 8 📌 2
I'm not against text-to-speech as, e.g., a browser plug-in, or a way to increase accessibility for people who prefer to listen than to read. But it sucks to see big media companies replacing talented voice actors with this way-inferior AI narration
23.11.2024 20:11 — 👍 0 🔁 0 💬 1 📌 0
Assoc. Prof in CS @ Northeastern, NLP/ML & health & etc. He/him.
i am a cognitive scientist working on auditory perception at the University of Auckland and the Yale Child Study Center 🇳🇿🇺🇸🇫🇷🇨🇦
lab: themusiclab.org
personal: mehr.nz
intro to my research: youtu.be/-vJ7Jygr1eg
This is the account of the Programming Languages Research Group at the University of Bristol.
https://plrg-bristol.github.io/
Cognitive scientist working at the intersection of moral cognition and AI safety. Currently: Google Deepmind. Soon: Assistant Prof at NYU Psychology. More at sites.google.com/site/sydneymlevine.
Delivered effective, efficient, and secure digital services for the American people until we were forced to stop on March 1, 2025. Not an official government account. Reposts are not endorsements. Our new website: https://18f.org/ #AltGov
The world's leading venue for collaborative research in theoretical computer science. Follow us at http://YouTube.com/SimonsInstitute.
PhD research fellow at Active Inference Institute, data science, cognitive science, probabilistic models, Julia, Montana regenerative hobby farmer, author of Economic Direct Democracy: A Framework to End Poverty and Maximize Well-Being. #wellbeingeconomy
computational immunology and transcriptomics @KiraGenBio| formerly @MIT@harvardmed and @hgsuuaw healthcare | she/her | 🏳️🌈👩🏻💻
tessadgreen.github.io
CS PhD at Yale working with Tom McCoy and Tyler Brooke-Wilson on computational cognitive science.
kstechly.github.io
Independent LGBTQ+ journalist, mom, D&D DM. Tips: http://ko-fi.com/erininthemorn // Booking: http://erinreedwrites.com // Venmo erin888
Bylines @TheGuardian.com, @advocate.com, @xtramagazine.com
Subscribe to support my journalism www.erininthemorning.com
wife • doll • liberal • swiftie • psalm 27:4 • my opinions
ML researcher, MSR + Stanford postdoc, future Yale professor
https://afedercooper.info
CS Prof @ TU Wien (Vienna), prev DevAI @ Google, Probability @ Meta, Researcher @ MIT and Uni Zurich
Incoming asst professor at MIT EECS, Fall 2025. Research scientist at Databricks. CS PhD @StanfordNLP.bsky.social. Author of ColBERT.ai & DSPy.ai.
Building Gemini/Gemma at Deepmind and generative models for 8+ years with PyMC crew. Formerly built rockets at SpaceX
Postdoc at CBS, Harvard University
(New around here)



















