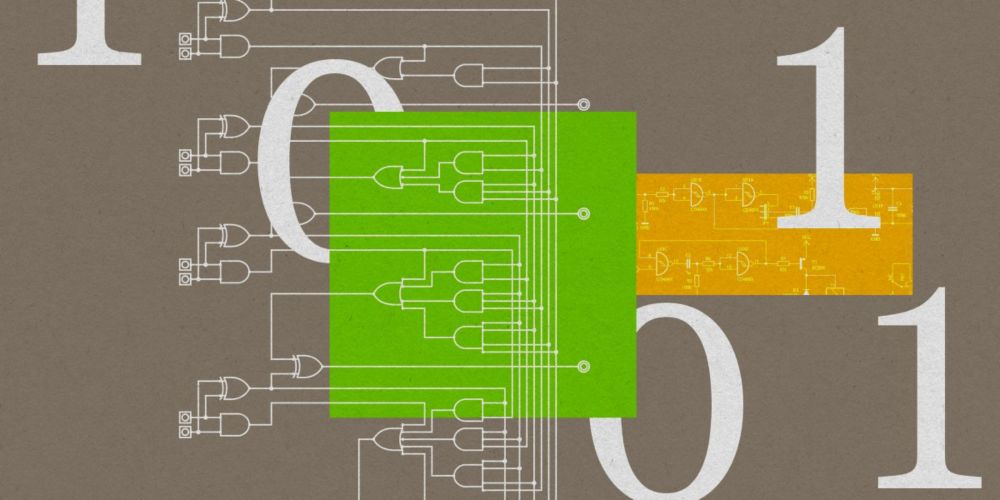
I'm excited to share that our work on Convolutional Differentiable Logic Gate Networks was covered by MIT Technology Review. 🎉
www.technologyreview.com/2024/12/20/1...
@hildekuehne.bsky.social

@petersen.ai.bsky.social
Machine learning researcher @Stanford. https://petersen.ai/
I'm excited to share that our work on Convolutional Differentiable Logic Gate Networks was covered by MIT Technology Review. 🎉
www.technologyreview.com/2024/12/20/1...
@hildekuehne.bsky.social
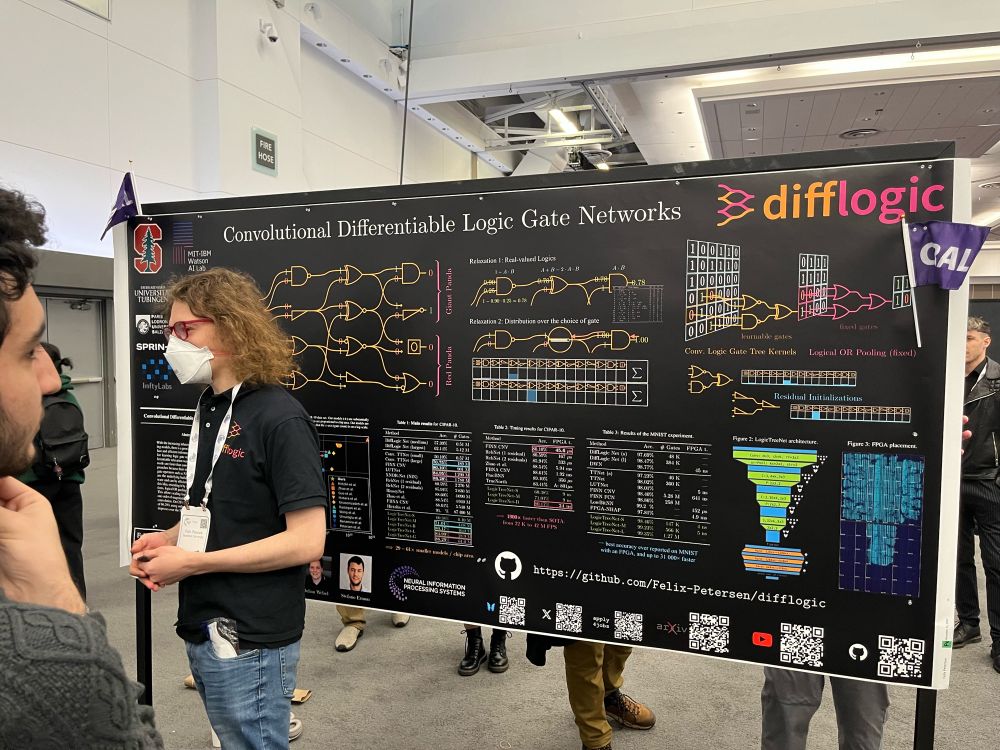
Convolutional Differentiable Logic Gate Networks @FHKPetersen
13.12.2024 20:24 — 👍 45 🔁 3 💬 3 📌 0
Newton Losses: Using Curvature Information for Learning with Differentiable Algorithms @FHKPetersen
12.12.2024 01:23 — 👍 10 🔁 3 💬 1 📌 0Join us at our poster session today, 11am-2pm, at East Exhibit Hall A-C *#1502*.
12.12.2024 18:40 — 👍 1 🔁 0 💬 0 📌 0Most innovative paper at #NeurIPS imho. Can we create a network that becomes the physical chip instead of running on a chip? Inference speedups and energy preservation are through the roof !
Oral on Friday at 10am PT
neurips.cc/virtual/2024...
Join us on Wednesday, 11am-2pm for our poster session on Newton Losses in *West Ballroom A-D #6207*. neurips.cc/virtual/2024...
10.12.2024 19:55 — 👍 0 🔁 0 💬 0 📌 0
Learn more in our paper (arxiv.org/abs/2410.23970) and check out our paper video on YouTube: youtu.be/ZjTAjjxbkRY
04.12.2024 18:39 — 👍 2 🔁 0 💬 0 📌 0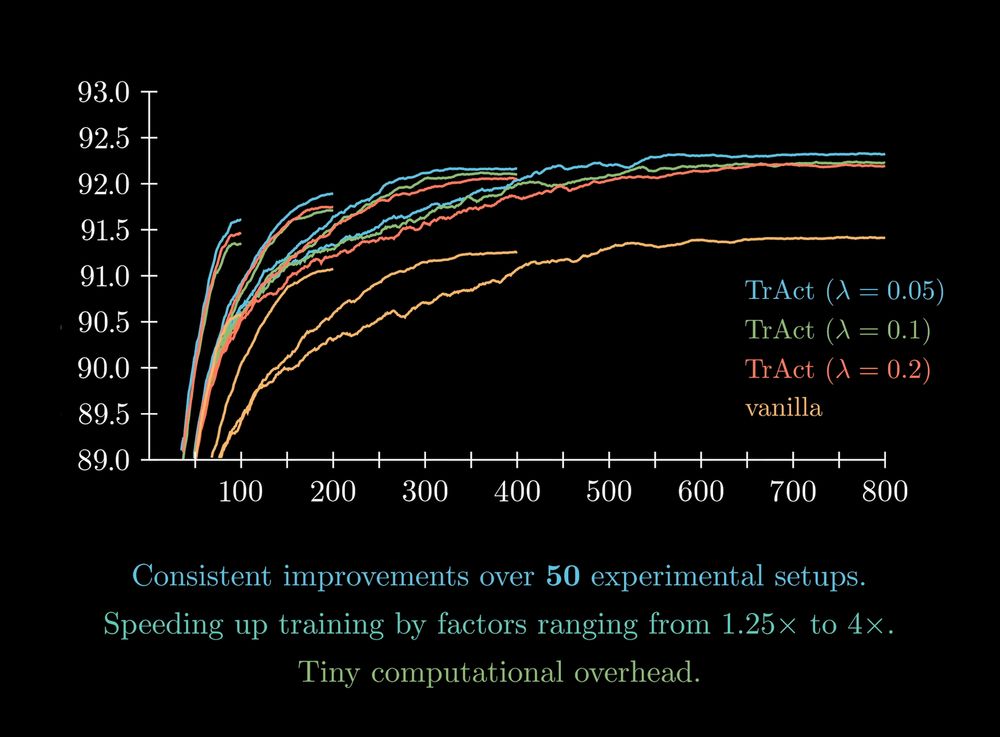
...and it speeds up overall training by factors ranging from 1.25x (for large ViT pre-training) to 4x (for ConvNets).
We benchmark TrAct on a suite of 50 experimental settings.
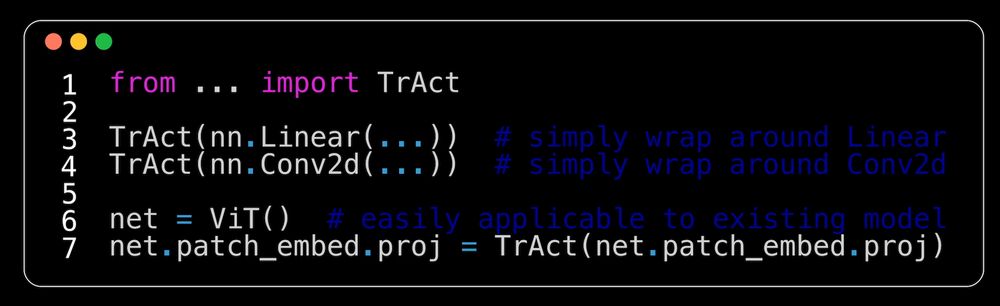
Our implementation is efficient, only modifies the gradient in the backward, and is compatible with various optimizers. To use *TrAct*, just wrap your first layer in a "TrAct" module...
04.12.2024 18:39 — 👍 1 🔁 0 💬 1 📌 0Thus, we can effectively train the first-layer activations of a Vision model, with updates similar to those in the LLM Embedding layer.
04.12.2024 18:39 — 👍 1 🔁 0 💬 1 📌 0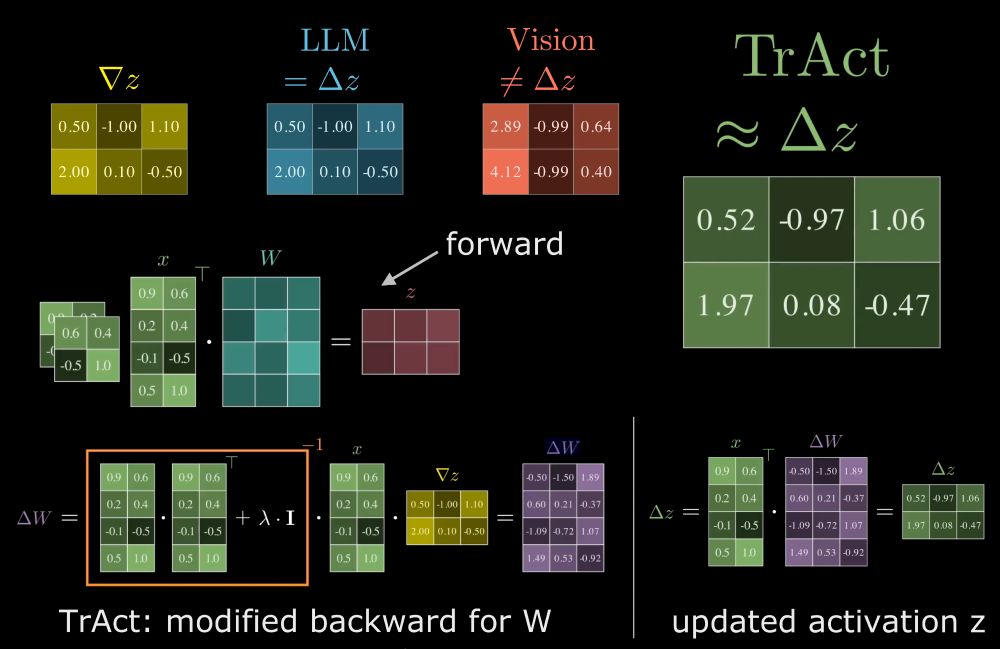
We close this gap by proposing TrAct: we conceptually *Tr*ain *Act*ivations. While we can't train activations directly bc only weights are trainable, we formulate an optimization problem to find the optimal weights to match a GD step on the activations, and in closed-form modify the gradients resp.
04.12.2024 18:39 — 👍 1 🔁 0 💬 1 📌 0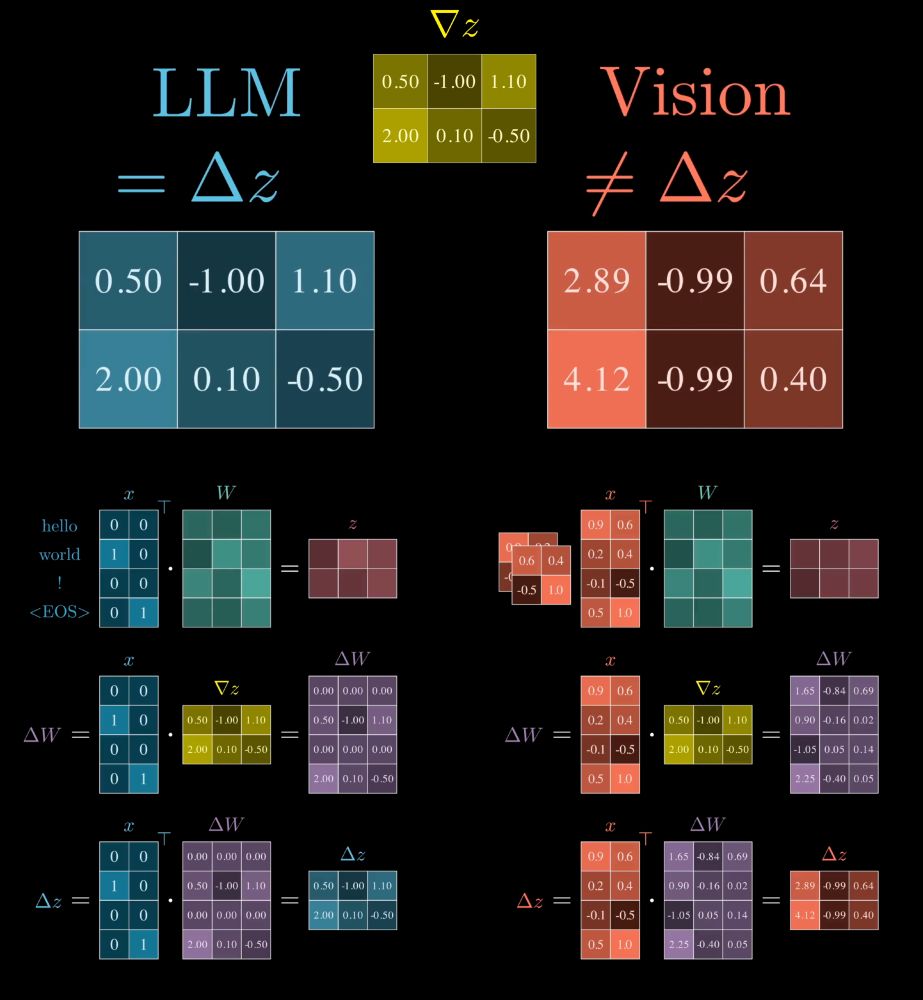
This means that learning of the vision model, at the first layer, is much slower than in LLMs, and that learning is actually faster on higher contrast regions of the image than in low contrast regions due to a proportionality between gradients of weights and input pixel values.
04.12.2024 18:39 — 👍 1 🔁 0 💬 1 📌 0
The big difference between LLMs and Vision models lies in the first layer:
* in LLMs we update Embeddings (/activations) directly
* but in Vision models we update the *weights* of the first layer, which causes indirect updates to the Activations (/embeddings)
Have you ever wondered how training dynamics differ between LLMs 🖋️ and Vision 👁️ models? We explore this and close the gap between VMs and LLMs in our #NeurIPS2024 paper "TrAct: Making First-layer Pre-Activations Trainable".
Paper link 📜: arxiv.org/abs/2410.23970
Video link 🎥: youtu.be/ZjTAjjxbkRY
🧵

Check out our 5 minute paper video on YouTube 🎥: www.youtube.com/watch?v=7aFP...
28.11.2024 01:49 — 👍 2 🔁 0 💬 0 📌 0A big thanks to my co-authors Christian Borgelt, @tobiassutter.bsky.social @hildekuehne.bsky.social Oliver Deussen and Stefano Ermon.
Also a shout-out to the authors of the methods we build on: @qberthet.bsky.social @mblondel.bsky.social @marcocuturi.bsky.social @bachfrancis.bsky.social ky.social
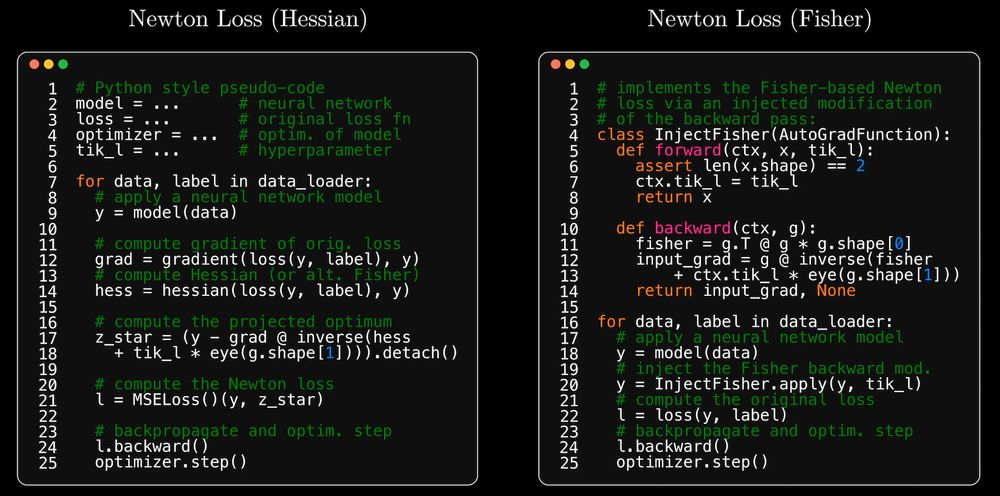
Newton losses is easy to implement, and it's empirical Fisher extension can be added to existing pipelines with a single call of `InjectFisher` between the model and the loss.
28.11.2024 01:49 — 👍 3 🔁 0 💬 1 📌 0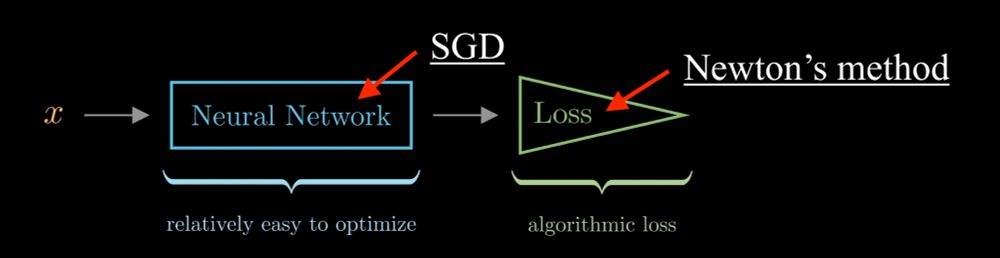
In Newton Losses, we merge SGD training of NNs with a Newton step on the loss. This is crucial for algorithmic losses like ranking and graph losses, esp. w/ vanishing+exploding grads. Intuition: if the loss is harder to optim. than the NN, we should use a stronger optimization method for the loss.
28.11.2024 01:49 — 👍 3 🔁 0 💬 1 📌 0
I'm excited to share our NeurIPS 2024 paper "Newton Losses: Using Curvature Information for Learning with Differentiable Algorithms" 🤖.
Paper link 📜: arxiv.org/abs/2410.19055
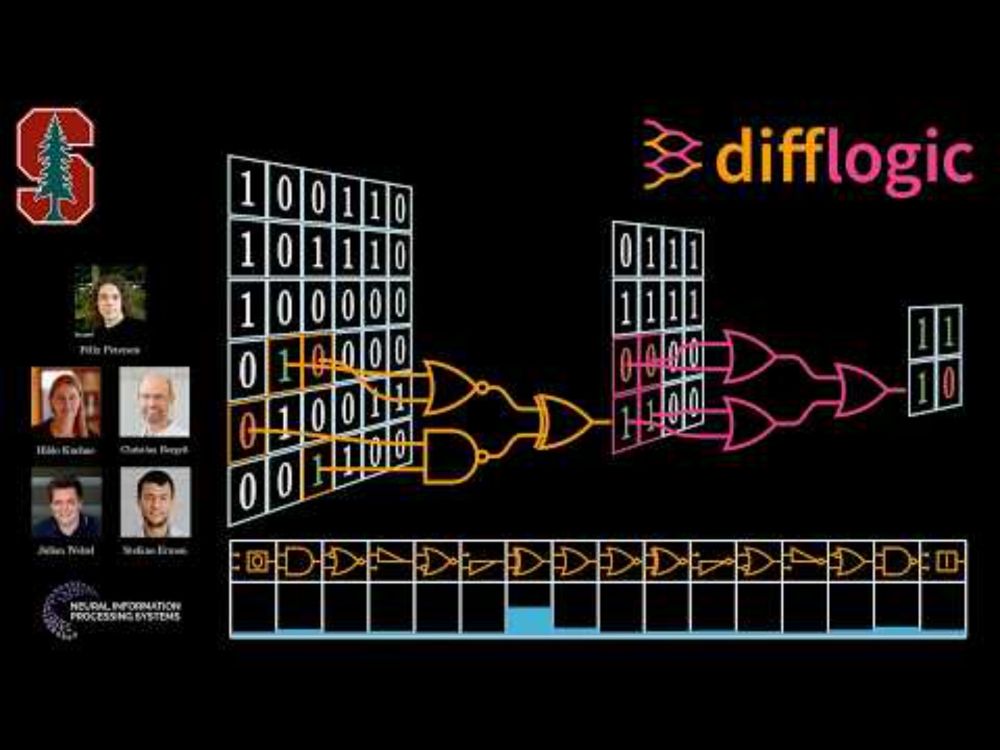
If you're excited about #AI with #logic, check out our fully animated video on YouTube: youtu.be/FKQfMwFZvIE
17.11.2024 16:34 — 👍 20 🔁 3 💬 0 📌 0Excited to share our #NeurIPS 2024 Oral, Convolutional Differentiable Logic Gate Networks, leading to a range of inference efficiency records, including inference in only 4 nanoseconds 🏎️. We reduce model sizes by factors of 29x-61x over the SOTA. Paper: arxiv.org/abs/2411.04732
17.11.2024 16:34 — 👍 102 🔁 18 💬 4 📌 4

















