📣 Please share: We invite submissions to the 29th International Conference on Artificial Intelligence and Statistics (#AISTATS 2026) and welcome paper submissions at the intersection of AI, machine learning, statistics, and related areas. [1/3]
12.08.2025 11:46 — 👍 36 🔁 21 💬 2 📌 2
I'm not on TV yet, but I'm on YouTube 😊 talking about research, ML, how I prepare talks and the difference between Bayesian and frequentist statistics.
Many thanks to Charles Riou who already posted many videos of interviews of ML & stats researchers on his YouTube channel "ML New Papers"!! 🙏
28.04.2025 11:08 — 👍 40 🔁 3 💬 2 📌 0
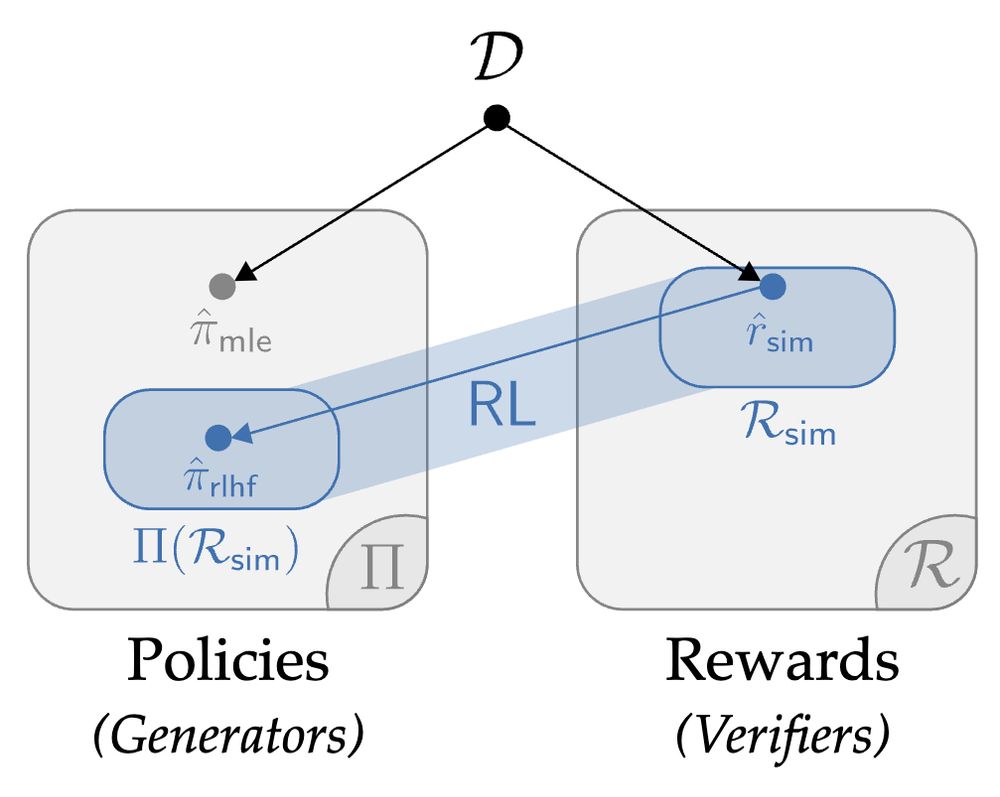
1.5 yrs ago, we set out to answer a seemingly simple question: what are we *actually* getting out of RL in fine-tuning? I'm thrilled to share a pearl we found on the deepest dive of my PhD: the value of RL in RLHF seems to come from *generation-verification gaps*. Get ready to 🤿:
04.03.2025 20:59 — 👍 59 🔁 11 💬 1 📌 3
Am I the only one who feels this is awful? If someone wants to remain anonymous, people should respect that...
18.02.2025 08:51 — 👍 1 🔁 0 💬 1 📌 0
Schrödinger's snack
18.02.2025 08:43 — 👍 3 🔁 0 💬 1 📌 0
yes!
10.02.2025 14:06 — 👍 1 🔁 0 💬 0 📌 0
Modern post-training is essentially distillation then RL. While reward hacking is well-known and feared, could there be such a thing as teacher hacking? Our latest paper confirms it. Fortunately, we also show how to mitigate it! The secret: diversity and onlineness! arxiv.org/abs/2502.02671
08.02.2025 18:06 — 👍 11 🔁 5 💬 0 📌 0
The reason for this is because the usual duality theory still works when working in the spaces of functions and probability measures, while it doesn't if we work in the space of network parameters. We need to apply duality first and then parameterize, not the other way around!
31.01.2025 13:53 — 👍 1 🔁 0 💬 0 📌 0
The EBM paper below parameterizes dual variables as neural nets. This idea (which has been used in other contexts such as OT or GANs) is very powerful and may be *the* way duality can be useful for neural nets (or rather, neural nets can be useful for duality!).
31.01.2025 13:53 — 👍 6 🔁 1 💬 1 📌 0
Surprisingly, we found that we still obtain good performance even if we use the classical softargmax at inference time and our losses at train time. This means that we can keep the inference code the same and just change the training code, which is useful e.g. for open-weight LMs
31.01.2025 12:06 — 👍 1 🔁 0 💬 0 📌 0
We obtain good performance across several language modeling tasks with the alpha-divergence, for alpha=1.5.
31.01.2025 12:06 — 👍 1 🔁 0 💬 1 📌 0

The table below summarizes the link between some entropies and f-divergences.
31.01.2025 12:06 — 👍 0 🔁 0 💬 1 📌 0
2) We instantiate Fenchel-Young losses with f-divergence regularization. This generalizes the cross-entropy loss in two directions: i) by replacing the KL with f-divergences and ii) by allowing non-uniform prior class weights. Each loss is associated with a f-softargmax operator.
31.01.2025 12:06 — 👍 0 🔁 0 💬 1 📌 0
Our approach naturally generalizes to Fenchel-Young losses, allowing us to obtain the first tractable approach for optimizing the sparsemax loss in general combinatorial spaces.
31.01.2025 12:06 — 👍 0 🔁 0 💬 1 📌 0
We propose a new joint formulation for learning the EBM and the log-partition, and a MCMC-free doubly stochastic optimization scheme with unbiased gradients.
31.01.2025 12:06 — 👍 0 🔁 0 💬 1 📌 0
Pushing this idea a little bit further, we can parameterize the log-partition as a separate neural network. This allows us to evaluate the *learned* log-partition on new data points.
31.01.2025 12:06 — 👍 0 🔁 0 💬 1 📌 0
By treating the log-partition not as a quantity to compute but as a variable to optimize, we no longer need it to be exact (in machine learning we never look for exact solutions to optimization problems!).
31.01.2025 12:06 — 👍 0 🔁 0 💬 1 📌 0
1) EBMs are generally challenging to train due to the partition function (normalization constant). At first, learning the partition function seems weird O_o But the log-partition exactly coincides with the Lagrange multiplier (dual variable) associated with equality constraints.
31.01.2025 12:06 — 👍 0 🔁 0 💬 1 📌 0
Really proud of these two companion papers by our team at GDM:
1) Joint Learning of Energy-based Models and their Partition Function
arxiv.org/abs/2501.18528
2) Loss Functions and Operators Generated by f-Divergences
arxiv.org/abs/2501.18537
A thread.
31.01.2025 12:06 — 👍 14 🔁 3 💬 1 📌 1
Sparser, better, faster, stronger
30.01.2025 15:57 — 👍 39 🔁 5 💬 1 📌 0
Former French minister of Education and "philosopher" Luc Ferry, who said a few years ago that maths was useless, wrote a book on artificial intelligence 😂
27.01.2025 11:57 — 👍 9 🔁 0 💬 0 📌 0
Huge congrats!
21.01.2025 12:14 — 👍 0 🔁 0 💬 1 📌 0

We are organising the First International Conference on Probabilistic Numerics (ProbNum 2025) at EURECOM in southern France in Sep 2025. Topics: AI, ML, Stat, Sim, and Numerics. Reposts very much appreciated!
probnum25.github.io
17.11.2024 07:06 — 👍 46 🔁 24 💬 3 📌 7
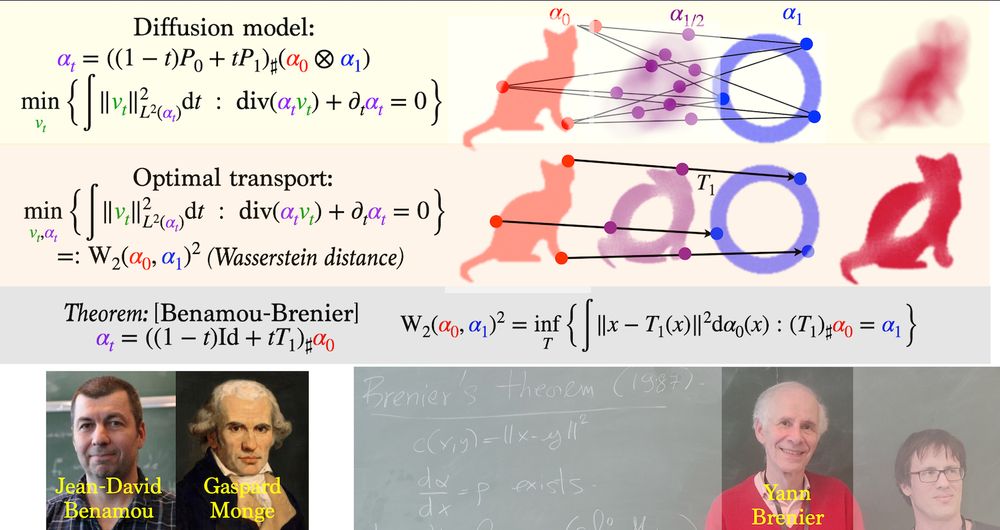
Slides for a general introduction to the use of Optimal Transport methods in learning, with an emphasis on diffusion models, flow matching, training 2 layers neural networks and deep transformers. speakerdeck.com/gpeyre/optim...
15.01.2025 19:08 — 👍 126 🔁 26 💬 4 📌 1
MLSS Senegal 2025
MLSS coming to Senegal !
📍 AIMS Mbour, Senegal
📅 June 23 - July 4, 2025
An international summer school to explore, collaborate, and deepen your understanding of machine learning in a unique and welcoming environment.
Details: mlss-senegal.github.io
12.12.2024 08:45 — 👍 3 🔁 1 💬 0 📌 0
But ensuring that your program supports complex numbers throughout could be a bit tedious.
04.12.2024 17:11 — 👍 1 🔁 0 💬 1 📌 0
4th and 5th of December Sorbonne Center for Artificial Intelligence (SCAI)
Thrilled to be co-organizing NeurIPS in Paris at @sorbonne-universite.fr next week!
📑 100 papers from NeurIPS 2024. Nearly twice as many as in 2023!
🧑🎓 over 300 registered participants
✅ a local and sustainable alternative to flying to Vancouver.
More info: neuripsinparis.github.io/neurips2024p...
27.11.2024 16:09 — 👍 40 🔁 8 💬 2 📌 1
Chief Models Officer @ Stealth Startup; Inria & MVA - Ex: Llama @AIatMeta & Gemini and BYOL @GoogleDeepMind
Co-founder and CEO, Mistral AI
Researcher at Inria Saclay, team Soda
working on machine learning and causal inference for health data
PhD student at MIT; AI for materials. teddykoker.com
NLP/ML researcher in Lisbon
PhD student at @cmurobotics.bsky.social working on efficient algorithms for interactive learning (e.g. imitation / RL / RLHF). no model is an island. prefers email. https://gokul.dev/. on the job market!
Software engineer at Quansight Labs.
Scikit-learn and Sphinx-Gallery dev.
Research Scientist at Google DeepMind. PhD from Inria. RL for LLMs | Gemma
Researcher in statistics and machine learning for genomics
https://laurent-jacob.github.io/
Research Scientist at DeepMind. PhD from Sorbonne Université. Merging and aligning Gemmas.
https://alexrame.github.io/
PhD student at École polytechnique and Université Paris-Saclay 🇫🇷
Reinforcement Learning enjoyer, sometimes even with human feedback
Ex. student-researcher at Google DeepMind Paris
🌐 https://d-tiapkin.github.io/
Researcher in Optimization for ML at Inria Paris. Previously at TU Munich.
https://fabian-sp.github.io/
computers and music are (still) fun
Research scientist at Google DeepMind. Creating noise from data.
Researcher at Criteo. Interested in Bandits, Privacy, Competitive Analysis, Reinforcement Learning.
https://hugorichard.github.io/
Associate Professor@The Institute of Statistical Mathematics, working in ML theory
https://hermite.jp/
Research Scientist at Meta | AI and neural interfaces | Interested in data augmentation, generative models, geometric DL, brain decoding, human pose, …
📍Paris, France 🔗 cedricrommel.github.io
Professor of Computer Vision/Machine Learning at Imagine/LIGM, École nationale des Ponts et Chaussées @ecoledesponts.bsky.social Music & overall happiness 🌳🪻 Born well below 350ppm 😬 mostly silly personal views
📍Paris 🔗 https://davidpicard.github.io/
Research Scientist at Google DeepMind since 2019. Core developer of Gemma models.
PhD IP Paris | Mila | MSc MVA | ENS ULM
linkedin.com/in/thomas-mesnard/