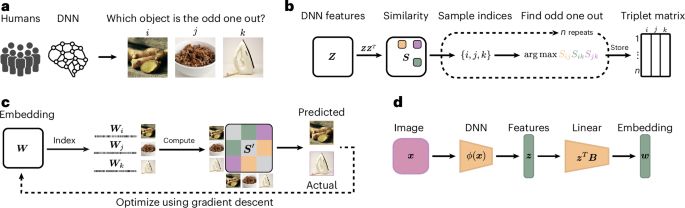
Can models understand each other's reasoning? 🤔
When Model A explains its Chain-of-Thought (CoT) , do Models B, C, and D interpret it the same way?
Our new preprint with @davidbau.bsky.social and @csinva.bsky.social explores CoT generalizability 🧵👇
(1/7)
22.01.2026 21:58 — 👍 25 🔁 7 💬 1 📌 0

Really excited about our new work, which makes building clinical prediction models way easier! AI agents do the grunt work of hypothesizing and validating EHR features, enabling easy auditing by clinicians
Iterating yields sensible SOTA (fully interpretable!) models arxiv.org/abs/2601.09072
20.01.2026 17:13 — 👍 1 🔁 0 💬 0 📌 0

How can an imitative model like an LLM outperform the experts it is trained on? Our new COLM paper outlines three types of transcendence and shows that each one relies on a different aspect of data diversity. arxiv.org/abs/2508.17669
29.08.2025 21:45 — 👍 94 🔁 17 💬 2 📌 5
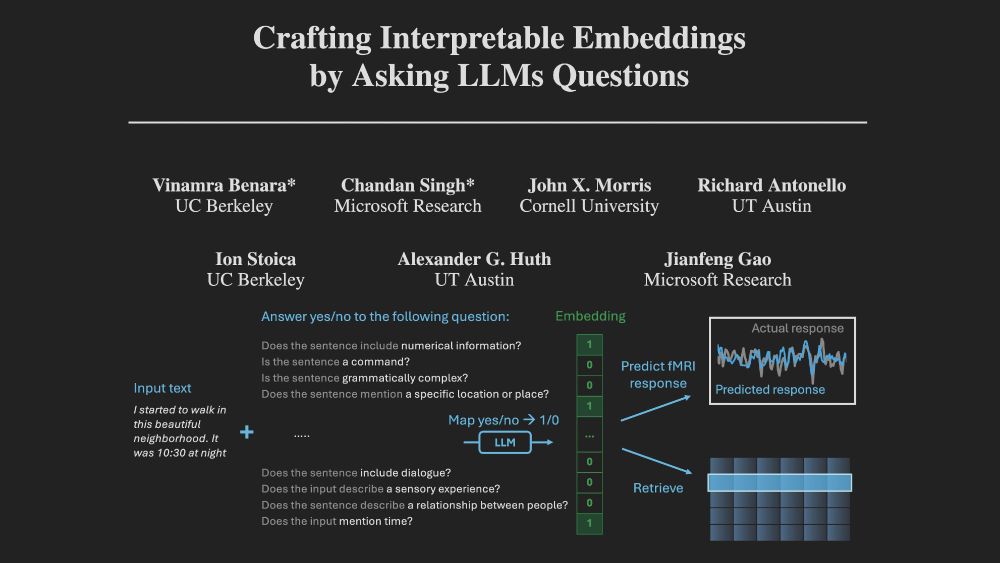
New paper with @rjantonello.bsky.social @csinva.bsky.social, Suna Guo, Gavin Mischler, Jianfeng Gao, & Nima Mesgarani: We use LLMs to generate VERY interpretable embeddings where each dimension corresponds to a scientific theory, & then use these embeddings to predict fMRI and ECoG. It WORKS!
18.08.2025 18:33 — 👍 17 🔁 8 💬 1 📌 0
In our new paper, we explore how we can build encoding models that are both powerful and understandable. Our model uses an LLM to answer 35 questions about a sentence's content. The answers linearly contribute to our prediction of how the brain will respond to that sentence. 1/6
18.08.2025 09:44 — 👍 25 🔁 9 💬 1 📌 1
This was a huge effort with a wonderful team:
@rjantonello.bsky.social (co-first), Suna Guo, Gavin Mischler, Jianfeng Gao, Nima Mesgarani, & @alexanderhuth.bsky.social Excited to see how folks use it!
14.08.2025 14:06 — 👍 0 🔁 0 💬 0 📌 0
These maps largely agree with prior findings (from Neurosynth neurosynth.org) and new findings (from a follow-up fMRI experiment using generative causal testing
arxiv.org/abs/2410.00812), suggesting this method is an effective, *automated* way test new hypotheses!
14.08.2025 14:06 — 👍 0 🔁 0 💬 1 📌 0

The model is small enough that we can visualize the whole thing. No feature importances or post-hoc summaries, just 35 questions and a map showing their linear weights for each brain voxel.
14.08.2025 14:06 — 👍 0 🔁 0 💬 1 📌 0
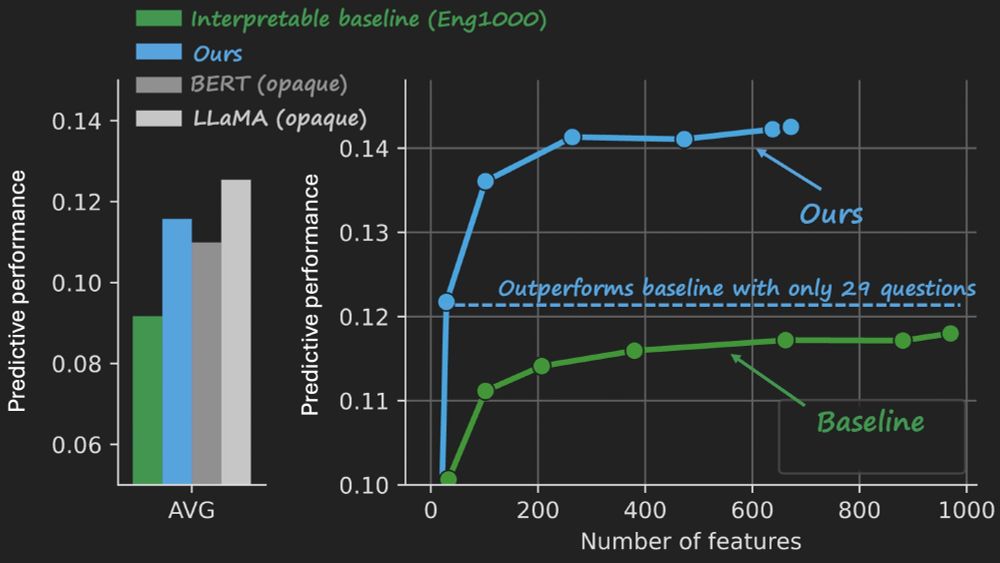
We scale up our prior method that builds interpretable embeddings by asking LLMs yes/no questions. We use bigger LLMs, more data, and stability selection to build a 35-question model that generalizes across subjects and modalities bsky.app/profile/csin...
14.08.2025 14:06 — 👍 0 🔁 0 💬 1 📌 0

New paper: Ask 35 simple questions about sentences in a story and use the answers to predict brain responses. Interpretable, compact, & surprisingly high performance in both fMRI and ECoG. 🧵 biorxiv.org/content/10.1...
14.08.2025 14:06 — 👍 2 🔁 0 💬 1 📌 1
We’ve discovered a literal miracle with almost unlimited potential and it’s being scrapped for *no reason whatsoever*. This isn’t even nihilism, it’s outright worship of death and human suffering.
05.08.2025 23:09 — 👍 10398 🔁 3320 💬 49 📌 158
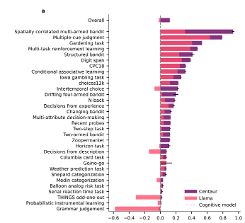
Binz et al. (in press, Nature) developed an LLM called Centaur that better predicts human responses in 159 of 160 behavioural experiments compared to existing cognitive models. See: arxiv.org/abs/2410.20268
26.06.2025 20:29 — 👍 64 🔁 23 💬 3 📌 7
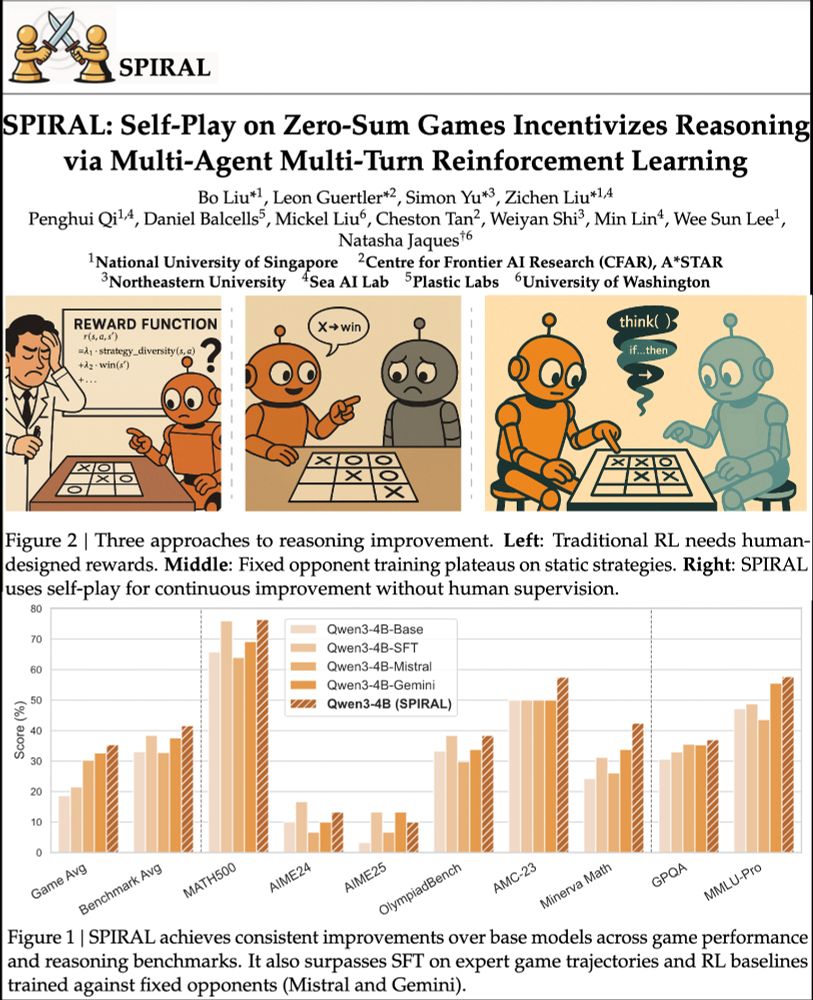
We're excited about self-play unlocking continuously improving agents. RL selects CoT patterns from LLMs. Games=perfect testing grounds.
SPIRAL: models learn via self-competition. Kuhn Poker → +8.7% math, +18.1 Minerva Math! 🃏
Paper: huggingface.co/papers/2506....
Code: github.com/spiral-rl/spiral
01.07.2025 20:11 — 👍 17 🔁 5 💬 2 📌 1
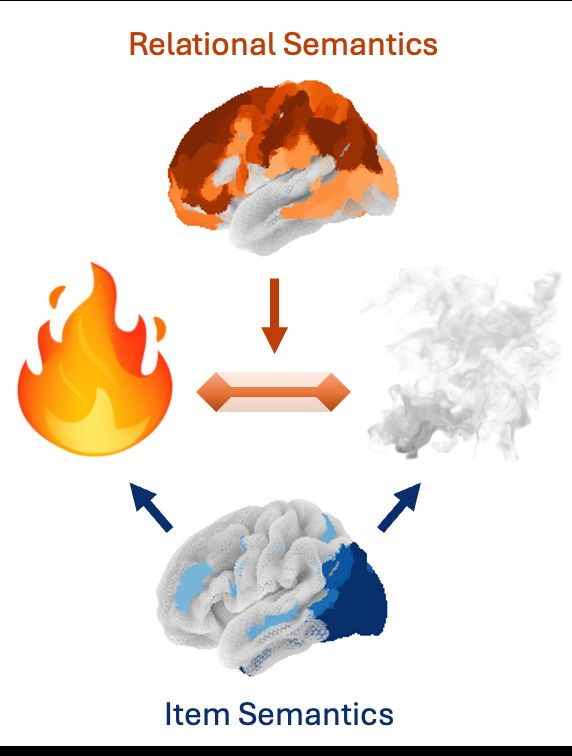
🚨 New preprint 🚨
Prior work has mapped how the brain encodes concepts: If you see fire and smoke, your brain will represent the fire (hot, bright) and smoke (gray, airy). But how do you encode features of the fire-smoke relation? We analyzed fMRI with embeddings extracted from LLMs to find out 🧵
24.06.2025 13:49 — 👍 32 🔁 8 💬 1 📌 2
Cortex Feature Visualization
🚨Paper alert!🚨
TL;DR first: We used a pre-trained deep neural network to model fMRI data and to generate images predicted to elicit a large response for each many different parts of the brain. We aggregate these into an awesome interactive brain viewer: piecesofmind.psyc.unr.edu/activation_m...
12.06.2025 16:33 — 👍 11 🔁 6 💬 2 📌 0
What are the organizing dimensions of language processing?
We show that voxel responses during comprehension are organized along 2 main axes: processing difficulty & meaning abstractness—revealing an interpretable, topographic representational basis for language processing shared across individuals
23.05.2025 16:59 — 👍 71 🔁 30 💬 3 📌 0
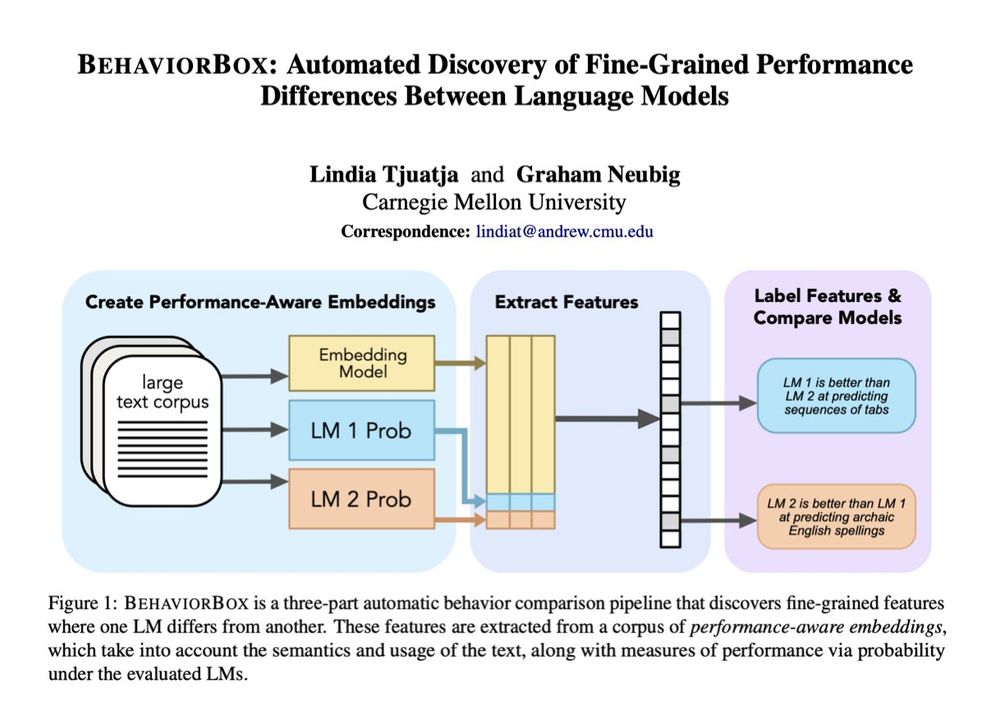
When it comes to text prediction, where does one LM outperform another? If you've ever worked on LM evals, you know this question is a lot more complex than it seems. In our new #acl2025 paper, we developed a method to find fine-grained differences between LMs:
🧵1/9
09.06.2025 13:47 — 👍 72 🔁 21 💬 2 📌 2
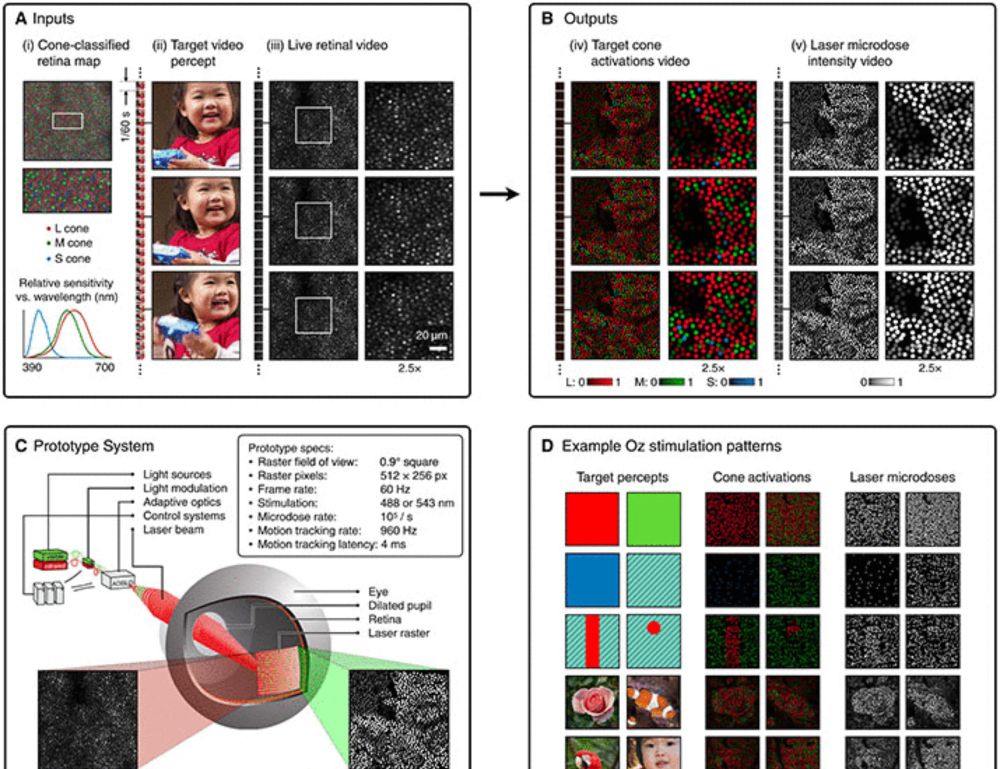
Novel color via stimulation of individual photoreceptors at population scale
Image display by cell-by-cell retina stimulation, enabling colors impossible to see under natural viewing.
Five people have seen a color never before visible to the naked human eye, thanks to a new retinal stimulation technique called Oz.
Learn more in #ScienceAdvances: scim.ag/442Hjn6
21.04.2025 17:56 — 👍 73 🔁 11 💬 4 📌 6
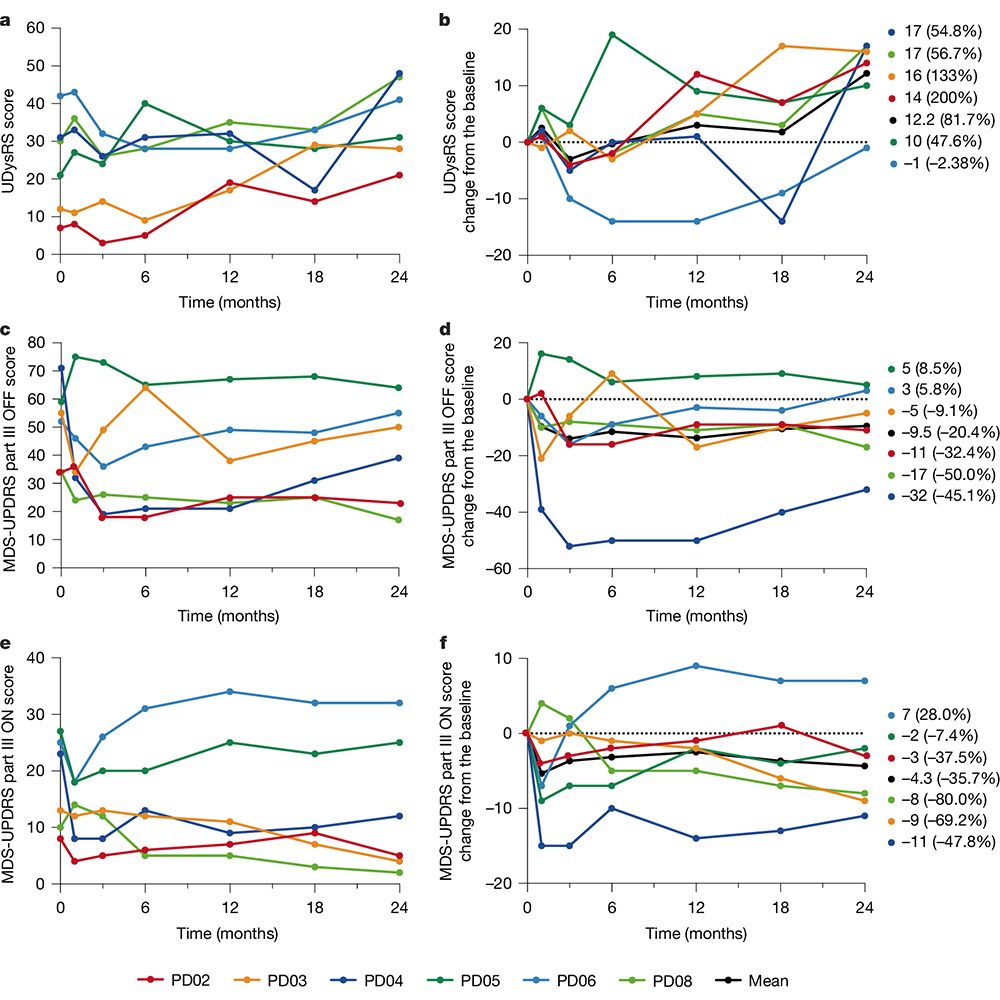
This is figure 2 from “Phase I/II trial of iPS-cell-derived dopaminergic cells for Parkinson’s disease,” which shows chronological changes in clinical end points.
Two clinical trials reported in Nature demonstrate the safety of stem cell therapies for Parkinson’s disease. The papers investigate the use of cells derived from human induced pluripotent stem cells and human embryonic stem cells. go.nature.com/4ikcJc2
go.nature.com/4jfSRYX 🧪
16.04.2025 22:18 — 👍 42 🔁 9 💬 0 📌 0

Accelerated learning of a noninvasive human brain-computer interface via manifold geometry
Brain-computer interfaces (BCIs) promise to restore and enhance a wide range of human capabilities. However, a barrier to the adoption of BCIs is how long it can take users to learn to control them. W...
New preprint! Excited to share our latest work “Accelerated learning of a noninvasive human brain-computer interface via manifold geometry” ft. outstanding former undergraduate Chandra Fincke, @glajoie.bsky.social, @krishnaswamylab.bsky.social, and @wutsaiyale.bsky.social's Nick Turk-Browne 1/8
03.04.2025 23:04 — 👍 66 🔁 20 💬 2 📌 3

New preprint “Monkey See, Model Knew: LLMs accurately predict visual responses in humans AND NHPs”
Led by Colin Conwell with @emaliemcmahon.bsky.social Akshay Jagadeesh, Kasper Vinken @amrahs-inolas.bsky.social @jacob-prince.bsky.social George Alvarez @taliakonkle.bsky.social & Marge Livingstone 1/n
14.03.2025 16:14 — 👍 50 🔁 19 💬 1 📌 0

Sanity Checks for Saliency Maps
Julius Adebayo, Justin Gilmer, Michael Muelly, Ian Goodfellow, Moritz Hardt, Been Kim
Saliency methods have emerged as a popular tool to highlight features in an input deemed relevant for the prediction of a learned model. Several saliency methods have been proposed, often guided by visual appeal on image data. In this work, we propose an actionable methodology to evaluate what kinds of explanations a given method can and cannot provide. We find that reliance, solely, on visual assessment can be misleading. Through extensive experiments we show that some existing saliency methods are independent both of the model and of the data generating process. Consequently, methods that fail the proposed tests are inadequate for tasks that are sensitive to either data or model, such as, finding outliers in the data, explaining the relationship between inputs and outputs that the model learned, and debugging the model. We interpret our findings through an analogy with edge detection in images, a technique that requires neither training data nor model. Theory in the case of a linear model and a single-layer convolutional neural network supports our experimental findings.

Sparse Autoencoders Can Interpret Randomly Initialized Transformers
Thomas Heap, Tim Lawson, Lucy Farnik, Laurence Aitchison
Sparse autoencoders (SAEs) are an increasingly popular technique for interpreting the internal representations of transformers. In this paper, we apply SAEs to 'interpret' random transformers, i.e., transformers where the parameters are sampled IID from a Gaussian rather than trained on text data. We find that random and trained transformers produce similarly interpretable SAE latents, and we confirm this finding quantitatively using an open-source auto-interpretability pipeline. Further, we find that SAE quality metrics are broadly similar for random and trained transformers. We find that these results hold across model sizes and layers. We discuss a number of number interesting questions that this work raises for the use of SAEs and auto-interpretability in the context of mechanistic interpretability.
2018: Saliency maps give plausible interpretations of random weights, triggering skepticism and catalyzing the mechinterp cultural movement, which now advocates for SAEs.
2025: SAEs give plausible interpretations of random weights, triggering skepticism and ...
03.03.2025 18:42 — 👍 95 🔁 15 💬 2 📌 0
Yi Ma & colleagues managed to simplify DINO & DINOv2 by removing many ingredients and adding a robust regularization term from information theory (coding rate) that learn informative decorrelated features. Happy to see principled approaches advance deep representation learning!
18.02.2025 14:24 — 👍 7 🔁 3 💬 1 📌 0

Can LLMs be used to discover interpretable models of human and animal behavior?🤔
Turns out: yes!
Thrilled to share our latest preprint where we used FunSearch to automatically discover symbolic cognitive models of behavior.
1/12
10.02.2025 12:21 — 👍 134 🔁 44 💬 3 📌 11

"...responses of V4 neurons under naturalistic conditions can be explained by a hierarchical three-stage model where each stage consists entirely of units like those found in area V1"
#NeuroAI
www.biorxiv.org/content/10.1...
24.12.2024 08:55 — 👍 39 🔁 16 💬 0 📌 1
Hi, could you possibly add me? Thanks!
08.12.2024 22:57 — 👍 2 🔁 0 💬 1 📌 0
At NeurIPS this week, presenting our work on crafting *interpretable embeddings* by asking yes/no questions to black-box LLMs.
Drop me a message if you want to chat about interpretability/language neuroscience!
07.12.2024 15:05 — 👍 7 🔁 0 💬 0 📌 1
I tried to find everyone who works in the area but I certainly missed some folks so please lmk...
go.bsky.app/BYkRryU
23.11.2024 05:11 — 👍 53 🔁 18 💬 32 📌 0
Postdoc at Stanford | Developmental NeuroAI
CS Ph.D. Candidate @ Northeastern | Interpretability + Data Science | BS/MS @ Brown
koyenapal.github.io
Postdoc @ Princeton AI Lab
Natural and Artificial Minds
Prev: PhD @ Brown, MIT FutureTech
Website: https://annatsv.github.io/
Researcher in computational neuroscience and neuromorphic computing || http://wchapmaniv.com ||
Partner Research Manager at Microsoft Research NYC. AI, Economics, Decision Science.
https://jessyli.com Associate Professor, UT Austin Linguistics.
Part of UT Computational Linguistics https://sites.utexas.edu/compling/ and UT NLP https://www.nlp.utexas.edu/
CS PhD Student @ Northeastern, former ugrad @ UW, UWNLP --
https://millicentli.github.io/
CS PhD student at UT Austin in #NLP
Interested in language, reasoning, semantics and cognitive science. One day we'll have more efficient, interpretable and robust models!
Other interests: math, philosophy, cinema
https://www.juandiego-rodriguez.com/
PhD Student @ Mesgarani Lab, Columbia University
Neuroscience+ML+Language
https://linyanghe.github.io/
She/her. Neuroscience PhD student @UC Berkeley. Formerly @UT Austin, Haverford College. https://mujn1461.github.io/jianingmu/
Cognitive computational neuroscience, machine learning, psychophysics & consciousness.
Currently Professor at Freie Universität Berlin, also affiliated with the Bernstein Center for Computational Neuroscience.
Reinforcement Learning PhD @NUSingapore | Undergrad @PKU1898 | Building autonomous decision making systems | Ex intern @MSFTResearch @deepseek_ai | DeepSeek-V2, DeepSeek-VL, DeepSeek-Prover
I have a website: https://pbogdan.com/
PhD student in Interpretable Machine Learning at @tuberlin.bsky.social & @bifold.berlin
https://web.ml.tu-berlin.de/author/laura-kopf/
Computational cognitive neuroscientist at University of Nevada, Reno. Uses fMRI to study visual representations of objects, scenes, and bodies, and how attention affects them. Dad. Nerd since before it was cool. Likes pretty science pictures & puns. He/him
a natural language processor and “sensible linguist”. PhD-ing LTI@CMU, previously BS-ing Ling+ECE@UTAustin
🤠🤖📖 she/her
lindiatjuatja.github.io
Senior Lecturer (Associate Professor) in Natural Language Processing, Queen's University Belfast. NLProc • Cognitive Science • Semantics • Health Analytics.
assistant prof at USC Data Sciences and Operations and Computer Science; phd Cornell ORIE.
data-driven decision-making, operations research/management, causal inference, algorithmic fairness/equity
bureaucratic justice warrior
angelamzhou.github.io